第二讲 问卷编码与数据录入(一)
Last updated: Sep 18, 2025
1. 新建语法(syntax)
- 快捷键操作:
Alt+F+N+S(Windows) - 点选操作: 文件 → 新建 → 语法
辅助知识点:什么是SPSS语法? SPSS语法是SPSS软件内置的命令语言。相较于通过鼠标点击菜单完成操作,使用语法具有更高的效率、可重复性和准确性。一次编写,即可反复执行,尤其适用于批量处理数据、构建复杂模型或记录分析过程的场景。一份清晰的语法文件本身就是一份完整的“数据分析日志”。
2. 语法的操作注意事项
- 执行语法可以通过两种方式
- 快捷键操作: 在语法编辑器中,选中待执行的语法行 → 按下
Ctrl+R - 点选操作: 在语法编辑器中,选中待执行的语法行 → 点击工具栏的“运行选定项”按钮(绿色实心三角键)
- 快捷键操作: 在语法编辑器中,选中待执行的语法行 → 按下
- 半角字符:语法中的所有符号,如括号
()、引号""、等号=、斜杠/和最后的休止符.,都必须在英文输入法状态下输入(即半角字符)。这是初学者最常遇到的错误之一。 - 基本结构:一项完整的语法通常由命令 (Command)、子命令 (Subcommand)、关键字 (Keyword) 和 参数 (Argument) 构成,并以一个休止符(End)
.结束,表示该命令的终结。 - 大小写规则:SPSS语法不区分大小写。例如,
get file、Get File或GET FILE的效果完全相同。然而,为了保持代码的清晰和可读性,通常推荐将命令、子命令等固定部分大写或小写,并保持全文风格统一。 - 注释 (Comment):为了便于自己和他人理解语法的功能,我们可以添加注释。注释内容不会被当作命令执行。SPSS支持两种注释方式:
- 方式一:以
*开始,以休止符.结束。 - 方式二:以
/*开始,以*/结束。这种方式更灵活,可以用于命令内的注释。
- 方式一:以
* 这是一条完整的注释,用于执行回归分析.
/* 这也是一条注释 */
- 注意:
- 使用
* XXXX .和/* ... */方式进行注释时,注释内容内部不可以包含空白行,否则SPSS会将空白行以下的文字识别为新的命令,从而导致报错。 - 使用
/* ... */方式进行注释时,注释必须出现在完整的语法单元之后,不能中断正在进行的语法单元,否则会报错。 - 允许
/* ... */使用的行内注释方式
- 使用
*正确案例1.
CD /* ... */
"/Users/ginglam/Public/data".
*正确案例2.
REGRESSION /*回归分析主命令*/
/STATISTICS COEFF CI(95) R ANOVA /*设置输出统计量,包含回归系数、执行区间、R值、方差分析结果*/
/DEPENDENT log_income /*设置因变量*/
/METHOD = ENTER edu_year /*设置模型1自变量*/
/METHOD = ENTER age /*设置模型2自变量*/.
*错误案例.
REGRESSION /* 注释 */ /DEPENDENT var // 中断命令流
/METHOD = /* 注释 */ ENTER var // 中断子命令结构
/DEPENDENT var1 /* 注释 */ var2 // 中断参数列表
- 代码缩进 (Indent):对于包含多个子命令的复杂语法,建议从第二行开始进行缩进(通常使用
Tab键),这样可以使代码结构更清晰,层次分明,易于阅读和排错。
* 一个缩进良好的例子.
GET DATA
/TYPE = XLS
/FILE = "auto.xls"
/SHEET = NAME "domestic".
- 命名规范:在为数据集、变量等命名时,名称内部不可包含空格。如果由多个单词组成,建议使用下划线
_连接,例如working_time。
案例(2-1):为输出结果窗口添加标题
以下语法会给接下来生成的“查看器”(结果输出窗口)添加一个标题“clds”,方便识别。
TITLE "clds".
- 在结果窗口中显示或隐藏所执行的语法代码
* 不在结果中显示语法(让结果窗口更简洁).
SET PRINTBACK = OFF.
* 在结果中显示语法(便于核对分析过程).
SET PRINTBACK = ON.
