第四讲 数据整理与变量操作
Publish date: Aug 1, 2021
Last updated: Sep 18, 2025
Last updated: Sep 18, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 通过重新编码创建新变量 (Recode)
RECODE是SPSS中最核心和最常用的数据转换命令之一。它能够根据我们设定的规则,将一个或多个旧变量的值转换为新值,并存入一个新的变量中,从而实现变量类型的转换或数据的重新分组。- 点选操作:转换 → 重新编码为不同变量 → 左侧列表选择旧变量 → 转移至变量框 → 填写新变量名和标签 → 点击变化量 → 点击旧值和新值 → 左侧填写旧值(或范围)和右侧填写新值 → 添加新值 → 重复所有取值 → 填写缺失值 → 继续 → 确定(如设置错误,可点击“重置”再来一遍)
- 语法操作:
RECODE 旧变量名 (旧值1 = 新值1) (旧值2 THRU 旧值3 = 新值2) ... (ELSE = SYSMIS) INTO 新变量名.THRU:表示一个连续的范围。ELSE = SYSMIS:一个非常有用的选项,表示所有未被明确指定转换规则的值,在新变量中都将被设为系统缺失值。这可以有效避免遗漏和错误。ELSE = COPY:表示未被指定的值将原封不动地复制到新变量中。
辅助知识点:为何要“重新编码为不同变量”? 强烈建议始终使用“重新编码为不同变量” (recode … into …),而不是“重新编码为相同变量”。这样做可以保留原始变量以供核对和备查,避免因编码错误导致原始数据丢失,是数据处理中一项重要的“安全原则”。
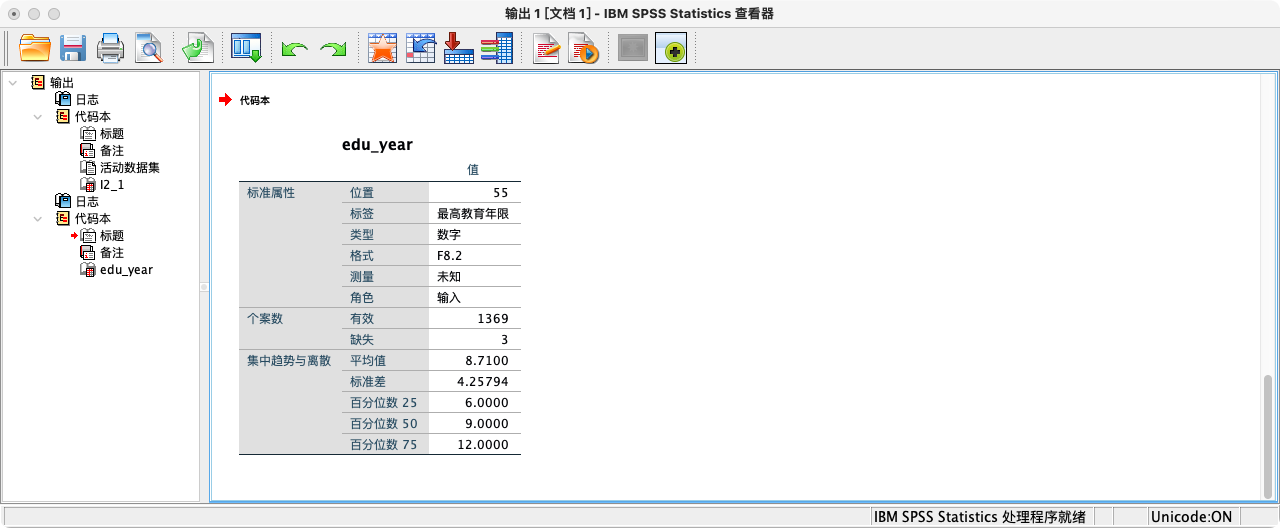
案例(1-1):将分类变量“最高教育程度 (I2_1)”转换为连续变量“教育年限 (edu_year)”
- 转换规则:
- 未上过学 → 0年
- 小学/私塾 → 6年
- 初中 → 9年
- 高中/中专/技校等 → 12年
- 大专 → 15年
- 本科 → 16年
- 硕士 → 19年
- 博士 → 22年
- 其他/拒绝回答等 → 系统缺失值
* 步骤一:(可选但推荐) 检查原始变量的编码.
CODEBOOK I2_1.
* 步骤二:执行重新编码.
RECODE I2_1 (1=0)
(2=6)
(3=9)
(4 THRU 7=12)
(8=15)
(9=16)
(10=19)
(11=22)
(ELSE=SYSMIS)
INTO edu_year.
* 步骤三:为新变量添加标签和定义.
VARIABLE LABELS edu_year "受访者教育年限".
VARIABLE LEVEL edu_year (SCALE).
* 步骤四:检查新变量的生成情况.
CODEBOOK edu_year.
FREQUENCIES edu_year.
EXECUTE.
辅助知识点:离散取值的重新编码
RECODE I2_1 (1=0) (2=6) (3=9) (4 THRU 7=12) (8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS) INTO edu_year. *等价于. RECODE I2_1 (1=0) (2=6) (3=9) (4, 5, 6, 7=12) (8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS) INTO edu_year.
