第五讲 变量的基本描述统计
Publish date: Aug 1, 2021
Last updated: Sep 13, 2025
Last updated: Sep 13, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 探索性分析 (Examine)
- 探索性分析 (Exploratory Data Analysis, EDA) 是进行正式统计检验之前,对数据进行初步“侦查”的过程。
EXAMINE命令是完成此任务的利器,它特别适用于深入了解一个连续变量的分布特征,以及比较该变量在不同类别下的分布差异。 - 点选操作:分析 → 描述报告 → 探索 → 填入因变量列表 → 子因变量列表(分组变量) → 选择统计量和图 → 确定
- 语法操作:
EXAMINE VARIABLES = 因变量 BY 分组变量 /PLOT = 图形类型 /STATISTICS = 统计量./PLOT:常用图形包括HISTOGRAM(直方图),BOXPLOT(箱线图),STEMLEAF(茎叶图),NPPLOT(正态Q-Q图)。箱线图在分组比较时尤其直观。/STATISTICS:DESCRIPTIVES提供详细的描述统计量,EXTREME会列出5个最大值和5个最小值,对于发现异常值很有帮助。
案例(1-1):探索不同性别间的收入差异
- 第一步:准备性别变量
- 原始
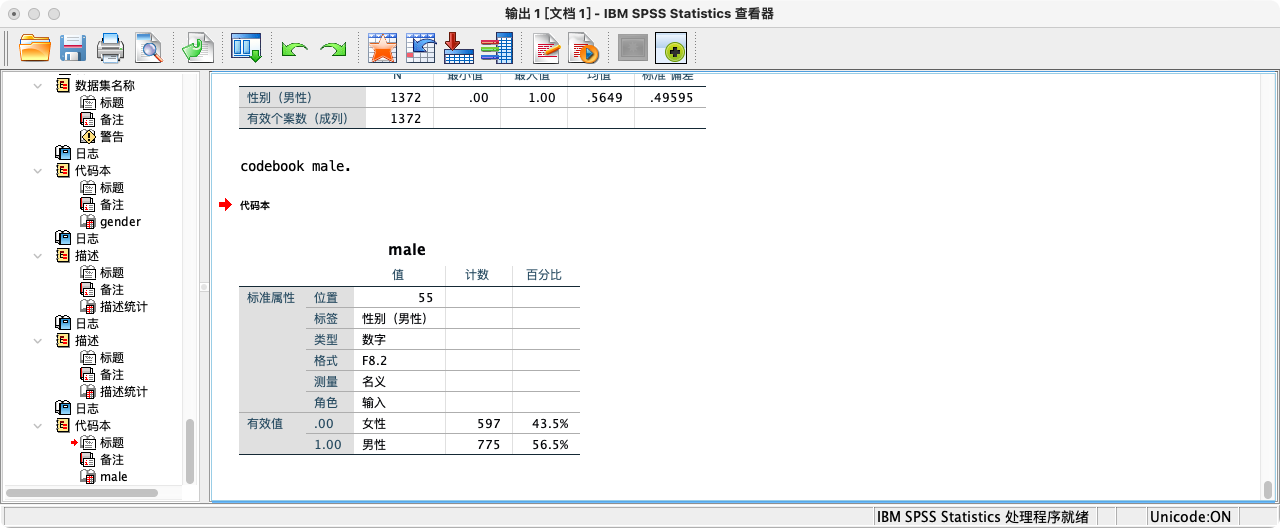
gender变量用1和2编码。为了后续分析的便利性(尤其是在回归分析中),我们通常将其重新编码为一个“虚拟变量”(Dummy Variable),例如创建一个名为male的变量,用1代表男性,0代表女性。
- 原始
* 原始 gender 变量:1=男, 2=女.
* 创建新变量 male:1=男, 0=女.
RECODE gender (1=1) (2=0) (ELSE=SYSMIS) INTO male.
VARIABLE LABELS male "性别 (1=男性)".
VALUE LABELS male 1 "男性" 0 "女性".
VARIABLE LEVEL male (NOMINAL).
*排除缺失值.
SELECT IF I3a_6 > 0.
CODEBOOK male.
EXECUTE.
- 第二步:准备收入变量。
- 为了代码的可读性,我们将
I3a_6复制为一个新变量total_income。这一步不是必需的,但当需要对原始变量做复杂处理时,保留一个副本是好习惯。
- 为了代码的可读性,我们将
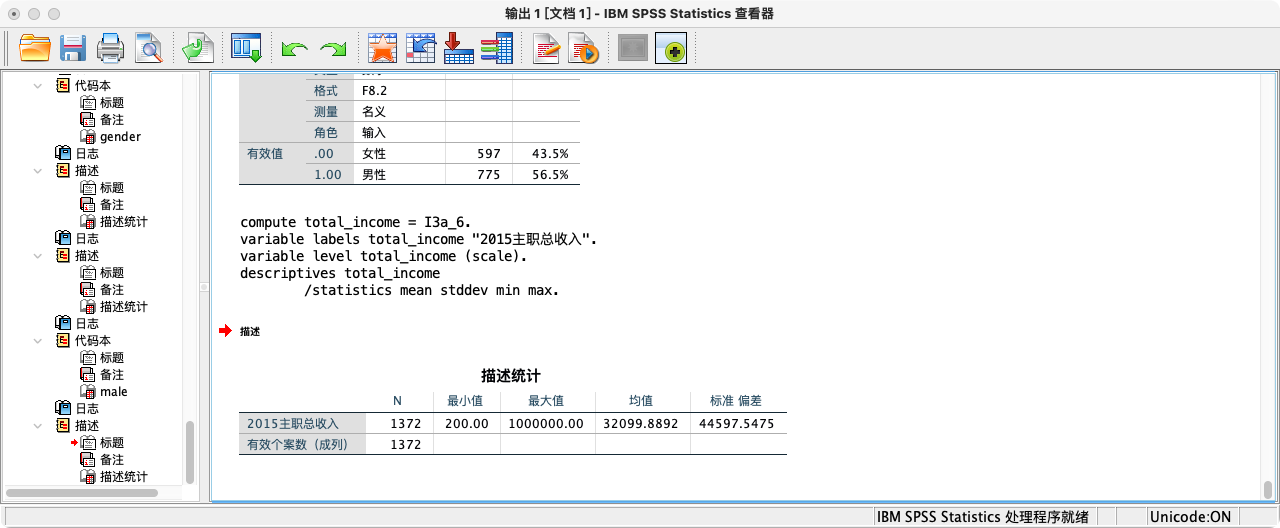
COMPUTE income = I3a_6.