3. 设置工作目录 (Working Directory)
- 设置工作目录 (Working Directory) 可以为SPSS指定一个默认的文件夹路径。这样做的好处是,在后续读取或保存文件时,只需提供文件名,而无需重复输入完整的长路径,从而大大简化操作。
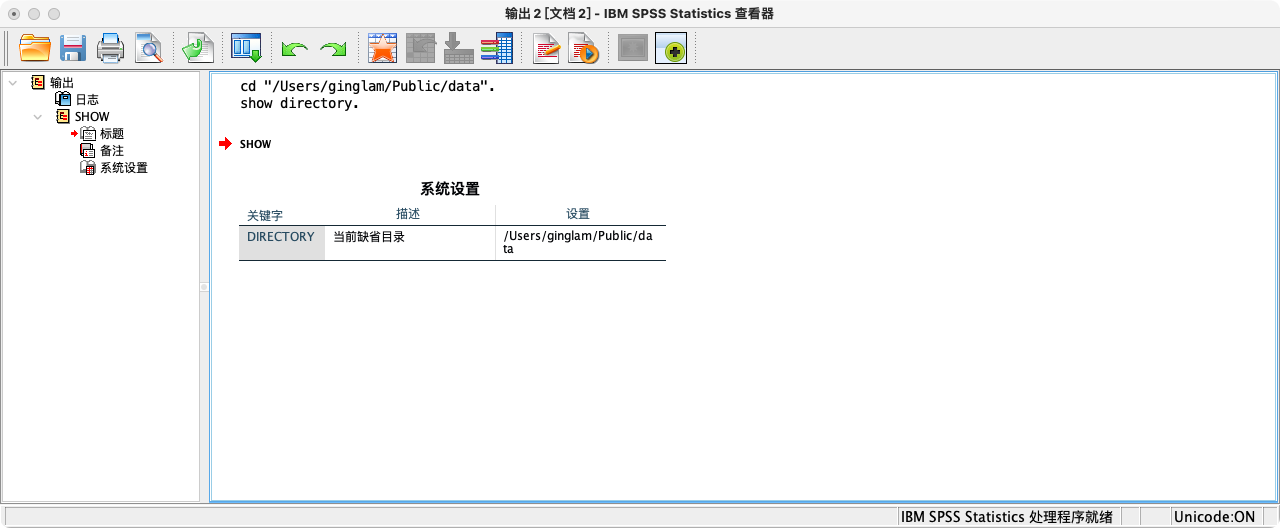
案例(3-1):设置工作目录为“/Users/ginglam/Public/data”
CD "/Users/ginglam/Public/data".
- 显示当前设定的工作目录路径,以确认设置是否成功。
SHOW DIRECTORY.
4. 创建新数据集 (Dataset)
- 点选操作: 文件 → 新建 → 数据
- 语法操作: 使用
NEW FILE.命令可以创建一个空白的数据集,相当于一张空的表格。
NEW FILE.
5. 读取已有数据集
- 点选操作: 文件 → 打开 → 数据 → 在电脑中选择相应文件
- 语法操作: 使用
GET系列命令,可以导入多种格式的数据。如果已设置工作目录,且文件就在该目录中,则路径部分可以省略,只需文件名即可。 - 读取SPSS格式 (.sav)