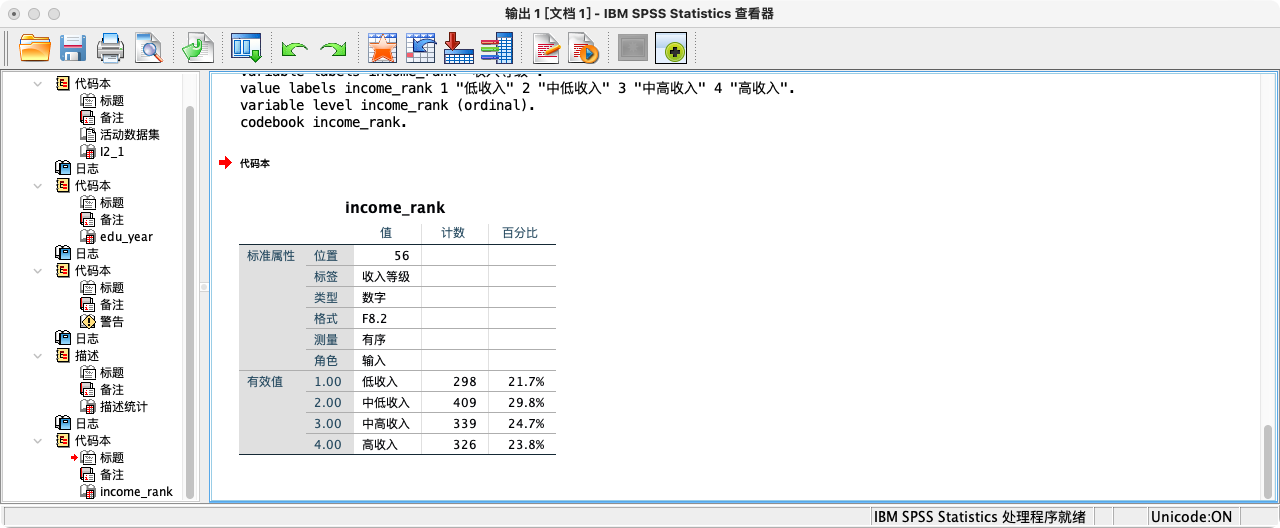
案例(1-2):将连续变量“2015年总收入 (I3a_6)”转换为有序分类变量“收入等级 (income_rank)”
- 分组规则
- 不足6000元: 1 “低收入”
- 6000元至20000元: 2 “中低收入”
- 20000元至40000元: 3 “中高收入”
- 40000元以上: 4 “高收入”
- 注意:在
RECODE中,THRU包含两端的边界值。
* 步骤一:了解原始变量的分布.
DESCRIPTIVES I3a_6
/STATISTICS=MEAN MIN MAX.
* 步骤二:执行重新编码.
* LO THRU 6000 表示从最小值到6000.
* 6000.001 THRU 20000 表示从刚好大于6000的数到20000.
* 40000.001 THRU HI 表示从刚好大于40000的数到最大值.
RECODE I3a_6
(LO THRU 6000=1)
(6000.001 THRU 20000=2)
(20000.001 THRU 40000=3)
(40000.001 THRU HI=4)
(ELSE=SYSMIS)
INTO income_rank.
* 步骤三:为新变量添加标签和定义.
VARIABLE LABELS income_rank "收入等级".
VALUE LABELS income_rank 1 "低收入" 2 "中低收入" 3 "中高收入" 4 "高收入".
VARIABLE LEVEL income_rank (ORDINAL).
* 步骤四:检查新变量.
CODEBOOK income_rank.
FREQUENCIES income_rank.
EXECUTE.
2. 通过数学运算创建新变量 (Compute)
COMPUTE命令允许我们像使用计算器一样,通过数学表达式创建新变量。- 点选操作:转换 → 计算变量 → 目标变量(输入新变量名) → 数字表达式(输入公式) → 确定
- 语法操作:
COMPUTE 新变量名 = 数学表达式.
案例(2-1):将2015年总收入变量"I3a_6"从人民币转换为美元
- 假设当时汇率为 1美元 = 6.2284人民币。
COMPUTE income_dollars = I3a_6 / 6.2284.
COMPUTE income_dollars_m = income_dollars / 12.
VARIABLE LABELS income_dollars "2015年总收入(美元)" /
income_dollars_m "2015年月均收入(美元)".
EXECUTE.
随堂练习:计算2015年个人的劳动收入总额,包括工资收入(I3a_6_1)和兼职收入(I3b_5)。
练习参考答案
* COMPUTE命令配合SUM函数可以很好地处理含有缺失值的情况. * SUM(var1, var2) 在计算时,如果其中一个变量是缺失值,会将其当作0来处理. * 而 var1 + var2 的方式,只要有一个是缺失值,结果就是缺失值. COMPUTE labor_income = SUM(I3a_6_1, I3b_5). VARIABLE LABELS labor_income "2015年个人劳动总收入". EXECUTE.