VARIABLE LABELS income "2015年总收入".
VARIABLE LEVEL income (SCALE).
DESCRIPTIVES income
/STATISTICS = MEAN STDDEV MIN MAX.
EXECUTE.
- 第三步:按性别分组,探索收入分布。
- 这是
EXAMINE命令的核心应用场景:比较一个连续变量(total_income)在不同组别(gender)中的情况。
- 这是
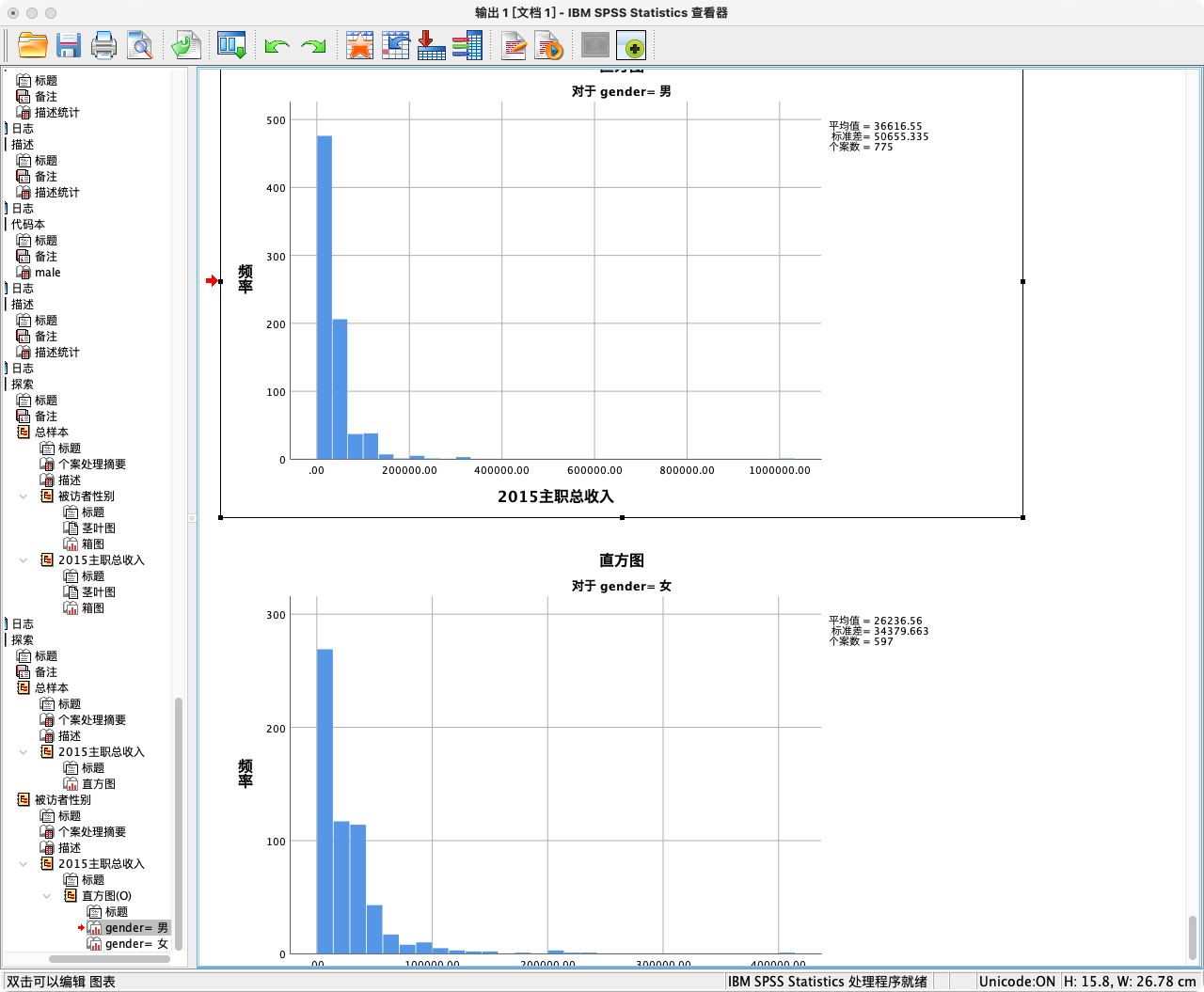
EXAMINE VARIABLES = income BY gender
/PLOT = BOXPLOT HISTOGRAM
/STATISTICS = DESCRIPTIVES.