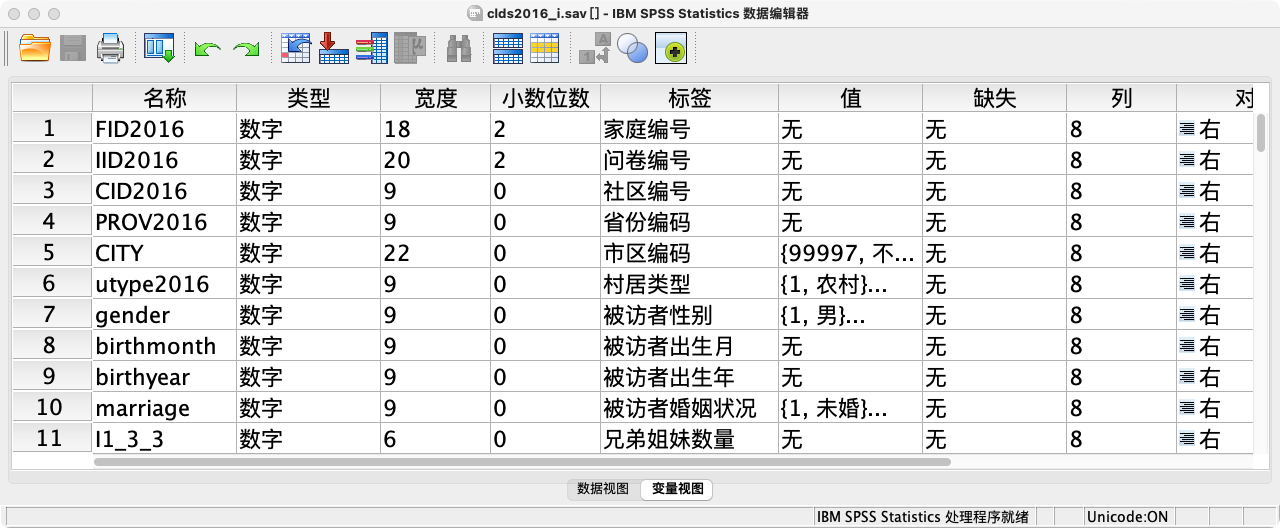
案例(5-1):读取名为"clds2016_i"的SPSS数据
GET FILE "clds2016_i.sav".
- 读取Stata格式 (.dta)
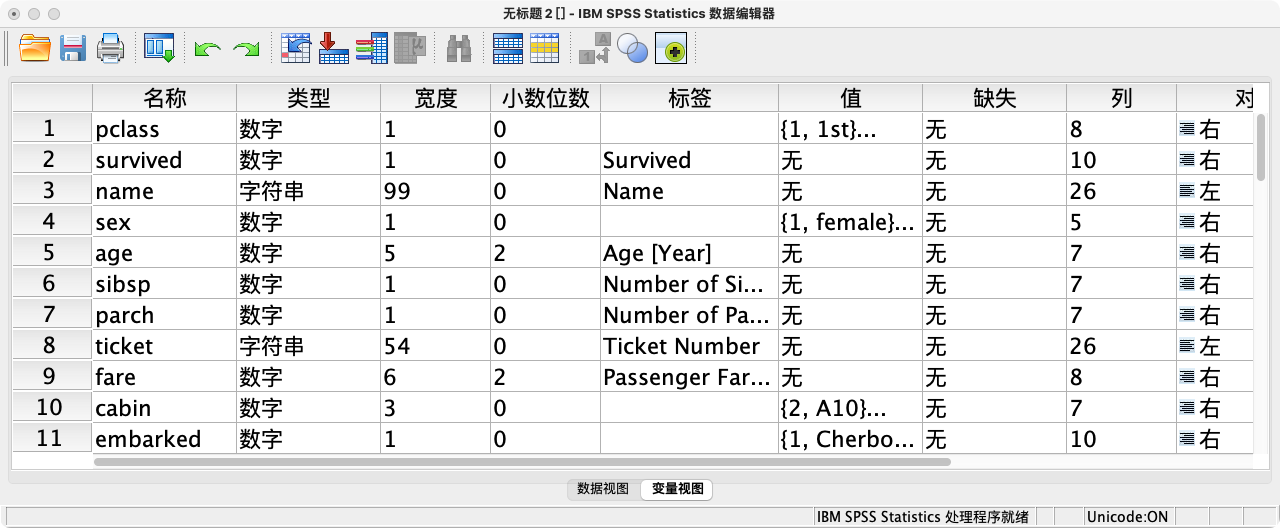
案例(5-2):读取名为"titanic"的Stata数据
GET STATA FILE "titanic.dta".
- 读取Excel格式 (.xls 或 .xlsx)
语法结构相对复杂,常用子命令包括:
/TYPE: 指定文件类型(XLS或XLSX)。/FILE: 指定文件路径和名称。/SHEET: 指定读取哪个工作表(可用名称name或索引index)。/CELLRANGE: 指定读取的数据范围,full表示读取整个工作表。/READNAMES: 指定是否将工作表的第一行作为变量名,ON表示是。
案例(5-3):读取名为"auto"的Excel数据
GET DATA
/TYPE = XLS
/FILE = "auto.xls"
/SHEET = NAME "domestic"
/CELLRANGE = FULL
/READNAMES = ON.
