第三讲 问卷编码与数据录入(二)
Publish date: Aug 1, 2021
Last updated: Sep 13, 2025
Last updated: Sep 13, 2025
13. 处理多选题 (Multiple Choice Question)
- 问卷中的多选题,在数据录入时需要进行转换。最常用、最规范的方法是“多重二分法”,即将一个多选题拆解成多个“是/否”型的单选题。每个选项都成为一个独立的变量。
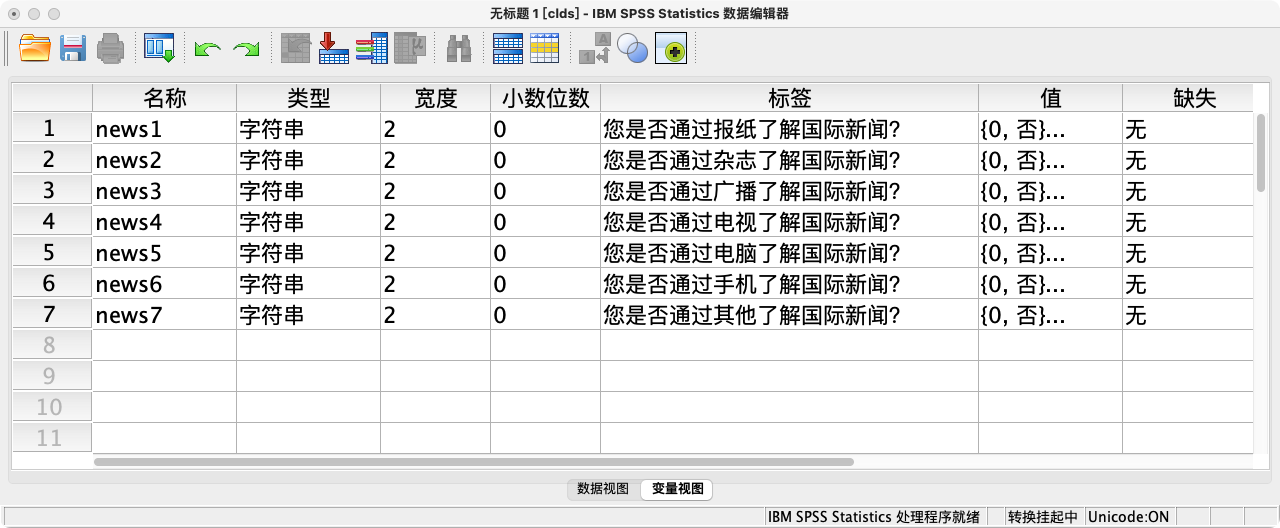
案例(13-1):将以下多选题录入SPSS
- Q1. 您主要通过何种途径了解国际新闻____(可多选): A.报纸 B.杂志 C.广播 D.电视 E.电脑 F.手机 G.其他
- 转换思路: 将其转换为七个独立的、回答为“是”或“否”的变量。
- 您是否通过“报纸”了解国际新闻? (是/否)
- 您是否通过“杂志”了解国际新闻? (是/否)
- … 以此类推 …
- 语法实现
STRING news1 news2 news3 news4 news5 news6 news7 (A1).
* 为每个新变量添加详细的变量标签.
VARIABLE LABELS
news1 "您是否通过报纸了解国际新闻?" /
news2 "您是否通过杂志了解国际新闻?" /
news3 "您是否通过广播了解国际新闻?" /
news4 "您是否通过电视了解国际新闻?" /
news5 "您是否通过电脑了解国际新闻?" /
news6 "您是否通过手机了解国际新闻?" /
news7 "您是否通过其他方式了解国际新闻?".
* 为所有这些变量统一定义值标签:0代表未选中,1代表选中.
VALUE LABELS news1 TO news7 0 "否" 1 "是".
* 定义这些变量的测量级别为名义变量.
VARIABLE LEVEL news1 TO news7 (NOMINAL).
EXECUTE.
