第六讲 专题研究:当代中国的社会不平等
Last updated: Sep 13, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 理解基尼系数
- 基尼系数 (Gini Coefficient) 是意大利统计学家基尼 (Corrado Gini) 在1912年提出的一种核心指标,用于衡量一个国家或地区居民收入分布的差异程度,是衡量社会不平等度的重要工具。

- 基尼系数的内涵
- 它通过一个简洁的数字(取值在0到1之间),概括了收入在全体人口中的分配情况。
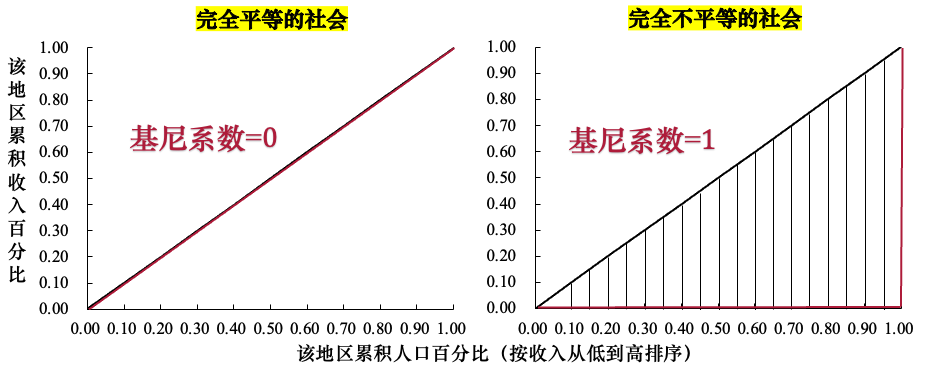
- 基尼系数为 0,代表完全平等。可以想象一个社会,其中每个人的收入都完全相同,没有任何差异。
- 基尼系数为 1,代表完全不平等。可以想象一个极端社会,其中一个人占有了所有的社会财富,而其他所有人收入为零。
- 现实社会总是处于这两个极端之间。基尼系数的数值越大,表明该地区的收入不平等程度越高。
2. 基尼是如何构想出基尼系数的?