6. 数据集管理:命名与激活
- 在数据分析过程中,我们可能需要同时打开多个数据集。为了方便管理和切换,SPSS允许为每个数据集命名,并通过激活命令将其置于当前操作的前台。
案例(6-1):将新导入的"clds2016_i"数据命名为"clds",并将其窗口置于最前
GET FILE "clds2016_i.sav".
DATASET NAME clds WINDOW = FRONT.
案例(6-2):激活已打开的、名为"clds"的数据集
假设当前正在操作另一个数据集,需要切换回"clds"进行分析。
DATASET ACTIVATE clds.
7. 创建与删除变量 (Variable)
- 点选操作: 切换到“变量视图” → 在“名称”列的空白处输入新变量名 → 在”类型”列(双击空白并点击
…)-> 选择类型。 - 语法操作:
- 字符串型变量 (String):用于存储文本信息。
STRING+ 变量名 +(Axx),其中xx代表字符宽度(即最多容纳多少个字符)。常用于存储姓名、开放题答案等。 - 数字型变量 (Numeric):用于存储数值信息。
NUMERIC+ 变量名 +(Fxx.yy),xx代表总宽度,yy代表小数位数。这是进行统计计算的基础变量类型。
- 字符串型变量 (String):用于存储文本信息。
辅助知识点:变量类型与测量层次 在SPSS中,定类(如性别)和定序(如学历)变量,虽然其本质是分类。在实践操作上,不少学者习惯都使用数字型变量存储,并通过“值标签”功能进行编码说明。例如,性别变量可用
1代表“男性”,2代表“女性”。这样做比直接使用字符串型(如存入“男”、“女”汉字)更有利于后续的统计分析。典型例子是,我们申请使用的大型公开数据库,其定类和定序变量均为数字型变量 (Numeric),如中国综合社会调查(CGSS)、中国家庭追踪调查(CFPS)。
案例(7-1):创建名为gender(性别)和education(教育)的变量
尽管这两个是分类变量,但我们先创建为字符串型作为演示。
* 注意:变量名必须以英文字母开头,不能使用特殊字符.
STRING gender (A2).
STRING education (A2).
- 如果创建的多个变量类型和字符宽度相同,可以简写
STRING gender education (A2).
- 如果创建的多个变量类型相同,字符宽度不同,可以简写
STRING gender (A2) /
education (A3).
案例(7-2):创建定比变量income(收入)
NUMERIC income (F8.2). /* F8.2 表示总宽度为8,其中包含2位小数 */
COMPUTE命令也可以创建新变量。COMPUTE income = 0.会创建一个名为income的新变量,并将其所有个案的初始值都设为0。而NUMERIC命令仅创建变量(列),其初始值为空(系统缺失值)。
COMPUTE income = 0.
EXECUTE.
辅助知识点:
EXECUTE.命令的作用与时机
EXECUTE.是SPSS语法中一个看似简单却至关重要的命令。它的作用就像一个“执行”按钮,强制SPSS立即处理所有在它之前的、处于“待定”状态的数据转换指令。要理解
EXECUTE.,我们首先要知道SPSS如何处理两种不同类型的命令
- 数据转换命令 (Transformations): 像
COMPUTE,RECODE(第四讲),IF(第四讲),SELECT IF(第四讲) 这类命令,它们只是向SPSS“描述”了你想要对数据做的改变。SPSS会把这些指令记下来,但并不会马上执行,我们称之为“待定转换”(pending transformations)。- 数据处理过程 (Procedures): 像
SAVE(第三讲),AGGREGATE(第四讲),FREQUENCIES(第五讲),REGRESSION(第十一讲)这类命令,它们需要SPSS读取整个数据集才能生成报告或保存文件。SPSS的工作模式有点“懒”,它会一直累积“待定转换”指令,直到遇到一个必须读取数据的“处理过程”命令时,才会一次性地将所有待定转换全部执行完毕,然后再执行那个处理过程。
EXECUTE.命令本身就是一个最简单的“处理过程”,它不产生任何输出,唯一的任务就是触发SPSS去完成所有待定的数据转换。什么时候需要或推荐使用
EXECUTE.?