- 结果解读:上述语法会为男性和女性两个群体分别生成一套描述统计表(均值、中位数、标准差等)和分布图(箱线图、直方图)。通过并列比较,我们可以直观地看到两组人在收入的中心趋势、离散程度和分布形状上的差异。
随堂练习:比较不同劳动年龄段的总收入情况(按18-35岁、36-50岁、51-65岁划分)。
练习参考答案
* 步骤一:计算年龄变量. COMPUTE age = 2016 - birthyear. * 步骤二:根据年龄创建年龄分段变量. RECODE age (18 THRU 35=1) (36 THRU 50=2) (51 THRU 65=3) (ELSE=SYSMIS) INTO age_group. VARIABLE LABELS age_group "劳动年龄分段". VALUE LABELS age_group 1 "18-35岁" 2 "36-50岁" 3 "51-65岁". VARIABLE LEVEL age_group (ORDINAL). * 步骤三:使用EXAMINE命令进行探索. EXAMINE VARIABLES = I3a_6 BY age_group /PLOT = BOXPLOT /STATISTICS = DESCRIPTIVES. EXECUTE.
2. 频数分析 (Frequencies)
FREQUENCIES是SPSS中最基本的描述统计命令之一。它有两个主要用途- 主要用途:针对分类变量(名义或有序),生成频数分布表,显示每个类别的个案数、百分比、有效百分比和累计百分比。
- 次要用途:针对连续变量(标度),虽然也能生成频数表(但通常因条目过多而无意义),但其强大的
/STATISTICS子命令可以计算非常全面的单元统计量,如均值、中位数、众数、分位数、标准差、偏度、峰度等。
- 点选操作:分析 → 描述统计 → 频率 → 填入统计量或图表 → 继续 → 确定
- 语法操作:
*通用结构.
FREQUENCIES VARIABLES = var1 var2 ...
/FORMAT = [排序方式]
/STATISTICS = [统计量1] [统计量2] ...
/PERCENTILES = [数值1] [数值2] ...
/BARCHART = [选项]
/PIECHART = [选项]
/HISTOGRAM = [选项].
- 语法说明
FREQUENCIES VARIABLES = varlist这是命令的主体,用于指定你想要分析的一个或多个变量。/FORMAT用于控制输出的频数表如何排序。AVALUE: 按变量的值进行升序排列 (默认)。DVALUE: 按变量的值进行降序排列。AFREQ: 按每个值的频数进行升序排列。DFREQ: 按每个值的频数进行降序排列 (常用于快速找出最高频的类别)。- 示例:
/FORMAT = DFREQ.
/STATISTICS用于请求计算各种描述性统计量,尤其适用于连续变量。- 常用选项:
MEAN(均值),MEDIAN(中位数),MODE(众数),STDDEV(标准差),VARIANCE(方差),SEMEAN(均值标准误),MINIMUM(最小值),MAXIMUM(最大值),RANGE(全距),SUM(总和),SKEWNESS(偏度),KURTOSIS(峰度)。 - 特殊关键字:
DEFAULT: 输出默认的四个统计量 (均值, 标准差, 最小值, 最大值)。ALL: 输出所有可用的统计量。NONE: 不输出任何统计量 (默认)。
- 示例:
/STATISTICS = MEAN MEDIAN STDDEV.
- 常用选项:
/PERCENTILES用于计算指定的百分位数。在等号后直接列出你想要的百分位数值即可,用空格或逗号隔开。- 示例 (计算四分位数):
/PERCENTILES = 25 50 75.
- 示例 (计算四分位数):
- 图形选项 (
/BARCHART,/PIECHART,/HISTOGRAM) 用于请求生成相应的统计图形。/BARCHART: 条形图 (适用于分类变量)。/PIECHART: 饼图 (适用于分类变量)。/HISTOGRAM: 直方图 (适用于连续变量)。- 常用选项:
FREQ: 纵轴显示频数。PERCENT: 纵轴显示百分比。NORMAL: 在直方图上叠加正态分布曲线。
- 示例:
/BARCHART PERCENT.或/HISTOGRAM NORMAL.
案例(2-1):分析2015年总收入的分布情况
- 第一步:将连续的收入变量分组为有序的收入等级变量。这便于我们使用频数分布表进行观察。
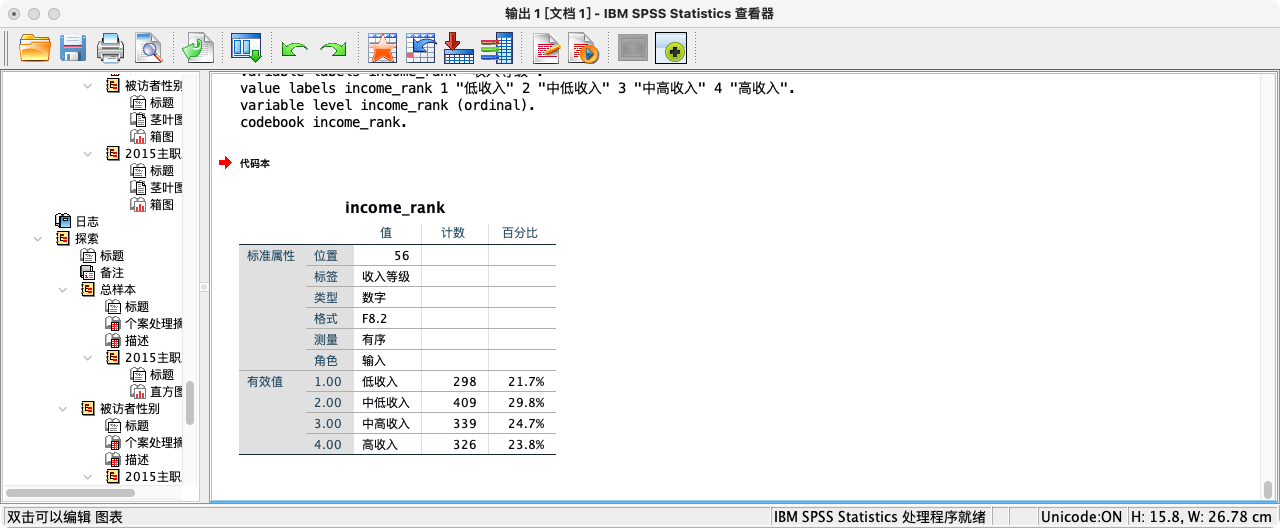
RECODE income
(LO THRU 6000=1)
(6000.01 THRU 20000=2)
(20000.01 THRU 40000=3)
(40000.01 THRU HI=4)
(ELSE=SYSMIS)
INTO income_rank.