3. 通过变量间条件关系创建新变量 (IF / DO IF)
- 当新变量的取值依赖于一个或多个现有变量所满足的条件时,我们需要使用条件判断功能。
- 点选操作:转换 → 计算变量 → 目标变量(输入新变量名) → 数字表达式(输入公式)→ 如果(填入运算条件)→ 继续 → 确定
- 语法操作:
- IF:
IF (条件) 新变量名 = 值.,适用于简单、互不冲突的条件 - DO IF:适用于复杂、互斥的多条件分组,是更推荐、更安全的方式
- IF:
- 条件关系:
&符号表示并、且,|符号表示或DO IF (条件1). COMPUTE 新变量名 = 值1. ELSE IF (条件2). COMPUTE 新变量名 = 值2. ELSE. COMPUTE 新变量名 = 其他值. END IF.
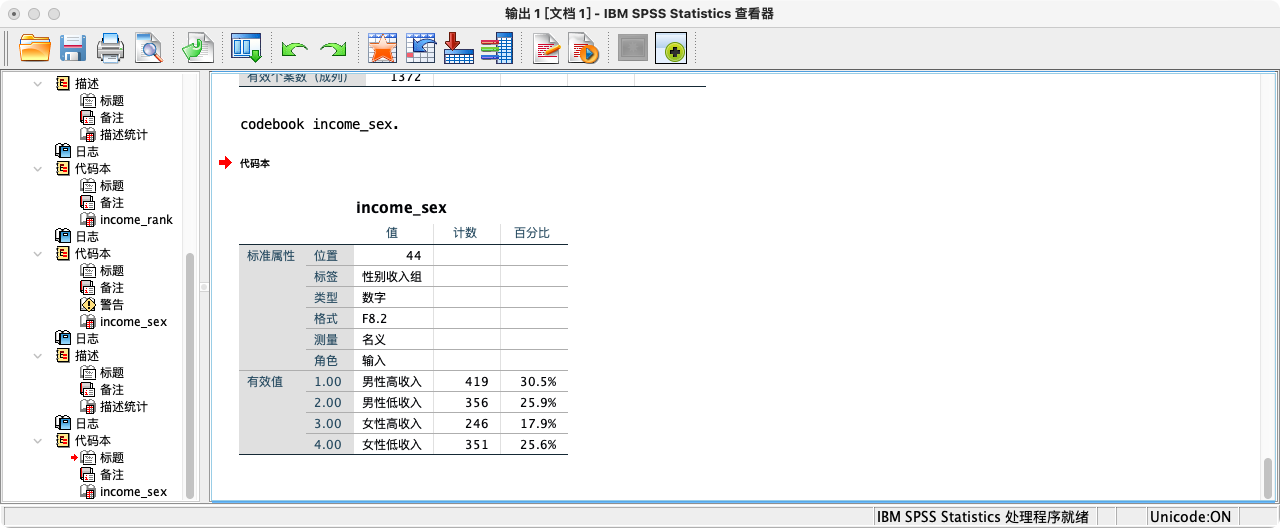
案例(3-1):创建新变量“性别收入组”
- 分组规则
- 男性 (gender=1) 且 收入等级>=3 → 1 “男性高收入”
- 男性 (gender=1) 且 收入等级<=2 → 2 “男性低收入”
- 女性 (gender=2) 且 收入等级>=3 → 3 “女性高收入”
- 女性 (gender=2) 且 收入等级<=2 → 4 “女性低收入”
* 常规IF语法.
IF (gender = 1 & income_rank >= 3) income_sex1 = 1.
IF (gender = 1 & income_rank <= 2) income_sex1 = 2.
IF (gender = 2 & income_rank >= 3) income_sex1 = 3.
IF (gender = 2 & income_rank <= 2) income_sex1 = 4.
* 为新变量添加标签和定义.
VARIABLE LABELS income_sex1 "性别收入组".
VALUE LABELS income_sex1 1 "男性高收入" 2 "男性低收入" 3 "女性高收入" 4 "女性低收入".
VARIABLE LEVEL income_sex1 (NOMINAL).
FREQUENCIES income_sex1.
EXECUTE.
* 使用更稳健的 DO IF 结构.
DO IF (gender = 1 & income_rank >= 3).
COMPUTE income_sex2 = 1.
ELSE IF (gender = 1 & income_rank <= 2).
COMPUTE income_sex2 = 2.
ELSE IF (gender = 2 & income_rank >= 3).
COMPUTE income_sex2 = 3.
ELSE IF (gender = 2 & income_rank <= 2).
COMPUTE income_sex2 = 4.
END IF.
* 为新变量添加标签和定义.
VARIABLE LABELS income_sex2 "性别收入组".
VALUE LABELS income_sex2 1 "男性高收入" 2 "男性低收入" 3 "女性高收入" 4 "女性低收入".
VARIABLE LEVEL income_sex2 (NOMINAL).
FREQUENCIES income_sex2.
EXECUTE.