14. 定义与处理缺失值 (Missing Value)
- 缺失值是指数据集中由于某种原因而未能记录到的值。在SPSS中,缺失值分为两类:
- 系统缺失值 (System-Missing Value): 指数据单元格中完全没有任何输入,SPSS会以一个点
.来表示。这是默认的缺失状态。 - 用户自定义缺失值 (User-Defined Missing Value): 指由研究者自行指定某个或某些特定数值来代表缺失,例如用
99代表“不知道”,用-9代表“拒绝回答”等。这样做的好处是可以区分不同原因的缺失。
- 系统缺失值 (System-Missing Value): 指数据单元格中完全没有任何输入,SPSS会以一个点
- 点选操作: 变量视图 → 点击目标变量所在行的“缺失”列 → 在弹出窗口中设定离散值(如
99)或范围。 - 语法操作:
MISSING VALUES+ 变量名 +(值或范围).
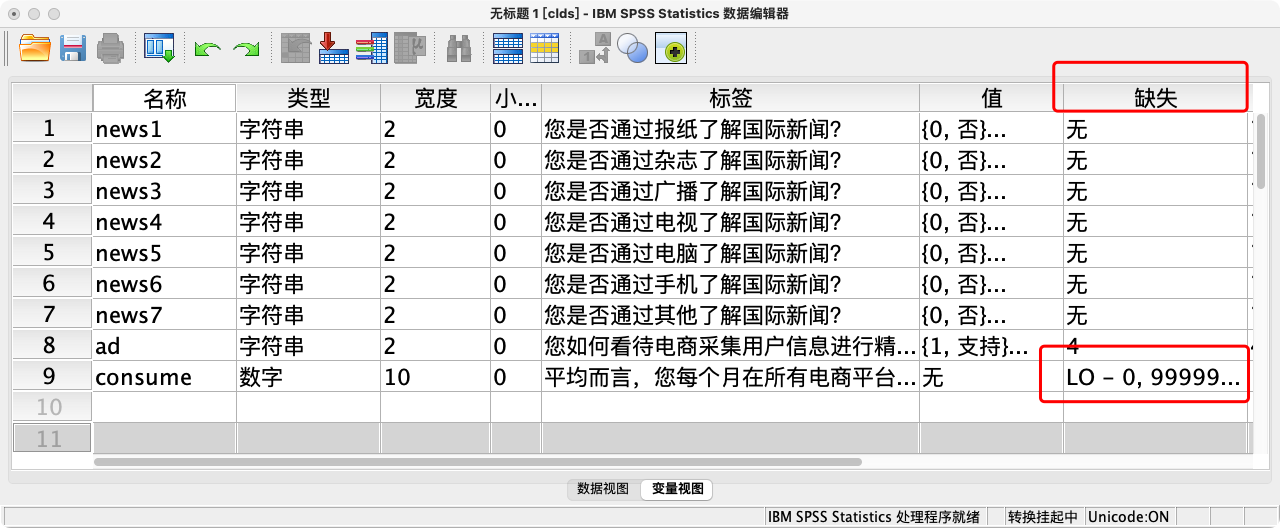
案例(14-1):将以下问题录入SPSS并处理缺失值
- Q1. 您如何看待电商采集用户信息进行精准广告投放? A.支持 B.理解 C.反对 D.说不清楚
- Q2. 平均而言,您每个月在所有电商平台上花多少钱? _____
- 缺失情况分析
- 对于Q1,选项 D “说不清楚” 在分析时可能不作为有效态度,可定义为用户自定义缺失值。
- 对于Q2,受访者可能拒绝回答(留空,成为系统缺失值),或填写了无意义的负数。这些都应被视为缺失。
* 为Q1创建数字型变量ad,为Q2创建consume.
STRING ad (A2).
NUMERIC consume (F10.0).
* 添加变量标签.
VARIABLE LABELS
ad "您如何看待电商采集用户信息进行精准广告投放" /
consume "平均而言,您每个月在所有电商平台上花多少钱".
* 添加值标签.
VALUE LABELS ad 1 "支持" 2 "理解" 3 "反对" 4 "说不清楚".