- 想立即看到转换结果时: 这是最常见的场景。你用
COMPUTE创建了一个新变量,想立刻切换到“数据视图”窗口检查结果是否正确,这时就必须在COMPUTE语句后加上EXECUTE.。- 作为代码的逻辑断点: 在一段长长的语法中,用
EXECUTE.将不同的数据处理步骤分隔开,能让代码结构更清晰,也便于分步排查错误。- 简单来讲,当你完成了一步数据修改,并想让这个修改“尘埃落定”时,就用
EXECUTE.。 在学习阶段,多用EXECUTE.是个好习惯。
案例(7-3):删除变量gender、education和income
- 可以分别单独删除。
DELETE VARIABLES gender.
DELETE VARIABLES education.
DELETE VARIABLES income.
- 可以一起连续删除。
DELETE VARIABLES gender education income.
- 如果待删除的变量在数据文件中是连续排列的,可以使用
TO关键字简化操作。
* 假设gender, education, income三个变量在变量视图中是相邻的.
DELETE VARIABLES gender TO income.
8. 修改变量名称 (Rename Variables)
- 点选操作: 变量视图 → 在“名称”列直接修改。
- 语法操作:
RENAME VARIABLES+(旧变量名 = 新变量名).
案例(8-1):将变量名gender、education、income分别修改为sex、educ、salary
RENAME VARIABLES (gender = sex).
RENAME VARIABLES (education = educ).
RENAME VARIABLES (income = salary).
- 等价的简写形式
RENAME VARIABLES (gender = sex) (education = educ) (income = salary).
- 如果需要批量且按顺序重命名,可以这样写
RENAME VARIABLES (gender education income = sex educ salary).
TO关键字同样适用于此,前提是变量在数据文件中连续排列
RENAME VARIABLES (gender TO income = sex educ salary).
9. 修改变量类型 (Alter Type)
- 点选操作: 变量视图 → 点击待修改变量的“类型”列 → 在弹出窗口中选择新类型。
- 语法操作:
ALTER TYPE+ 变量名 +(新类型格式). - 注意:修改变量类型时需谨慎。如果将含有非数字字符的字符串型变量(如“男”、“女”)强行转换为数字型,原有的文本信息会丢失,并转为系统缺失值。正确的做法是先通过“自动重新编码”或
RECODE命令创建新变量。
案例(9-1):将变量类型进行如下修改
- gender, education → 数字型 (F2.0,即宽度为2的整数)
- income → 字符串型 (A8,即宽度为8的字符串)
ALTER TYPE gender education (F2.0).
ALTER TYPE income (A8).
案例(9-2):将所有变量类型均修改为字符串型
* 将从gender到income的所有变量类型改为宽度为2的字符串.
ALTER TYPE gender TO income (A2).
* 将数据集中所有变量的类型都修改.
ALTER TYPE ALL (A10).
10. 添加或修改变量标签 (Variable Labels)
- 变量标签是对变量名的详细说明,通常是问卷上的完整问题。这极大地增强了结果的可读性。
- 点选操作: 变量视图 → 在“标签”列为对应变量输入说明。
- 语法操作:
VARIABLE LABELS+ 变量名 +"标签内容(一般为问卷题目)".