VARIABLE LABELS income_rank "收入等级".
VALUE LABELS income_rank 1 "低收入 (<=6k)" 2 "中低收入 (6k-20k)" 3 "中高收入 (20k-40k)" 4 "高收入 (>40k)".
VARIABLE LEVEL income_rank (ORDINAL).
CODEBOOK income_rank.
EXECUTE.
- 第二步:对分类的收入等级变量进行频数分析并绘图。
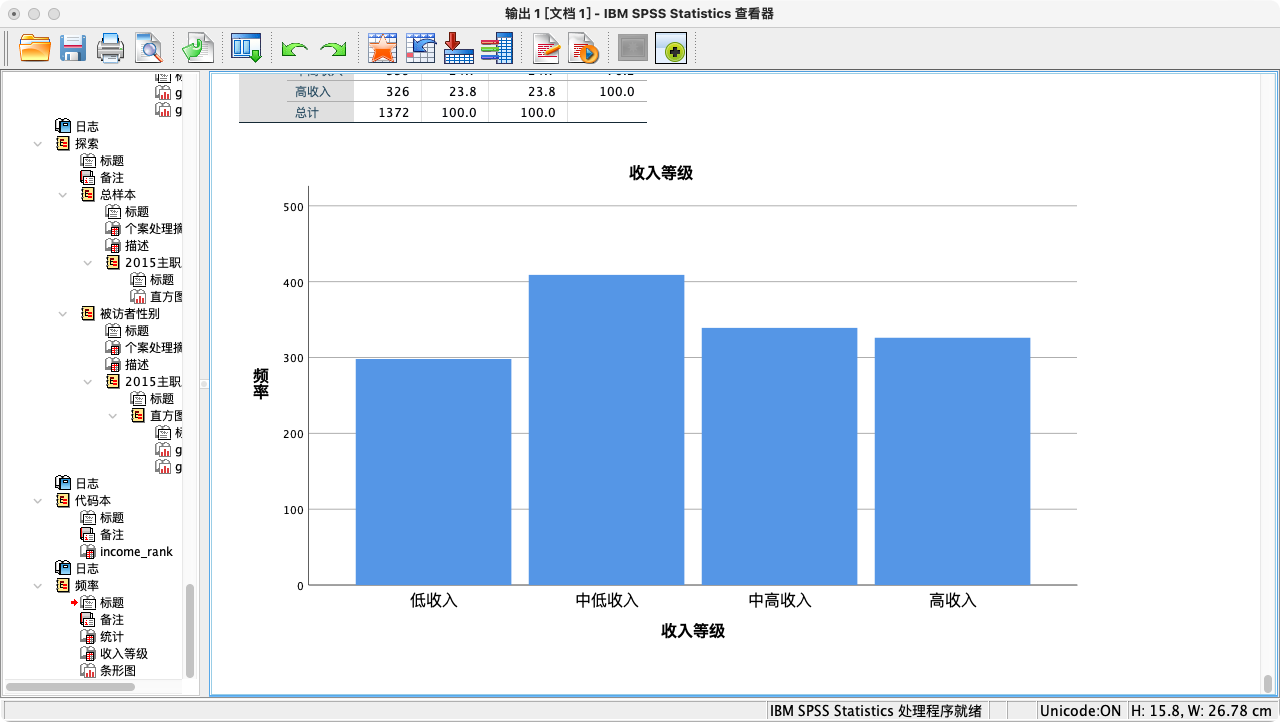
* 生成频数表和条形图.
FREQUENCIES VARIABLES = income_rank
/BARCHART PERCENT.