随堂练习:利用学历 (I2_1) 和收入 (I3a_6) 变量,创建新变量“学历收入组”,包括本科及以上高收入、本科及以上低收入、本科以下高收入、本科以下低收入。
练习参考答案
* 收入门槛设为20000元,学历门槛为本科(I2_1=9). DO IF (I2_1 >= 9 & I3a_6 > 20000). COMPUTE edu_income_group = 1. /*本科及以上高收入*/ ELSE IF (I2_1 >= 9 & I3a_6 <= 20000). COMPUTE edu_income_group = 2. /*本科及以上低收入*/ ELSE IF (I2_1 < 9 & I3a_6 > 20000). COMPUTE edu_income_group = 3. /*本科以下高收入*/ ELSE IF (I2_1 < 9 & I3a_6 <= 20000). COMPUTE edu_income_group = 4. /*本科以下低收入*/ END IF. VARIABLE LABELS edu_income_group "学历收入组". VALUE LABELS edu_income_group 1 "本科及以上-高收入" 2 "本科及以上-低收入" 3 "本科以下-高收入" 4 "本科以下-低收入". EXECUTE.
4. 通过变量分组关系创建新变量 (Aggregate)
AGGREGATE是一个强大的命令,用于根据一个或多个分组变量(如家庭ID、公司ID),计算其他变量的统计摘要(如总和、均值、人数等)。- 点选操作:数据 → 汇总 → 分界变量(选择分组变量) → 汇总变量(选择用以计算的变量) → 函数(选择摘要统计)
- 语法操作:
AGGREGATE /BREAK=分组变量 /新变量名 = 函数(源变量)./BREAK:指定用于分组的变量。函数: 如SUM()(求和),MEAN()(均值),N()(计数),MIN()(最小值) 等。
案例(4-1):计算每个家庭的2015年总收入
- 思路:如何以家庭ID (
FID2016) 为分组,对每个家庭内所有成员的个人年收入 (I3a_6) 进行求和?- 问卷中个体ID
IID2016为受访者的个人唯一识别码,即任意两人不相等 - 问卷中家庭ID
FID2016为受访者的家庭唯一识别码,即同一家庭内的受访者相等,但不同家庭的受访者不相等 - 将同一家庭内所有成员在2015年总收入”I3a_6”进行加总,即可得到该家庭在2015年的总收入
- 问卷中个体ID
AGGREGATE
/BREAK=FID2016
/household_income "家庭总收入" = SUM(I3a_6).
EXECUTE.
VARIABLE LABELS household_income (scale).
CODEBOOK household_income.
DESCRIPTIVES household_income
/STATISTICS=MEAN STDDEV MIN MAX.
- 执行后,数据集中会增加一列
household_income,同一家庭的所有成员在该列上的值都是相同的。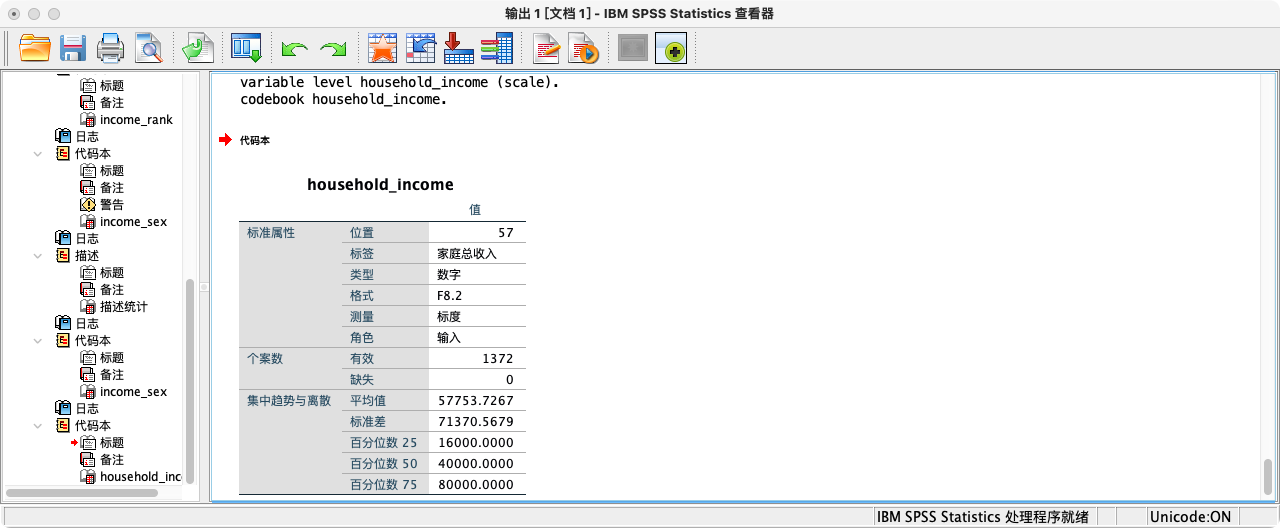
案例(4-2):计算每个家庭的人口规模
- 方法一:先创建一个值为1的“标记”变量,然后按家庭ID对标记求和。
COMPUTE mark = 1.
AGGREGATE
/BREAK=FID2016
/household_num1 "家庭人口规模" = SUM(mark).
EXECUTE.
DESCRIPTIVES household_num1
/STATISTICS=MEAN STDDEV MIN MAX.