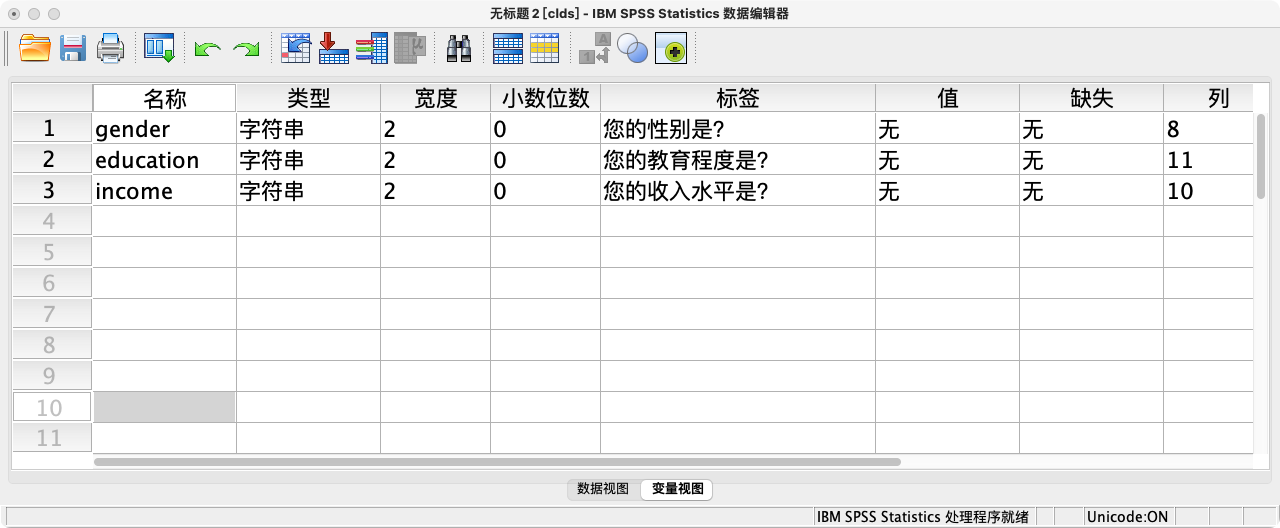
案例(10-1):为变量gender、education和income添加标签
VARIABLE LABELS gender "您的性别是?".
VARIABLE LABELS education "您的教育程度是?".
VARIABLE LABELS income "您的收入水平是?".
- 同时为多个变量添加或修改标签,使用斜杠
/分隔。
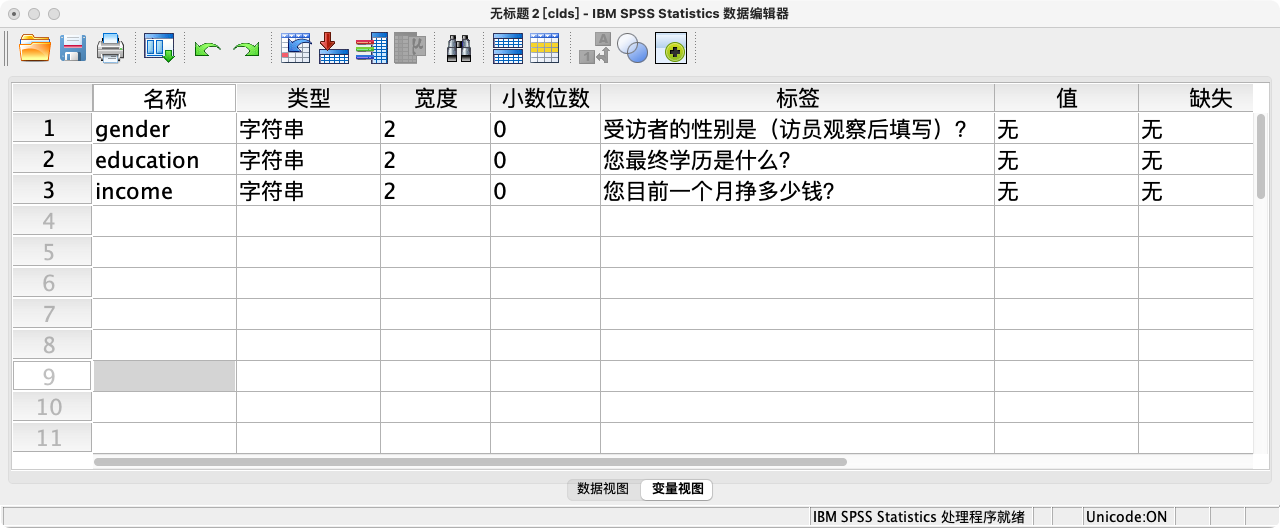
案例(10-2):修改上述变量的标签
VARIABLE LABELS
gender "受访者的性别是(访员观察后填写)?" /
education "您最终学历是什么?" /
income "您目前一个月挣多少钱?".