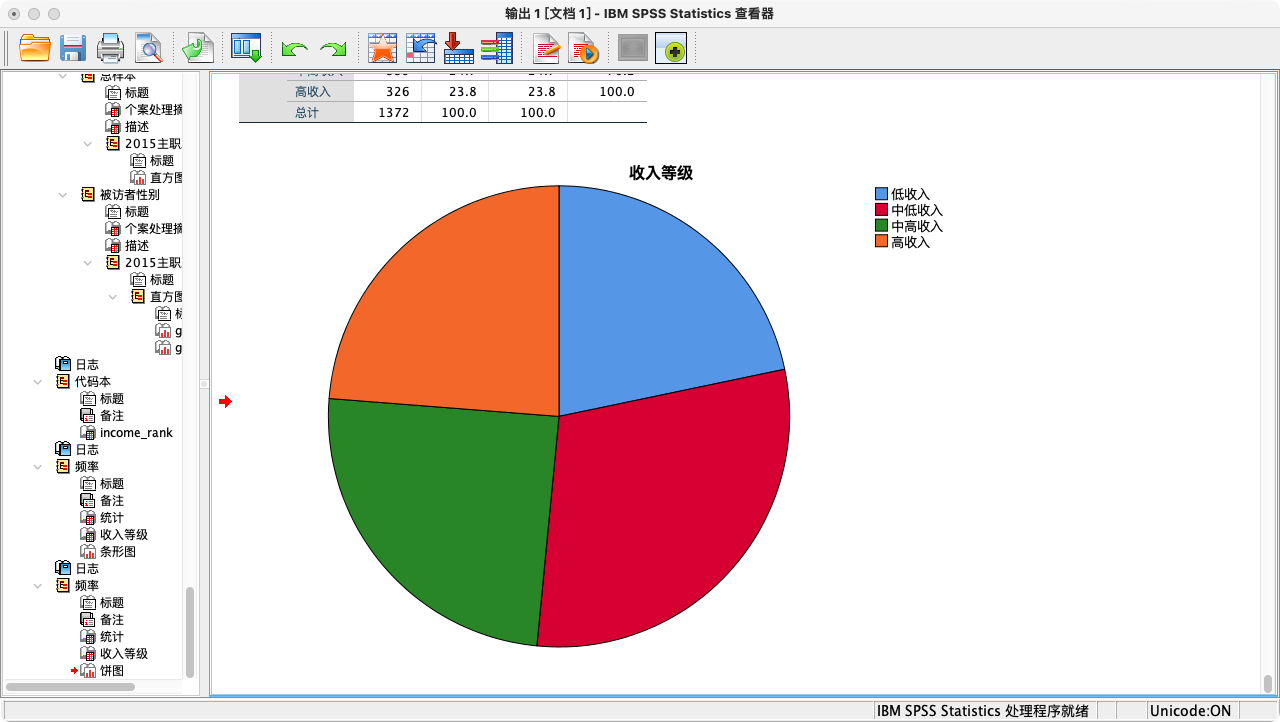
* 生成频数表和饼图.
FREQUENCIES VARIABLES = income_rank
/PIECHART PERCENT.
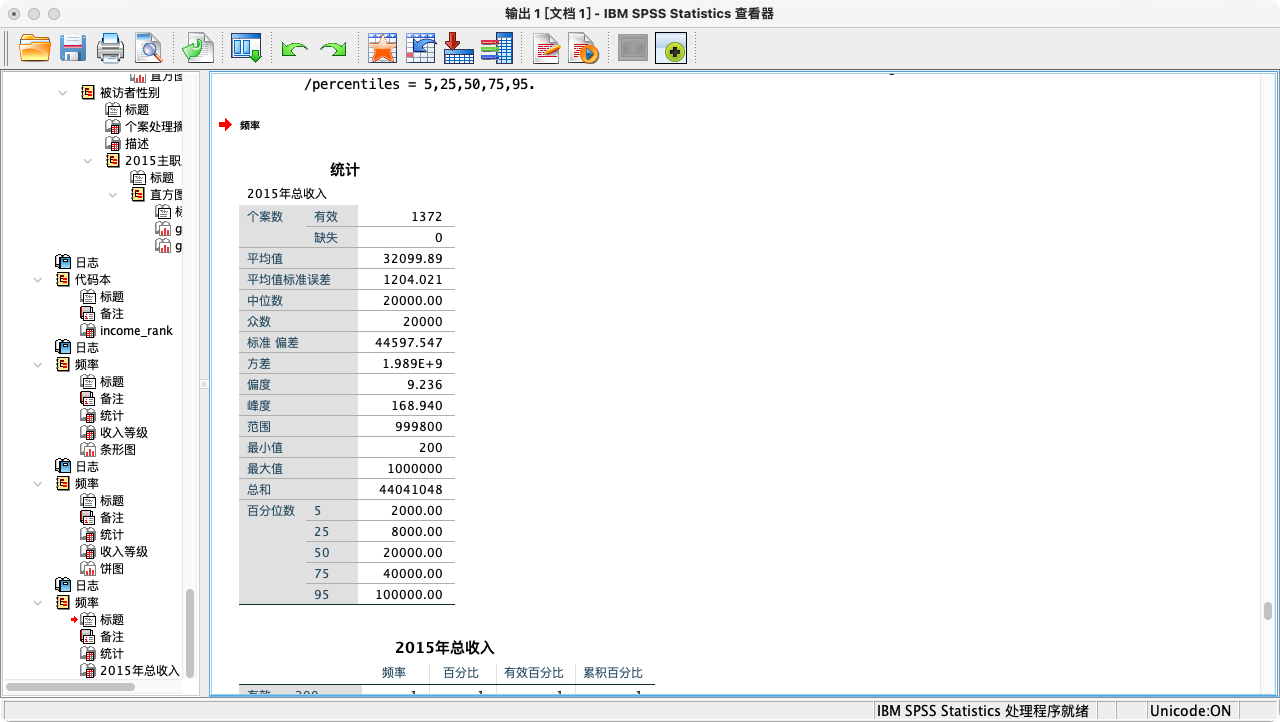
- 第三步:对原始的连续收入变量计算详细统计量。
FREQUENCIES VARIABLES = income
/FORMAT = NOTABLE /* 这个选项可以禁止输出冗长的频数表 */
/STATISTICS = MEAN SEMEAN MEDIAN MODE STDDEV VARIANCE SKEWNESS KURTOSIS RANGE MINIMUM MAXIMUM
/PERCENTILES = 10 25 50 75 90. /* 计算10%, 25%等分位数 */
EXECUTE.
