第一讲 社会科学统计软件导论
Last updated: Sep 11, 2025
课前说明
1. 为何选择IBM SPSS?
- SPSS是一款历史悠久、发展成熟的统计软件。在图形化操作系统出现之前,SPSS已经为早期计算机用户提供统计分析。
- SPSS的算法通过了美国国家标准技术研究所(NIST)的严格检验,确保了计算结果的准确性。同时,它也是美国食品药品监督管理局(FDA)等权威机构认可的分析工具之一,在学术界和工业界都享有很高的信誉。
- 相较于纯代码驱动的统计语言,SPSS的语法(Syntax)被设计为更贴近自然语言,具有很高的可读性和可解释性,对初学者非常友好。
- SPSS不仅内置了绝大多数社会科学研究所需的统计模型,还支持与Python、R等现代编程语言进行深度集成。通过其开发者模块,用户可以不断拓展SPSS的功能,实现更复杂的定制化分析。
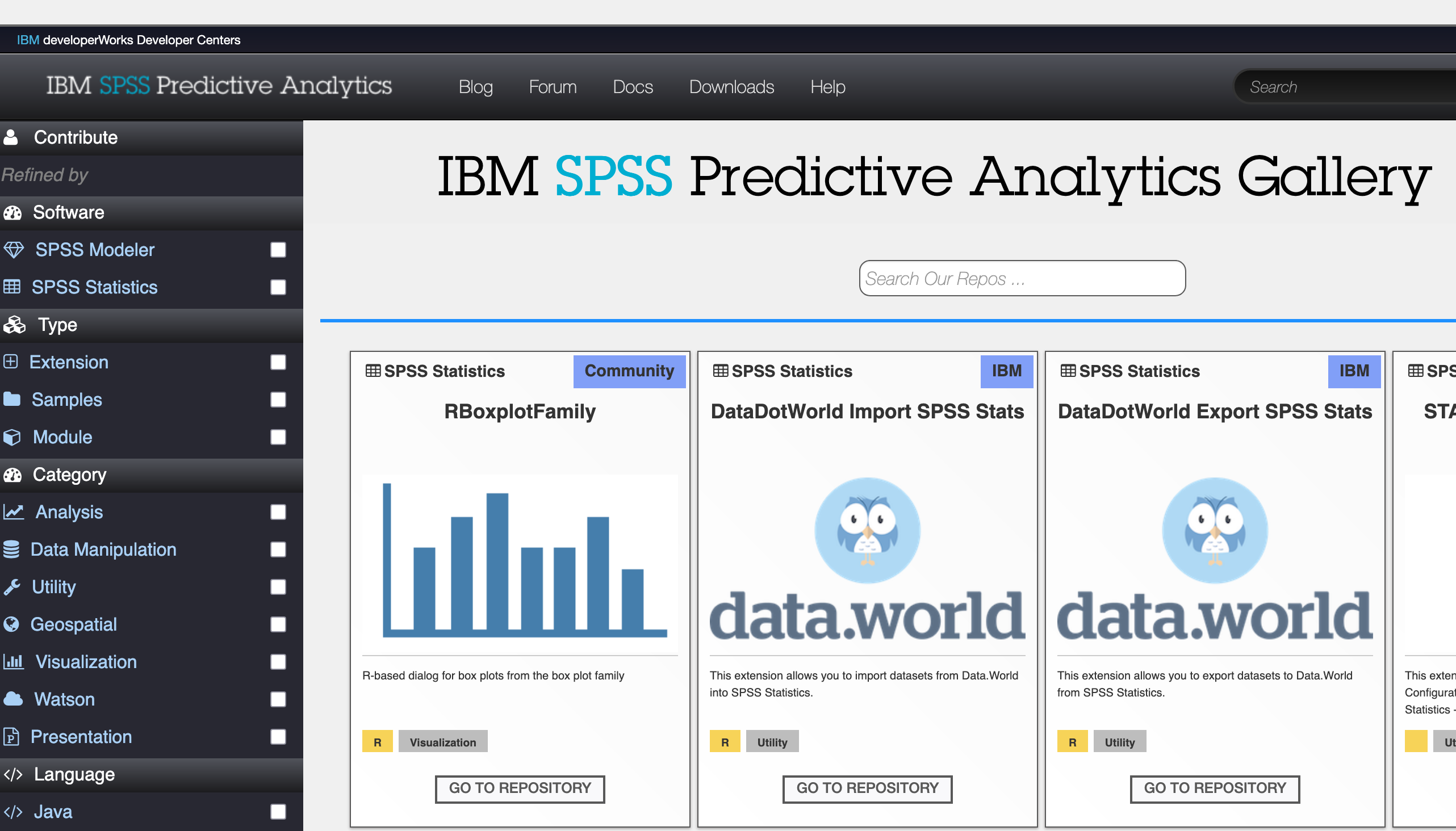
辅助知识点:SPSS的前世今生及其在众多统计软件中的定位
在2018年,一群SPSS的忠实用户为了庆祝其诞生50周年,创建了一个纪念网站(该网站已经失效,更多内容参见SPSS社区Blog“SPSS: 50 Years of Innovation“)。
网站首页的一段话揭示了一个重要的历史事实:
“SPSS was initially developed and implemented a long time ago in the dark ages of computing, before we had discovered the ability to point and click. In those days, the only way to communicate with SPSS was to type in commands and parameters using the SPSS Syntax language. Since then, SPSS has come a long way.”