11. 添加变量取值标签 (Value Labels)
- 值标签是为变量的具体取值(通常是数字)赋予文字说明,说明该数值代表的实际意义(如问卷选项)。
- 点选操作: 变量视图 → 点击待操作变量的“值”列 → 在弹出窗口中逐一添加“值”和“标签”的对应关系。
- 语法操作:
VALUE LABELS+ 变量名 +值1 "标签1" 值2 "标签2" ....
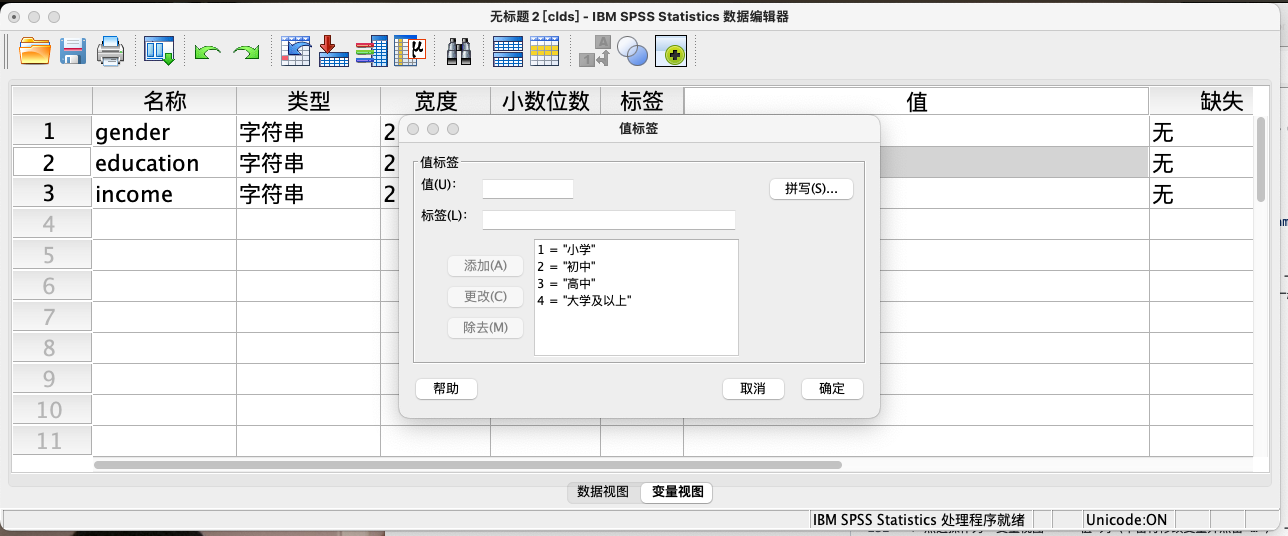
案例(11-1):为education变量添加取值标签
- 1 = “小学及以下”
- 2 = “初中”
- 3 = “高中”
- 4 = “大学及以上”
VALUE LABELS education 1 "小学及以下" 2 "初中" 3 "高中" 4 "大学及以上".
- 如果想在已有标签基础上追加新标签,可以使用
ADD VALUE LABELS命令,这样不会覆盖已有的定义。
* 假设已定义了1-4,现补充定义-9代表缺失.
ADD VALUE LABELS education -9 "不知道".
案例(11-2):同时为gender和education添加取值标签
VALUE LABELS gender 0 "女性" 1 "男性" /
education 1 "小学及以下" 2 "初中" 3 "高中" 4 "大学及以上".
案例(11-3):修改变量取值标签
- 点选操作: 变量视图 -> “值”列(单击待修改变量并点击
…) -> 选择存储框中的值及标签 -> 输入新值或新标签 -> 修改 -> 确定 - 语法操作时,直接为原变量添加新的取值标签,即会覆盖旧的取值标签,起到更新作用
VALUE LABELS education 1 "小学或小学没毕业" 2 "初中学历" 3 "高中或同等学力" 4 "大学及以上学历".
12. 定义变量测量级别 (Measurement Level)
- 定义变量的测量级别有助于SPSS在生成图表或执行某些分析时,提供更合适的默认选项。
- 名义 (Nominal): 定类变量,如性别、行业。
- 有序 (Ordinal): 定序变量,如教育程度、满意度等级。
- 标度 (Scale): 定距或定比变量,如收入、工时、温度。
- 点选操作: 变量视图 → 点击“测量”列,从下拉菜单中选择。
- 语法操作:
VARIABLE LEVEL+ 变量名 +(LEVEL).