* 定义测量级别.
VARIABLE LEVEL ad (NOMINAL) / consume (SCALE).
* 定义缺失值.
* 对于ad变量,将数值4("说不清楚")定义为缺失值.
* 对于consume变量,将从系统最小值(lo)到0的所有值,以及一个特殊的大数9999999999定义为缺失值.
MISSING VALUES ad (4) consume (LO THRU 0, 9999999999).
EXECUTE.
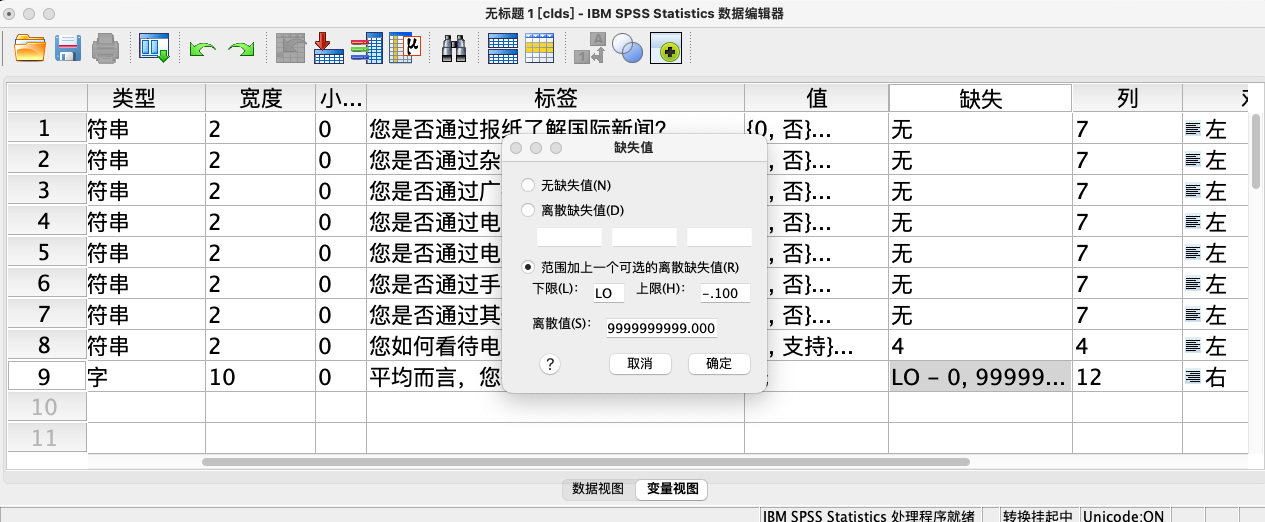
- 补充说明: 如果在某个研究中,消费金额
0是一个有效值(代表确实没有花费),而非缺失,那么缺失值范围应设置为不包含0。
* 将从最小值(lo)到任何小于0的数(例如-0.001)都定义为缺失.
MISSING VALUES consume (LO THRU -0.001, 9999999999).
15. 处理跳答题 (Skip Pattern / Conditional Question)
- 跳答题是指受访者根据对某一题的回答,跳过后续部分题目。这会导致被跳过题目的数据自然缺失。
案例(15-1):将以下含跳答逻辑的问卷录入SPSS
- Q1. 您平时是否会在电商平台上买东西? A.是 B.否 (如选B,则跳过Q2和Q3)
- Q2. 您平时会选择在哪个电商平台上买东西? (可多选) A.淘宝/天猫 B.京东 …
- Q3. 平均而言,您每个月在所有电商平台上花多少钱? _____
* 创建变量. ol_shopping是关键的甄别问题.
STRING ol_shopping e_commerce1 e_commerce2 e_commerce3 e_commerce4 e_commerce5 e_commerce6 (A2).
NUMERIC consume (F10.2).
* 添加变量标签.