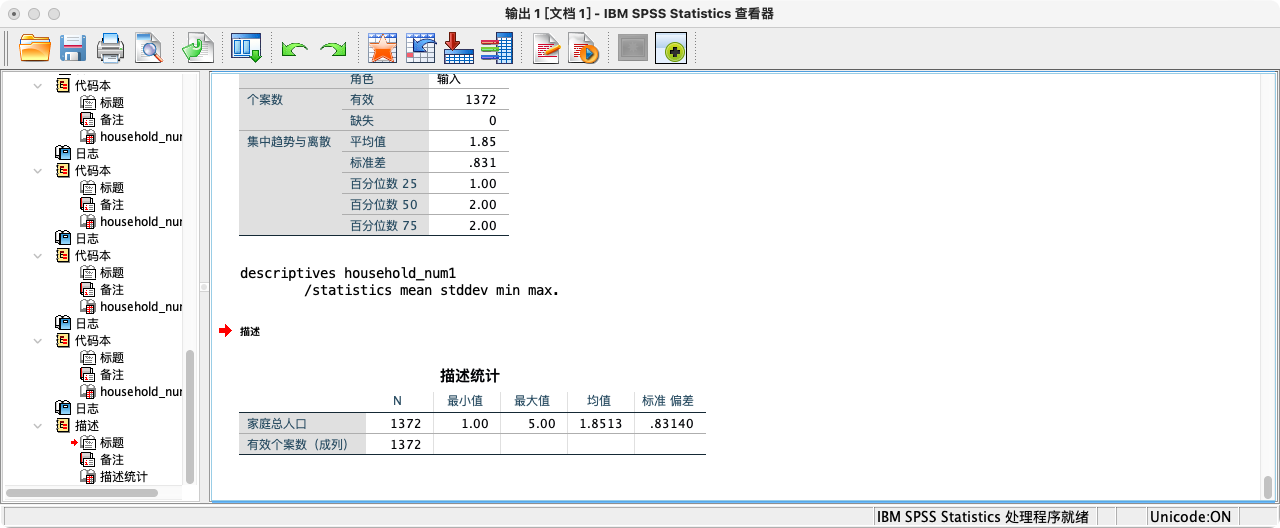
- 方法二:直接使用
N函数,统计每个家庭ID下的个案数。
AGGREGATE
/BREAK=FID2016
/household_num2 "家庭人口规模" = N.
EXECUTE.
DESCRIPTIVES household_num2
/STATISTICS=MEAN STDDEV MIN MAX.
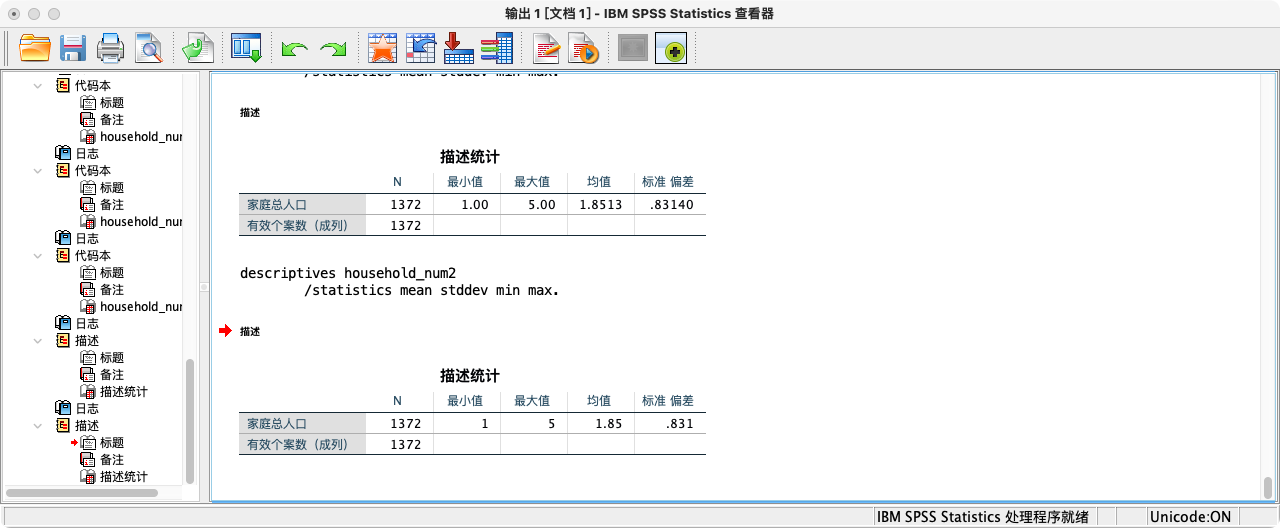
随堂练习:计算2015年家庭总劳动投入,用工作时间(I3a_1)来衡量。
5. 筛选个案 (Select Cases)
- 筛选个案是数据分析中的常用步骤,用于将分析对象限定在满足特定条件的子样本中。
- 点选操作:数据 → 选择个案 → 条件栏(选
如果条件满足,点击如果)→ 选择变量 → 在空白框输入条件(|指或,&指并)→ 继续 → 输出框(选删除未选定的个案) → 确定 - 语法操作:
SELECT IF (条件). - 重要警告:
SELECT IF会永久删除不满足条件的个案。在执行前,务必保存原始数据集的备份。对于探索性分析,建议使用FILTER命令或TEMPORARY.命令,它们可以暂时隐藏不满足条件的个案,而不会将其删除。
案例(5-1):查看中国女性劳动者的2015年收入状况
- 筛选标准
- 年龄在18-65岁之间 (劳动年龄人口)。
- 性别为女性。
- 2015年总收入大于0。
- 操作流程
- 检查相关变量的有效性。
- 根据需要处理异常值。
- 创建分析所需的衍生变量(如年龄)。
- 执行筛选。
* 第一步:检查性别和出生年份变量.