案例(12-1):为gender、education和income定义测量级别
VARIABLE LEVEL gender (NOMINAL).
VARIABLE LEVEL education (ORDINAL).
VARIABLE LEVEL income (SCALE).
- 简写形式
VARIABLE LEVEL
gender (NOMINAL) /
education (ORDINAL) /
income (SCALE).
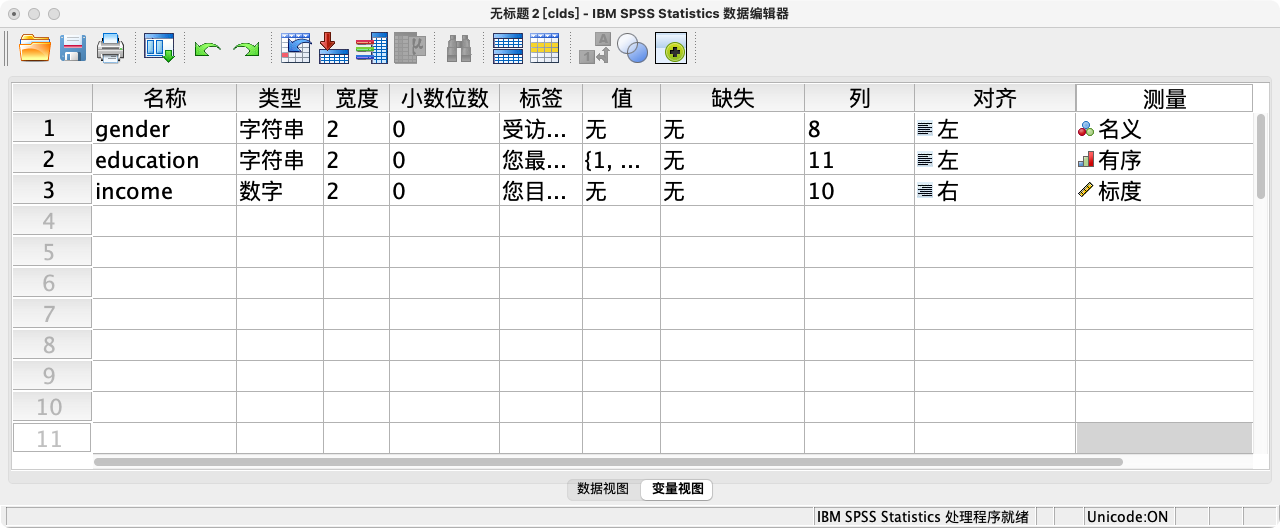
随堂练习:将如下问卷题目录入SPSS
- Q1. 您当前的婚姻状况为? A.未婚 B.同居 C.在婚 D.离婚
- Q2. 您当前从事的行业为? A.服务业 B.制造和建造业 C.公共行政 D.农业
- Q3. 您每周累计工作多长时间? ______(小时)
- 提示: 新建数据集,创建婚姻状况(marital)、工作行业(industry)和工作时间(working_time)三个变量,并完成所有定义。
练习参考答案(Syntax)
* 步骤一:新建一个空白数据集. NEW FILE. DATASET NAME survey_data WINDOW=FRONT. * 步骤二:创建三个变量(推荐使用数字型). NUMERIC marital (F1.0) / industry (F1.0) / working_time(F3.0). * 步骤三:添加变量标签(说明变量是什么). VARIABLE LABELS marital "您当前的婚姻状况为?" / industry "您当前从事的行业为?" / working_time "您每周累计工作多长时间?". * 步骤四:添加值标签(说明选项的含义). VALUE LABELS marital 1 "未婚" 2 "同居" 3 "在婚" 4 "离婚" / industry 1 "服务业" 2 "制造和建造业" 3 "公共行政" 4 "农业". * 步骤五:定义测量级别. VARIABLE LEVEL marital (NOMINAL) / industry (NOMINAL) / working_time (SCALE). * 完成!现在可以切换到数据视图开始录入数据了.
Disqus comments are disabled.