- 结果解读:
SKEWNESS(偏度) 和KURTOSIS(峰度) 描述了数据分布的形状是否对称、是否陡峭。百分位数则告诉我们,例如,有10%的人收入低于多少,有90%的人收入低于多少,这对于理解收入分布的结构非常有帮助。
3. 交叉分析 (Crosstabs)
- 交叉表 (Crosstabulation),也称作列联表,是用来分析两个或多个分类变量之间关系的核心工具。它通过一个二维(或多维)表格,同时展示变量各个类别的频数分布。
- 点选操作:分析 → 描述统计 → 交叉表 → 填入”行”或”列” → 填入统计量等 → 继续 → 确定
- 语法操作:
*通用格式.
CROSSTABS
/TABLES = var1 BY var2 [BY var3 ...]
/FORMAT = [表格格式选项]
/CELLS = [单元格内容选项]
/STATISTICS = [统计量选项]
/MISSING = [缺失值处理方式].
- 语法说明
/TABLES = row_var BY col_var [BY layer_var]这是命令的核心部分,用于定义交叉表的结构。row_var: 指定放在表格行位置的变量。col_var: 指定放在表格列位置的变量。layer_var: (可选) 指定一个分层变量。SPSS会为该变量的每一个取值,都生成一张独立的二维交叉表。- 分析惯例:通常,我们将因变量放在行,将自变量放在列。
/CELLS用于定义交叉表每个单元格中需要显示哪些信息。COUNT: 显示观测频数 (默认)。ROW: 显示行百分比。COLUMN: 显示列百分比。TOTAL: 显示总百分比。EXPECTED: 显示期望频数 (用于卡方检验)。RESID: 显示残差 (观测频数 - 期望频数)。SRESID: 显示标准化残差。ASRESID: 显示调整后标准化残差。NONE: 不显示任何单元格内容 (不常用)。- 可以同时选择多个选项,例如
/CELLS = COUNT COLUMN.。
/STATISTICS用于请求计算各种衡量变量间关联强度的统计量。CHISQ: 卡方检验 (Chi-square)。这是最重要的选项,用于检验两个变量之间是否存在统计上的显著关联。它还会附带报告Phi系数和Cramer’s V系数,这两个是衡量关联强度的指标。- 定序变量适用:
GAMMA(伽马系数),KENDALL(肯德尔tau-b/c),SOMERSD(萨默斯d)。 - 定类变量适用:
LAMBDA(兰布达系数),UC(不确定性系数)。 CORR: 计算皮尔逊相关系数 (仅适用于两个变量均为有序或二分变量的情况)。- 可以同时选择多个选项,例如
/STATISTICS = CHISQ GAMMA.。
/MISSING定义如何处理含有缺失值的个案。TABLE: 仅当个案在/TABLES子命令中指定的变量上都有有效值时,才将其纳入分析 (默认)。INCLUDE: 将用户自定义的缺失值也视为一个有效的类别,包含在表格中。REPORT: 在输出中报告缺失值的数量,但不纳入统计计算。
关键解读:行百分比 vs. 列百分比 这是解读交叉表时最关键也最容易混淆的地方。请记住这个原则:沿着自变量的方向计算百分比。
- 如果自变量放在列,那么我们应该看列百分比 (COLUMN)。这能告诉我们,在自变量的不同类别下,因变量的分布是如何变化的。
- 如果自变量放在行,那么我们应该看行百分比 (ROW)。
案例(3-1):分析党员身份与收入等级的关系
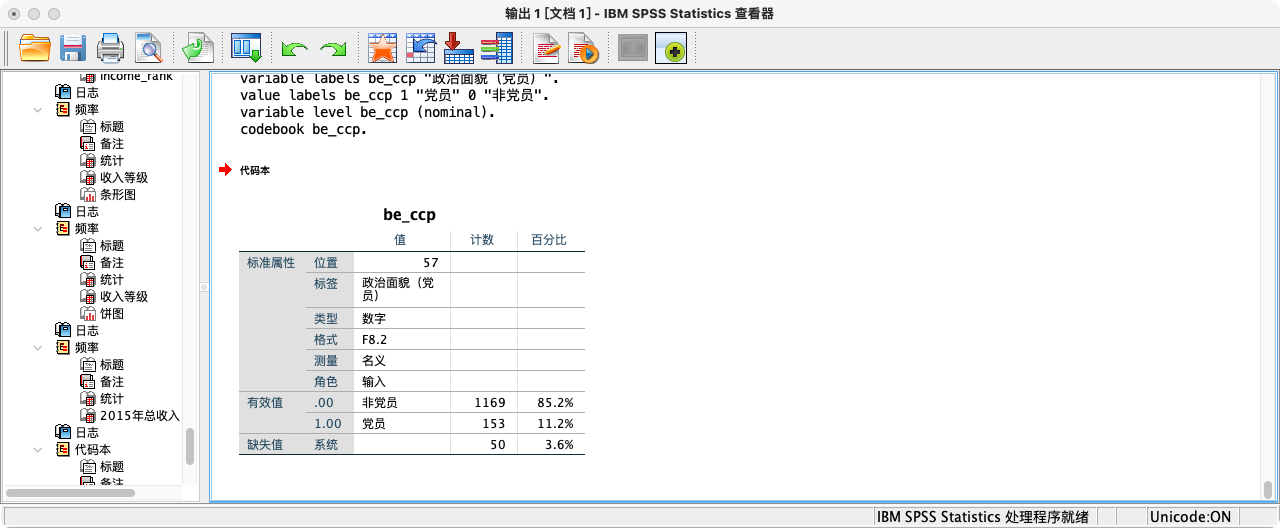
- 第一步:准备党员身份变量。
- 将原始的政治面貌变量
I1_6重新编码为 “党员” vs “非党员” 的二分类变量。
- 将原始的政治面貌变量
* 原始 I1_6 变量: 1=党员, 2=团员, 3=民主党派...