“SPSS最初是在计算机发展的黑暗时代开发并实施的,那时我们还没有发现点击操作的能力。在那些日子里,与SPSS沟通的唯一方式是使用SPSS语法语言输入命令和参数。从那时起,SPSS已经走过了漫长的道路。”
简单来说就是:语法(Syntax)并非点选操作的附属品,恰恰相反,它才是SPSS最原始、最核心的“灵魂”。我们今天所做的每一次点选操作,其背后都是SPSS在替我们自动生成并执行了一段对应的语法。因此,学习语法,实际上是在学习直接与SPSS的核心进行对话,这能让我们更深刻地理解其工作原理,并发挥出其全部的潜力。
在当今数据科学领域,除了SPSS,我们还经常听到R、Python、Stata等软件。它们各有千秋,适用于不同的场景。
- R/Python:完全基于代码的开源语言,灵活性和功能扩展性最强,尤其在机器学习、数据可视化和前沿算法实现上占有绝对优势。但学习曲线也最为陡峭。
- Stata:在社会学、经济学和政治学等领域非常流行,其语法简洁高效,执行效率极高,并拥有基数庞大的用户社区。
对于初学者而言,从SPSS入手,学习如何用编程语法实现统计想法,是一个非常理想的起点。
2. 在“点选操作”和“语法操作”间如何选择?
-
对于初学者或进行探索性分析时,“点选操作”直观、快捷,能帮助我们迅速了解数据。能高效解决问题的操作就是好操作。
-
语法操作的独特优势
(1)可复现性 (Replicability):这是科学研究的生命线。一份保存完好的语法文件(
.sps文件)就是一份完整的“分析日志”,它精确记录了从数据导入到最终结果的每一步。任何时候,任何人(包括未来的你自己)都可以通过运行这份文件,完美复现你的整个分析过程,确保了研究的透明和可靠。(2)效率 (Efficiency):当需要对几十个甚至上百个变量进行同样的操作时,点选操作会变得极其繁琐和容易出错。而语法只需编写一次,即可批量应用,大大提高工作效率。
(3)高级功能 (Advanced Functions):SPSS中有些高级功能,特别是调用Python或R的开发者模块(developer modules),是无法通过点选操作实现的,必须依赖语法。
3. 如何高效学习和使用语法操作?