VARIABLE LABELS
ol_shopping "Q1: 您平时是否会在电商平台上买东西" /
e_commerce1 "Q2a: 您平时是否会选择在淘宝或天猫上买东西" /
e_commerce2 "Q2b: 您平时是否会选择在京东上买东西" /
e_commerce3 "Q2c: 您平时是否会选择在拼多多上买东西" /
e_commerce4 "Q2d: 您平时是否会选择在微店上买东西" /
e_commerce5 "Q2e: 您平时是否会选择在亚马逊上买东西" /
e_commerce6 "Q2f: 您平时是否还会选择在其他电商平台上买东西" /
consume "Q3: 平均而言,您每个月在所有电商平台上花多少钱".
* 添加值标签.
VALUE LABELS ol_shopping 1 "是" 0 "否".
VALUE LABELS e_commerce1 TO e_commerce6 1 "选中" 0 "未选中".
* 定义测量级别.
VARIABLE LEVEL ol_shopping e_commerce1 TO e_commerce6 (NOMINAL).
VARIABLE LEVEL consume (SCALE).
* 对于因跳答而产生的缺失,我们无需在MISSING VALUES中特别定义.
* 在数据录入时,若某受访者在ol_shopping中回答了“0 否”,则其后的e_commerce系列变量和consume变量应直接留空.
* SPSS会自动将这些留空的单元格识别为“系统缺失值”,并在统计分析中正确处理.
EXECUTE.
辅助知识点:用语法处理跳答逻辑 在数据清理阶段,我们可以使用
IF语句来确保跳答逻辑被严格执行。例如,以下语法会检查所有在Q1回答“否”的个案,并确保他们后续的变量值被设置成系统缺失值。IF (ol_shopping = 0) e_commerce1 TO e_commerce6 = $SYSMIS. IF (ol_shopping = 0) consume = $SYSMIS. EXECUTE.

16. 输入数据
- 点选操作: 在完成变量定义后,切换到“数据视图”,像在Excel中一样,在对应的单元格中输入编码后的数值。
- 语法操作: 使用
BEGIN DATA.和END DATA.命令块,可以直接在语法文件中输入数据,便于分享和复现。 - 注意: 推荐使用点选操作录入数据,避免串行或串位。
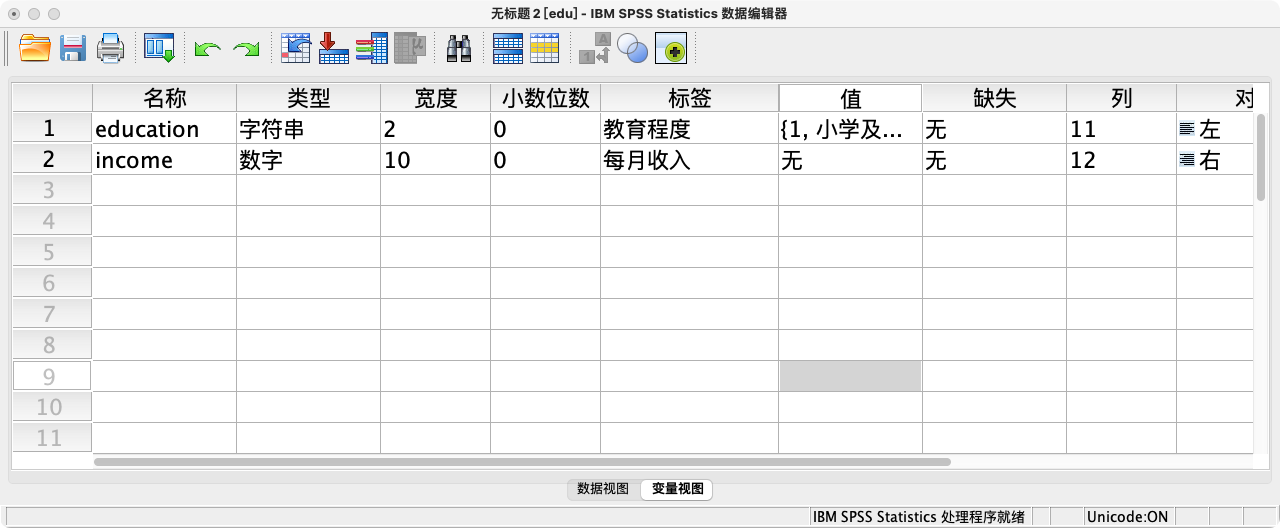
案例(16-1):创建一个名为edu的数据集,并录入以下数据
| 受访者编号 | 教育程度 | 每月收入 |
|---|---|---|
| 1 | 初中 | 3600 |
| 2 | 大学 | 7000 |
| 3 | 小学 | 9000 |
| 4 | 高中 | 6500 |
| 5 | 大学 | 12000 |
| 6 | 硕士 | 14000 |
* 步骤一:定义变量结构.