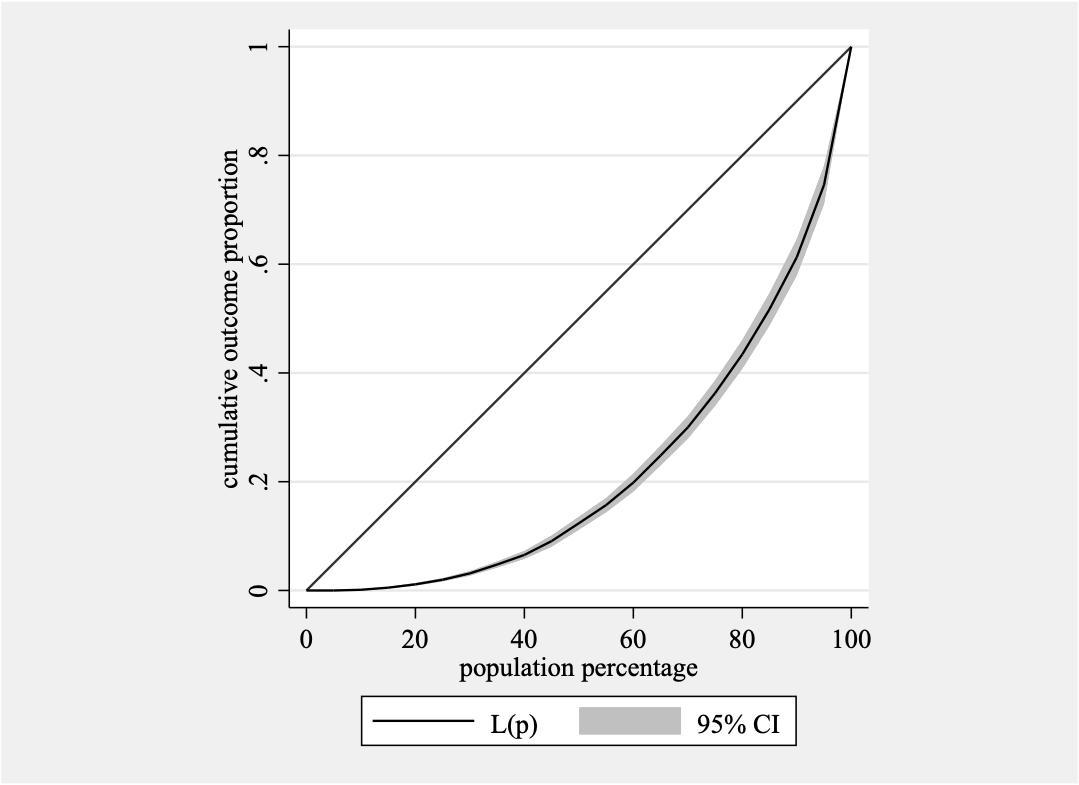
- 基尼系数的构想,建立在美国统计学家劳伦兹 (Max Lorenz) 提出的劳伦兹曲线 (Lorenz Curve) 之上。
- 劳伦兹曲线是一个描述人口累计百分比和收入累计百分比之间关系的图形。
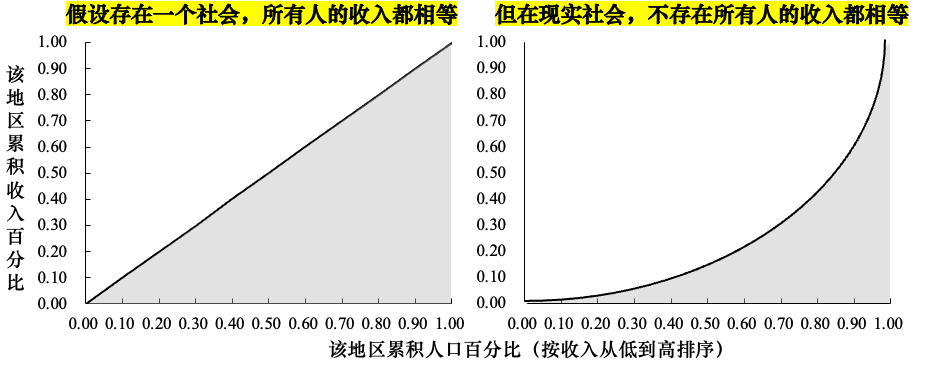
- 在一个坐标系中
- 绝对平等线 (Line of Perfect Equality):一条45度角直线。它表示“x%的人口”拥有“x%的社会财富”。例如,10%的人口拥有10%的财富,50%的人口拥有50%的财富。这是收入分配最平等的状态。
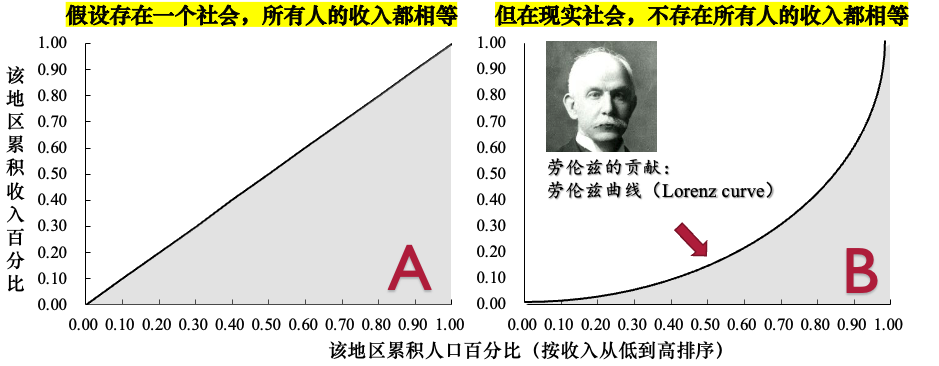
- 劳伦兹曲线 (Lorenz Curve):将社会中所有人口按收入从低到高排序后,绘制出的“人口累计百分比”与他们所拥有的“收入累计百分比”的关系曲线。在现实中,这条线总是弯向右下方的,因为低收入人口占有的财富比例总是低于其人口比例。
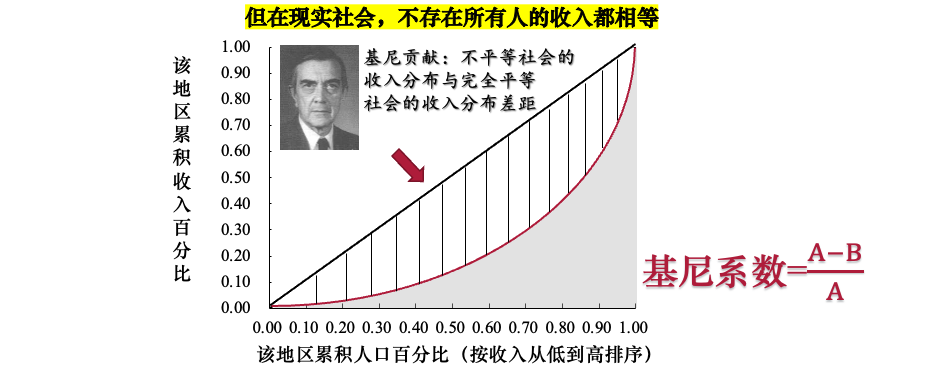