- 首先熟练掌握少数核心常用语法命令(如数据管理、描述统计、T检验、方差分析、相关、回归等),其他成百上千的非常用的语法命令,知道在需要时如何查询即可。IBM官方的命令语法参考手册长达2454页,记忆它是不现实也没必要的。
- 利用官方在线语法文档进行站内检索,如IBM SPSS Command Syntax Reference 是最权威的查询手册。
- 巧用搜索引擎,使用
spss syntax [你想进行的分析]的模式进行搜索。例如:spss syntax regression。 - 善用AI工具,获得特定需求的语法代码和解释。
- 一些有用的在线资源:
4. 如何养成良好的研究习惯?
- 为每个项目创建语法文件。每次分析都新建一个语法文件(
.sps)并保存,即使是最简单的操作。这应成为一种肌肉记忆。 - 多写注释。在语法文件中,使用
* 这是一个注释.或者/* 这是一个注释 */来解释你的分析思路、操作目的或关键步骤。好的注释是写给一个月后的自己,以及你的合作者看的。 - 使用专业的文本编辑器。虽然SPSS自带的语法编辑器够用,但像 Sublime Text 或 Notepad++ 这类编辑器,在安装了SPSS语法高亮插件后,能提供更舒适的代码阅读和编写体验。
- 建立规范的文件夹结构。为一个研究项目建立清晰的文件夹,例如:
01_Data(存放原始数据),02_Syntax(存放sps文件),03_Output(存放输出结果),04_Paper(存放报告和论文)。
5. SPSS的基本操作界面
- SPSS主要由三个核心窗口构成
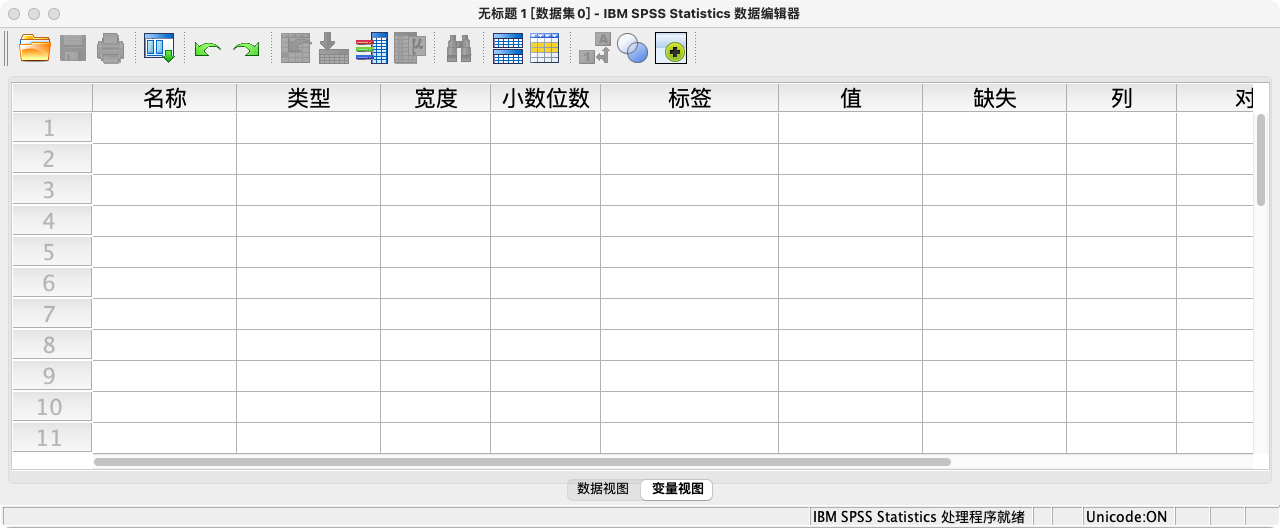
(1)数据编辑器 (Data Editor),这是处理和查看数据的工作台。
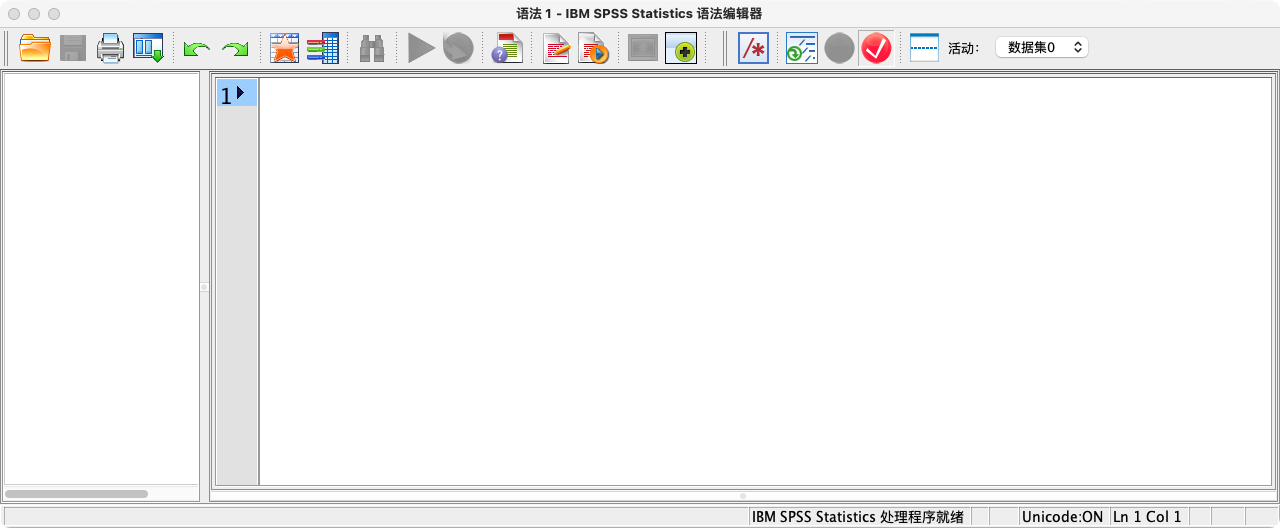
(2)语法编辑器 (Syntax Editor),这是编写和执行命令的控制台。
(3)输出查看器 (Output Viewer):这是展示所有分析结果和操作日志的窗口。
- 其中,数据编辑器本身又分为两个相互关联的视图
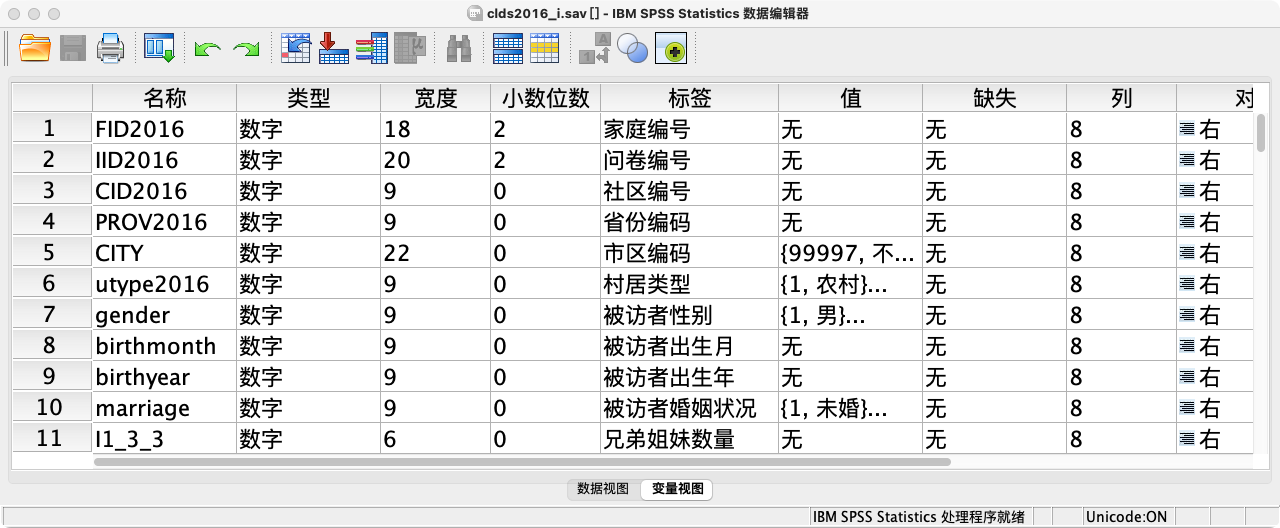