DATA LIST FREE / id education income.
* 步骤二:直接在语法中输入数据.
BEGIN DATA.
1 2 3600
2 4 7000
3 1 9000
4 3 6500
5 4 12000
6 5 14000
END DATA.
* 步骤三:为变量添加详细定义.
DATASET NAME edu.
VARIABLE LABELS
id "受访者编号" /
education "教育程度" /
income "每月收入".
VALUE LABELS education
1 "小学及以下"
2 "初中"
3 "高中"
4 "大学"
5 "硕士及以上".
VARIABLE LEVEL
id (NOMINAL) /
education (ORDINAL) /
income(SCALE).
EXECUTE.
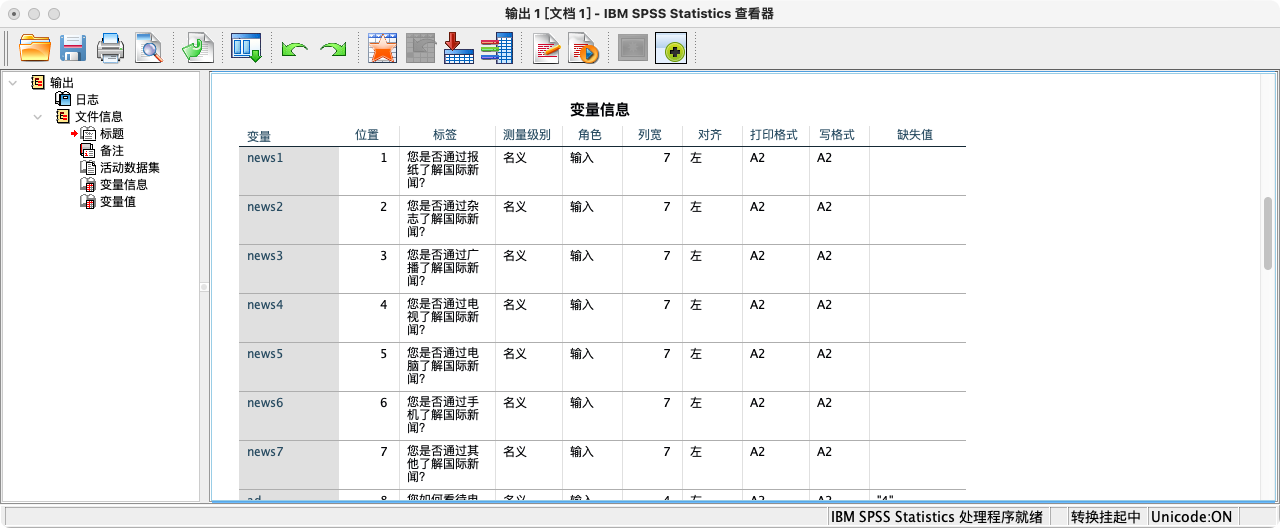
17. 查看所有变量的基本信息 (Dictionary)
DISPLAY DICTIONARY.命令可以快速生成一张包含当前数据集中所有变量信息的列表,包括变量名、标签、格式等,是数据概览的有效工具。
DISPLAY DICTIONARY.