RECODE I1_6 (1=1) (2 THRU 13=0) (ELSE=SYSMIS) INTO be_ccp.
VARIABLE LABELS be_ccp "政治面貌 (1=党员)".
VALUE LABELS be_ccp 1 "党员" 0 "非党员".
VARIABLE LEVEL be_ccp (NOMINAL).
CODEBOOK be_ccp.
EXECUTE.
- 第二步:生成交叉表,并进行分析。
- 我们想看“党员身份”这个自变量是否会影响“收入等级”这个因变量。
- 因此,我们将
income_rank放行,be_ccp放列,并请求计算列百分比和卡方检验。
CROSSTABS
/TABLES = income_rank BY be_ccp.
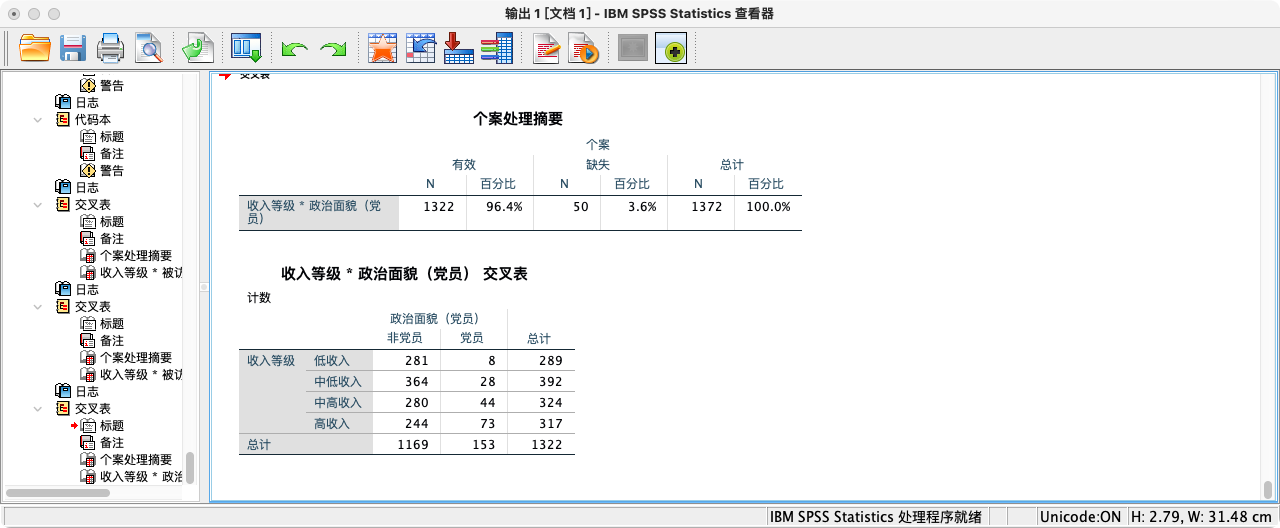
- 探索三维关系
- 我们还可以在关系中加入第三个控制变量,例如“性别”,来观察党员身份与收入的关系是否在男性和女性中有所不同。
* 生成按性别分层的交叉表.
CROSSTABS
/TABLES = income_rank BY be_ccp BY gender.
EXECUTE.
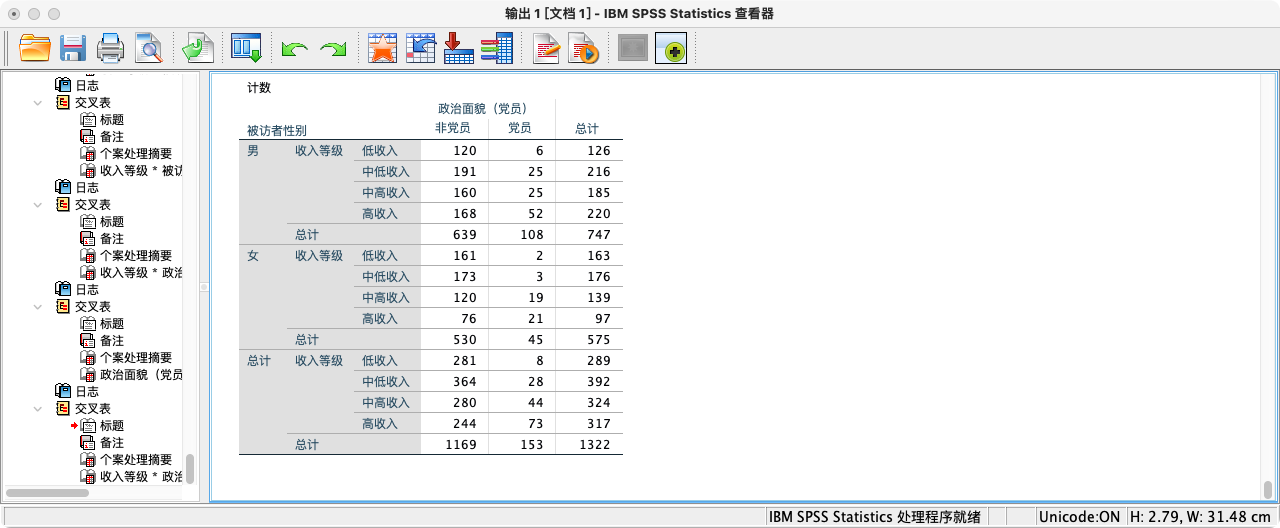
- 按党员身份查看个人总收入等级人数占比
- 我们还可以在关系
CROSSTABS
/TABLES = income_rank by be_ccp
/CELLS = column
/STATISTICS = chisq.