FREQUENCIES gender birthyear.
* 第二步:处理出生年份中的异常值(如2016年).
RECODE birthyear (2016 THRU HI = SYSMIS) (ELSE = COPY).
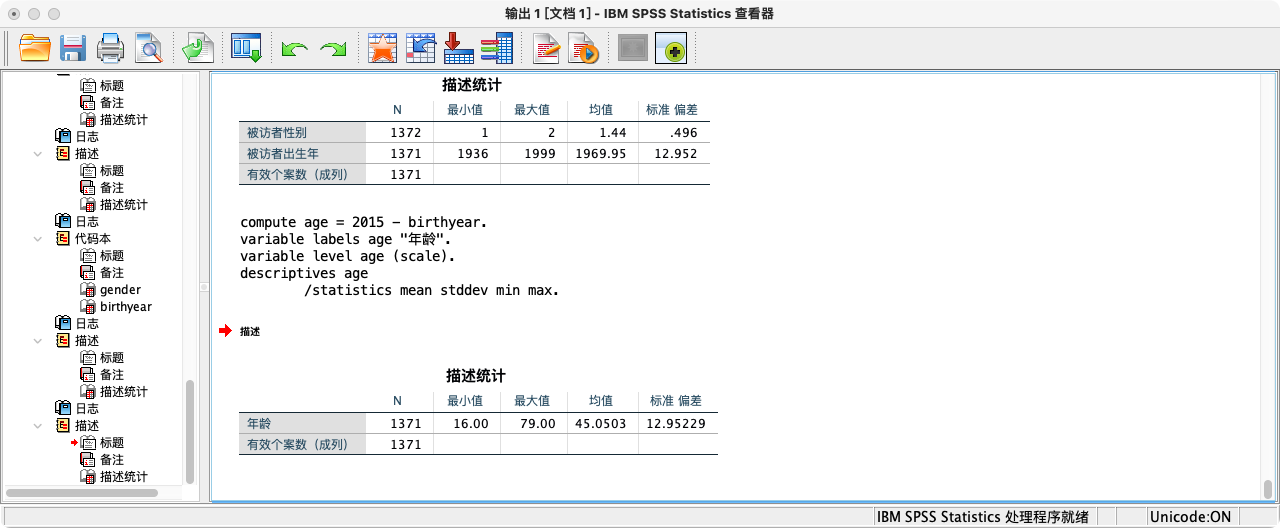
* 第三步:计算年龄(以2015年为基准).
COMPUTE age = 2015 - birthyear.
VARIABLE LABELS age "年龄".
DESCRIPTIVES age.
* 第四步:执行筛选.
* 建议先用 TEMPORARY 命令进行探索.
TEMPORARY.
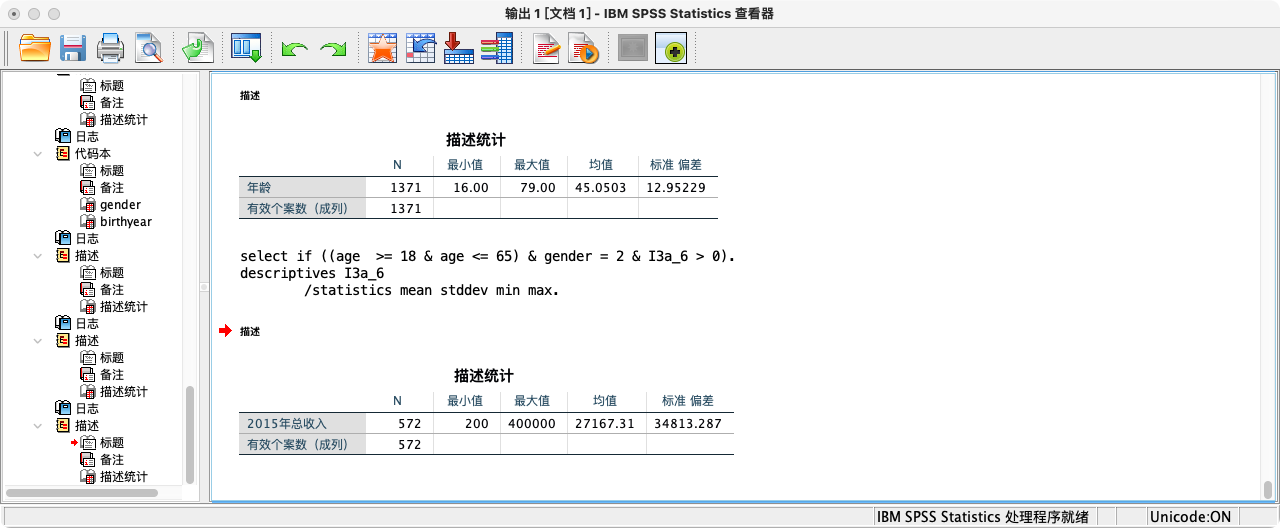
SELECT IF ((age >= 18 & age <= 65) & gender = 2 & I3a_6 > 0).