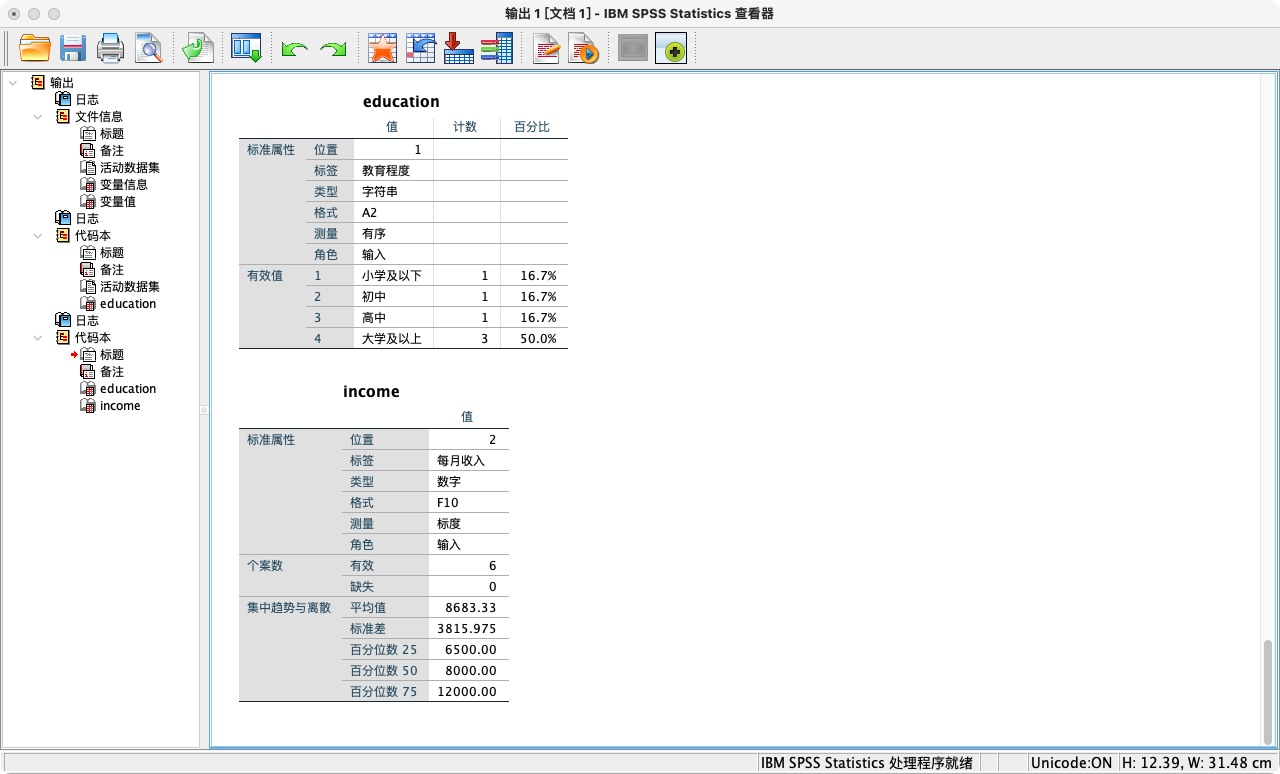
18. 查看变量的详细编码簿 (Codebook)
CODEBOOK命令比DISPLAY DICTIONARY更进一步,它能提供单个或多个变量极其详尽的信息,包括定义的标签、值标签、缺失值定义,以及位置、类型等元数据,是检查数据定义是否准确无误的最佳工具。- 点选操作: 分析 → 报告 → 代码本 → 左列选中变量 → 点击转移至"代码本" → 确定
- 语法结构:
CODEBOOK+ 变量名.
案例(18-1):查看变量education和income的详细编码信息
CODEBOOK education income.
19. 查看变量的基本统计量
- 点选操作: 分析 → 描述 → 频率 → 左列选中变量 → 点击转移至"变量"列 → 统计(勾选统计量)→ 继续 → 确定
- 语法操作:
DESCRIPTIVES var1 var2 ...
/STATISTICS = [统计量1] [统计量2] ...
/SORT = [MEANS | STDDEV | VARIANCE | NAME] [A | D]
/SAVE.