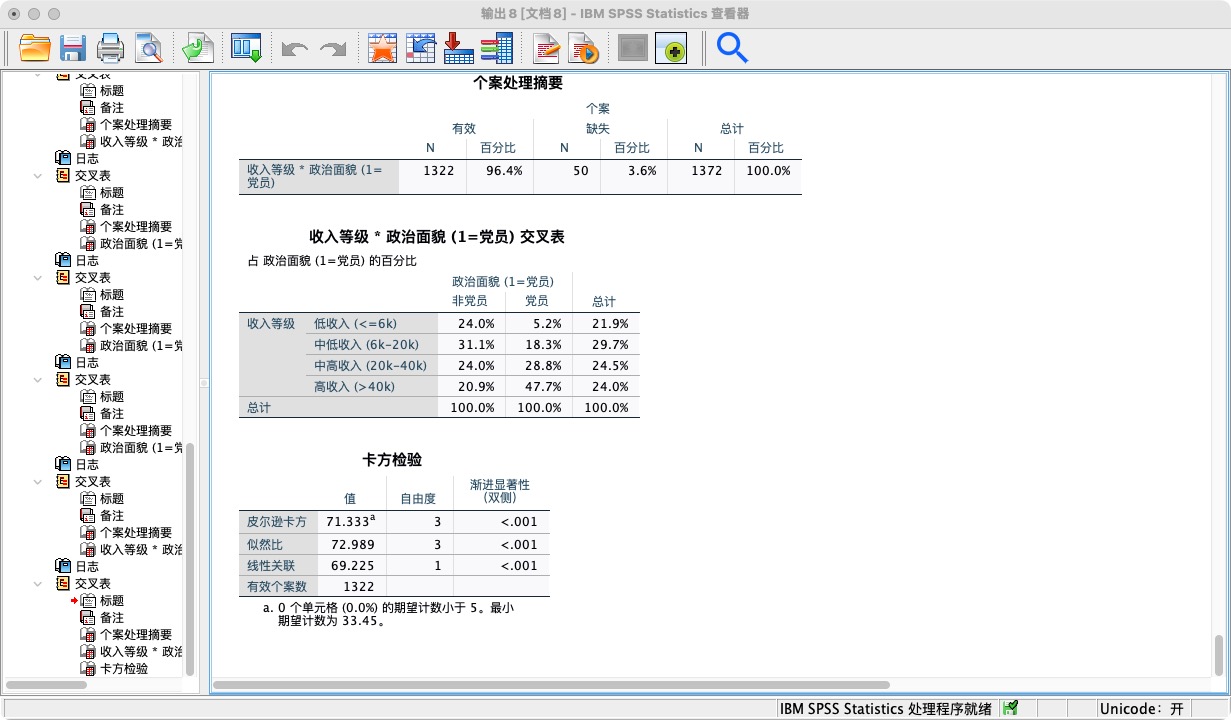
- 结果解读
- 查看列百分比:比较“党员”这一列和“非党员”这一列的百分比分布。例如,党员中处于“高收入”等级的百分比,是否显著高于非党员中处于“高收入”等级的百分比。
- 查看卡方检验结果:在“卡方检验”表中,查看“皮尔逊卡方”一行的“渐进显著性(双侧)” (Asymptotic Significance) 值。如果这个值小于0.05,我们通常认为党员身份和收入等级之间存在统计上的显著关联。
随堂练习:描述政治面貌、劳动年龄段与总收入等级的关系。
- 变量要求
- 政治面貌:党员 vs 非党员。
- 劳动年龄段:青壮年(18-35岁)、中年(36-50岁)、中老年(51-65岁)。
- 总收入等级:按四分位数(quartiles)将总收入划分为4个等级。
练习参考答案
* 步骤一:准备所需的所有变量(年龄段、收入四分位等级). * 政治面貌变量 be_ccp 已在案例中创建. COMPUTE age = 2016 - birthyear. RECODE age (18 THRU 35=1) (36 THRU 50=2) (51 THRU 65=3) (ELSE=SYSMIS) INTO age_group. VALUE LABELS age_group 1 "青壮年" 2 "中年" 3 "中老年". * 使用 NTILES(4) 将收入划分为四个等级. FREQUENCIES VARIABLES=I3a_6 /NTILES=4. * 假设上面命令得到的25%, 50%, 75%分位数分别是 5000, 15000, 35000 (此处为示例数值). RECODE I3a_6 (LO THRU 5000=1) (5000.01 THRU 15000=2) (15000.01 THRU 35000=3) (35000.01 THRU HI=4) INTO income_quartile. VARIABLE LABELS income_quartile "收入四分位等级". * 步骤二:使用交叉表进行分析. * 观察在不同年龄段中,党员与非党员的收入等级分布. CROSSTABS /TABLES = income_quartile BY be_ccp BY age_group /CELLS = COLUMN /STATISTICS = CHISQ. EXECUTE.
Disqus comments are disabled.