- 变量视图 (Variable View)
- 功能:这里是定义变量属性的地方,相当于问卷的“设计蓝图”。
- 结构:每一行代表一个变量(如“性别”、“年龄”、“收入”),每一列是这个变量的一个属性(如名称、类型、标签、值标签、测量级别等)。
- 例如:一个有10个问题的问卷,在变量视图中就至少有10行。
- 数据视图 (Data View)
- 功能:这里是录入和查看具体数据的地方,相当于一叠“填写好的问卷”。
- 结构:每一行代表一个个案(Case),通常是一个受访者。每一列代表一个变量。单元格里就是每个受访者在每个问题上的具体回答。
- 例如:一份调查了10个受访者的问卷,在数据视图中就有10行。

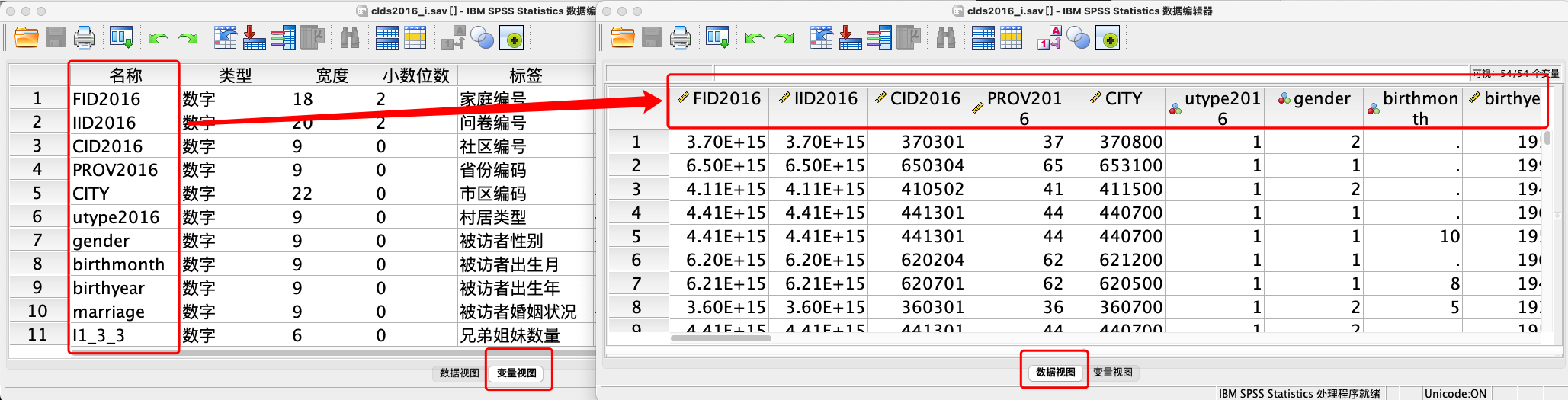
- 变量视图与数据视图的对应关系
- 变量视图中的一行,就是数据视图中的一列。你在变量视图中定义好了一个变量(一行),它就会立刻作为新的一列出现在数据视图中,等待录入数据。反之亦然。
6. 课程随堂练习数据
Disqus comments are disabled.