语法说明
-
DESCRIPTIVES varlist- 这是命令的主体,用于指定你想要分析的一个或多个连续变量。
-
/STATISTICS = [统计量列表]- 用于指定你希望在输出表格中显示的统计量。
- 默认选项: 如果省略此子命令,SPSS会默认输出
MEAN,STDDEV,MIN,MAX。 - 常用选项:
MEAN: 均值STDDEV: 标准差MIN: 最小值MAX: 最大值VARIANCE: 方差RANGE: 全距 (Max - Min)SUM: 总和SEMEAN: 均值标准误KURTOSIS: 峰度SKEWNESS: 偏度
ALL: 请求输出所有可用的统计量。
-
/SAVE- 这是一个非常有用的功能,它会为
/VARIABLES中指定的每个变量,计算其标准化Z分数,并将其作为一个新变量保存在当前数据集中。 - 新变量会自动命名为原变量名前加一个“Z”(例如,
income的Z分数变量为Zincome)。 - Z分数的含义:一个观测值距离其所在变量的均值有多少个“标准差”的距离。这个转换对于发现极端值或在不同量纲的变量间进行比较非常有用。
- 这是一个非常有用的功能,它会为
-
/SORT(不常用)- 用于控制输出表格中变量的显示顺序,可以按均值、标准差等排序。
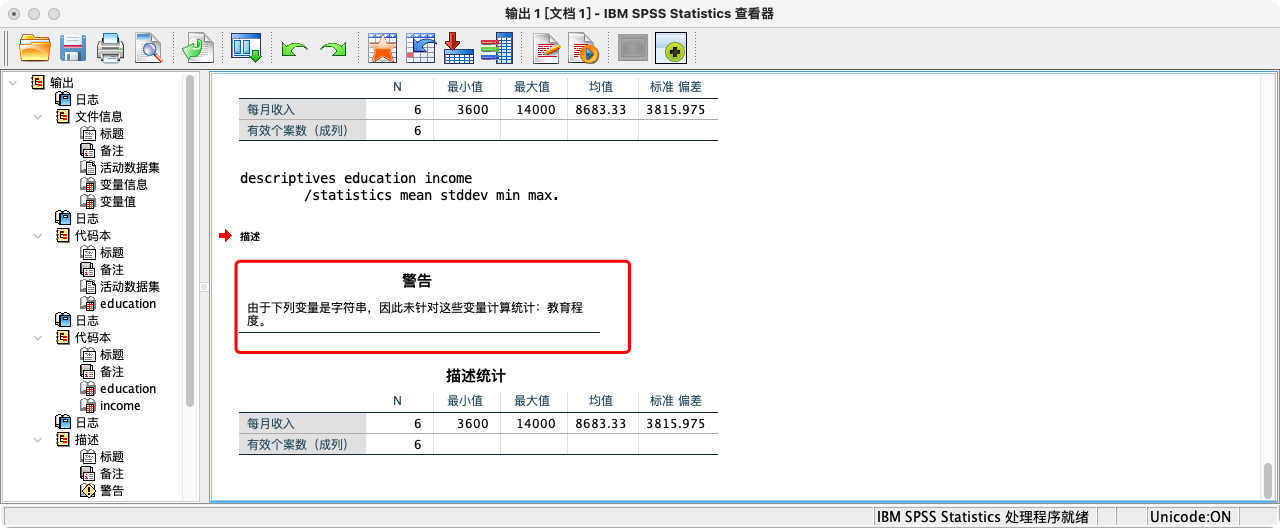
案例(19-1):查看变量education和income的基本统计信息
DESCRIPTIVES income
/STATISTICS MEAN STDDEV MIN MAX.
- 重要提示:
education是一个有序分类变量,其数值(1, 2, 3…)代表等级而非真实数量。因此,计算其“平均受教育程度”在统计学上是没有意义的。我们更关心每个教育等级上有多少人,占比多少。
20. 储存数据集
- 点选操作: 文件 → 另存为 → 选择存储路径 → 输入文件名 → 保存
- 语法操作: 使用
SAVE OUTFILE(存为.sav格式) 或SAVE TRANSLATE(存为其他格式)。
(1)SAVE OUTFILE的语法结构
- 用于将当前活动的数据集保存为SPSS原生格式(.sav)。
SAVE OUTFILE = '文件路径/文件名.sav'
[/COMPRESSED]
[/KEEP = 变量列表 | /DROP = 变量列表].