DESCRIPTIVES I3a_6
/STATISTICS=MEAN STDDEV MIN MAX.
* 如果确认筛选条件无误,再执行永久性删除.
SELECT IF ((age >= 18 & age <= 65) & gender = 2 & I3a_6 > 0).
EXECUTE.
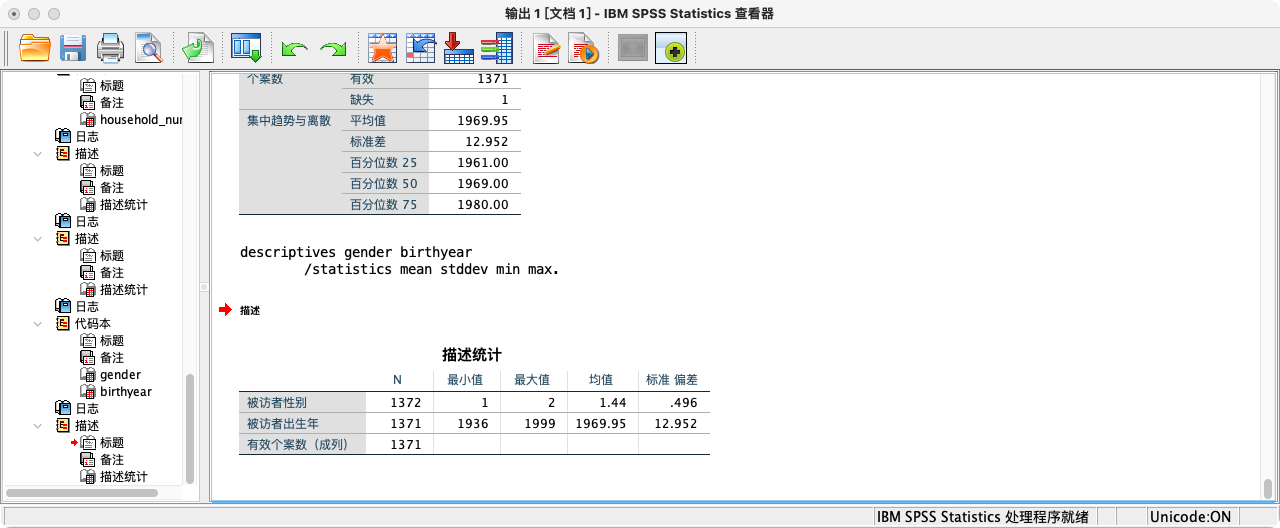
随堂练习:查看中国老年劳动者的2015年收入状况。
- 提示
- 筛选65岁以上人口
- 筛选有工作人口
6. 个案排序 (Sort Cases)
- 排序 (Sort Cases) 指根据一个或多个变量的值,对数据文件中的所有个案(行)进行物理上的重新排列。
- 点选操作:数据 → 个案排序 → 选择变量(选至排序依据) → 排序依据 → 确定
- 语法操作:
SORT CASES BY + 变量 + (A)/(D)(升序或降序).
案例(6-1):查看女性劳动者收入的排序
- 假设已按案例(5-1)筛选出女性劳动者样本。
- 第一种方法:直接查看女性劳动收入排序
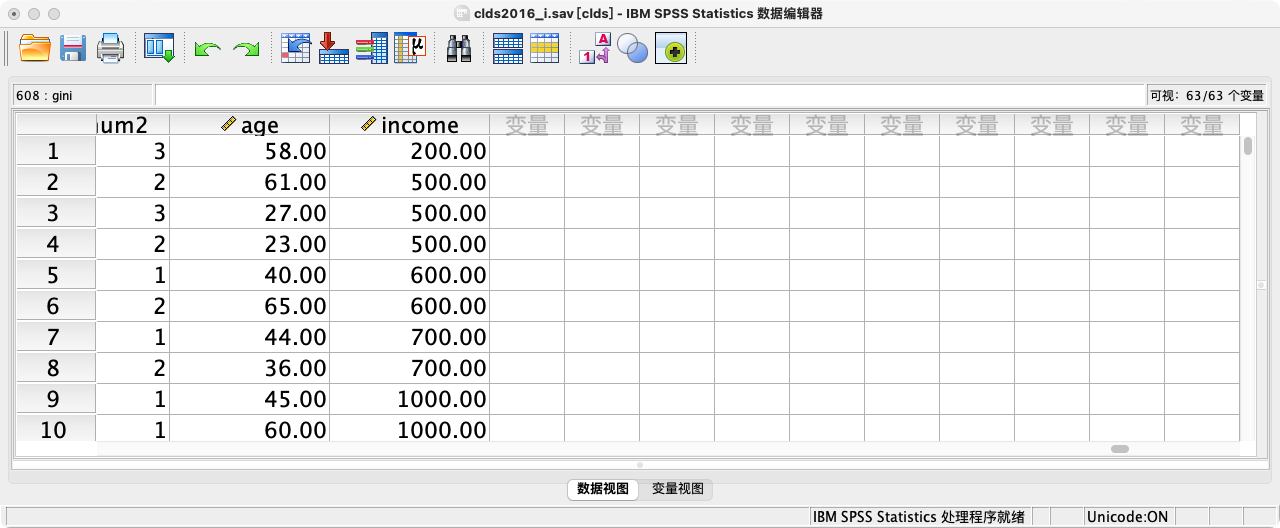
* 按收入升序(A)对个案进行排序. 降序为 (D).