语法说明
SAVE OUTFILE = '文件路径/文件名.sav'- 这是命令的主体,用于指定保存的位置和文件名。
- 强烈建议提供完整的文件路径,以避免文件被保存到意想不到的位置。如果已使用
CD命令设置了工作目录,则可以只写文件名。 - 文件名必须以
.sav结尾。
/COMPRESSED- 这是一个非常有用的选项,表示以压缩格式保存。这可以显著减小
.sav文件的体积,尤其是在处理大型数据集时。推荐始终使用。
- 这是一个非常有用的选项,表示以压缩格式保存。这可以显著减小
/KEEP或/DROP- 用于保存数据集的一个子集。这两个选项是互斥的,只能使用其中一个。
/KEEP = 变量1 变量2 ...: 只保留列表中指定的变量,其余全部丢弃。/DROP = 变量1 变量2 ...: 丢弃列表中指定的变量,其余全部保留。
(2)SAVE TRANSLATE的语法结构
- 用于将当前活动的数据集转换为其他格式并保存。
SAVE TRANSLATE OUTFILE = '文件路径/文件名.ext'
/TYPE = [格式类型]
[/VERSION = 版本号]
[/SHEET = '工作表名']
[/FIELDNAMES]
[/REPLACE].
语法说明
SAVE TRANSLATE OUTFILE = '文件路径/文件名.ext'- 指定保存的路径和文件名。注意,文件的扩展名
.ext应该与/TYPE中指定的格式相匹配 (例如.dta,.xlsx)。
- 指定保存的路径和文件名。注意,文件的扩展名
/TYPE = [格式类型]- 核心选项,用于指定要转换的目标文件格式。
STATA: Stata 格式 (.dta)。XLS: Excel 格式 (.xlsx 或 .xls)。CSV: 逗号分隔值格式 (.csv)。TAB: 制表符分隔值格式 (.dat)。
/VERSION = 版本号(主要用于Stata)- 指定Stata文件的版本号,以确保兼容性。例如,
/VERSION = 14。
- 指定Stata文件的版本号,以确保兼容性。例如,
- Excel 专用选项
/SHEET = '工作表名': 指定在Excel文件中保存到的工作表的名称。/FIELDNAMES: 将SPSS的变量名作为第一行写入Excel文件,即作为列标题。
/REPLACE- 如果指定的文件名已存在,这个选项允许SPSS覆盖旧文件。如果没有这个选项且文件已存在,命令将会报错并停止。这是一个重要的安全设置。
案例(20-1):将当前数据集以压缩的SPSS格式(.sav)存为"demo.sav"
SAVE OUTFILE = "demo.sav"
/COMPRESSED.
案例(20-2):储存时剔除变量education,其余存为"demo.sav"
DROP子命令用于指定要剔除的变量。
SAVE OUTFILE = "demo.sav"
/DROP = education
/COMPRESSED.
案例(20-3):储存时仅保留变量income,存为"demo.sav"
KEEP子命令用于指定要保留的变量。
SAVE OUTFILE = "demo.sav"
/KEEP = income
/COMPRESSED.
案例(20-4):将数据存为Stata 14 SE版格式(.dta)
SAVE TRANSLATE用于跨格式保存。/REPLACE表示如果已存在同名文件,则覆盖它。
SAVE TRANSLATE OUTFILE = "demo.dta"
/TYPE = Stata
/VERSION = 14
/EDITION = SE
/REPLACE
/KEEP = id income.
案例(20-5):将数据存为Excel格式(.xlsx)
SAVE TRANSLATE OUTFILE = "demo.xlsx"
/TYPE = XLS
/VERSION = 12
/REPLACE
/FIELDNAMES
/CELLS = VALUES.
Disqus comments are disabled.