RECODE I3a_6 (sysmis = 0)
(else = copy) INTO income.
VARIABLE LABELS income "收入".
VARIABLE LEVEL income (scale).
SORT CASES BY income (A).
-
执行后,数据视图中的行顺序会发生改变,收入最低的排在最上面。
-
第二种方法:创建一个新变量,显示女性劳动收入排序
* 按收入升序(A)对个案进行排序. 降序为 (D).
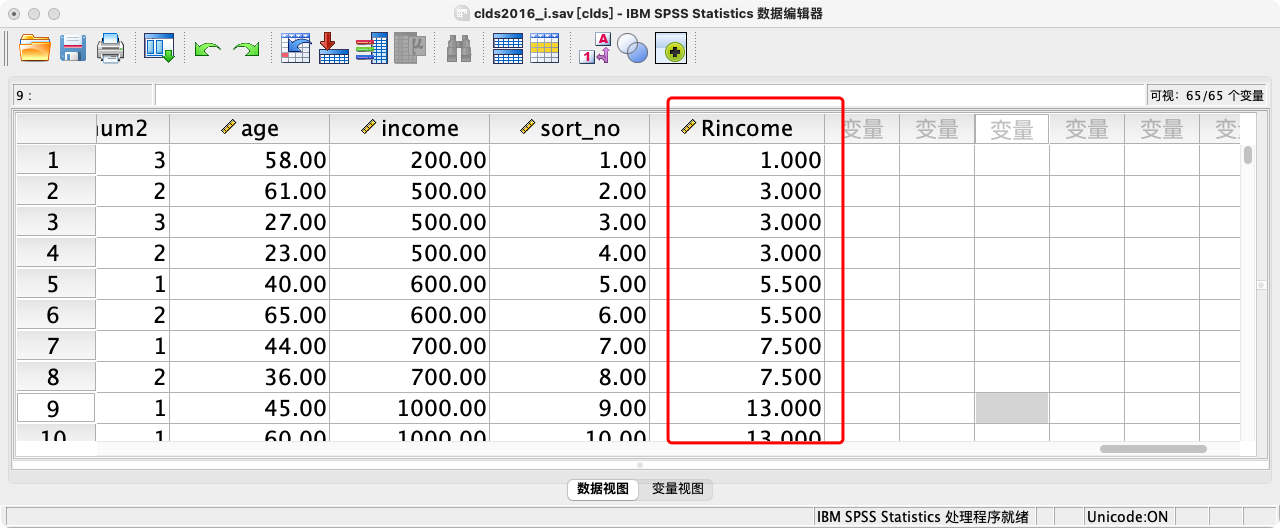
COMPUTE sort_no = $CASENUM.
7. 个案排秩 (Rank)
- 排秩 (Rank) 指创建一个新变量,其内容是个案在某个变量上的名次(或百分位秩等)。它不改变个案的物理顺序。
- 点选操作:转换 → 个案排秩 → 选择变量 → 类型排秩(选
秩或百分比秩)→ 继续 - 语法操作:
RANK VARIABLES = + 变量 + (A)/(D)(升序或降序) + /RANK(秩)或 /PERCENT(百分比秩)
案例(7-1):查看女性劳动者收入的排秩
- 排秩可以生成一个新变量,记录每个人的收入排名。
RANK VARIABLES = income (A)
/RANK INTO income_rank_num.
EXECUTE.
- 排序与排秩的区别:如果出现收入相同的情况(即“并列”),排序会把她们放在一起,但顺序是任意的;而排秩会给她们相同的名次(默认是并列名次的平均值)。
随堂练习:计算收入前10%群体的收入总和占总体收入的比例,以此作为衡量社会不平等的指标。
练习参考答案 (较复杂)
* 假设已筛选出目标分析样本. * 步骤一:计算总体的总收入. AGGREGATE /total_income = SUM(I3a_6). * 步骤二:对收入进行排秩,得到百分位秩. RANK VARIABLES=I3a_6 (A) /PERCENT INTO income_percentile. * 步骤三:标记出收入在前10%的群体 (即百分位秩大于90). COMPUTE top10_flag = 0. IF (income_percentile > .90) top10_flag = 1. * 步骤四:计算前10%群体的收入总和. COMPUTE top10_income = 0. IF (top10_flag = 1) top10_income = I3a_6. * 步骤五:计算前10%群体的收入总和. AGGREGATE /total_top10_income = SUM(top10_income). * 步骤六:计算最终比例. COMPUTE top10_share = (total_top10_income / total_income) * 100. * 查看结果(只需查看第一行即可). LIST total_income total_top10_income top10_share in 1. EXECUTE.
Disqus comments are disabled.