- 基尼系数的计算
- (1)基尼系数在几何上被定义为:绝对平等线与劳伦兹曲线所围成的面积(A-B),占绝对平等线与坐标轴所围成的总面积A 的比例。
- (2)由于总面积A恒为0.5,所以基尼系数也可以表示为
Gini = A-B / 0.5。
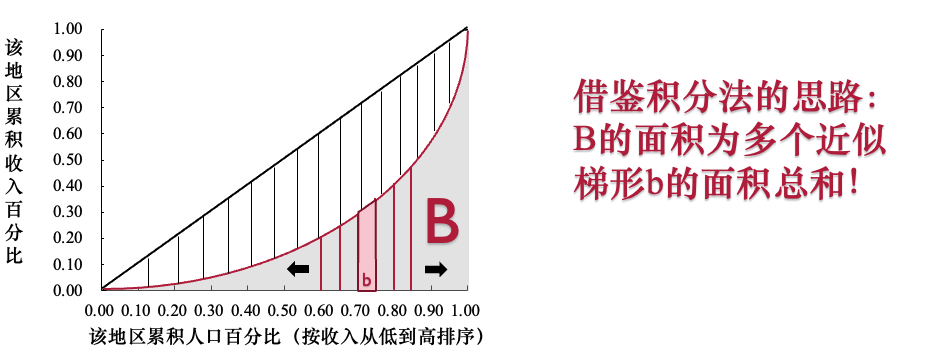
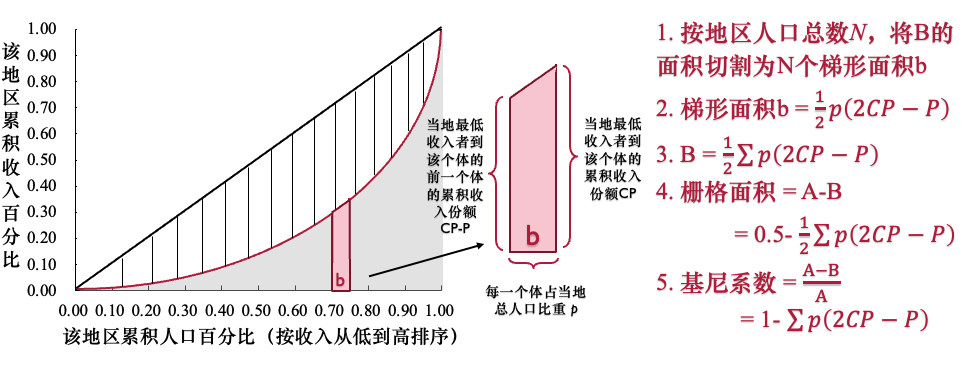
- (3)面积A越大,表示劳伦兹曲线偏离绝对平等线越远,即收入分配越不平等,基尼系数也越大。
3. 全球比较下的基尼系数
-
联合国开发计划署 (UNDP) 提供了一个普遍接受的参考标准
- < 0.2:收入绝对平均,不平等状况极低。
- 0.2 - 0.3:比较平均,不平等状况较低。
- 0.3 - 0.4:相对合理,不平等状况中等。
- 0.4 - 0.5:差距较大,不平等状况较高。
- > 0.5:差距悬殊,不平等状况极高。
-
通常,0.4 被视为收入分配差距的“警戒线”。
-
世界各个国家和地区的基尼系数
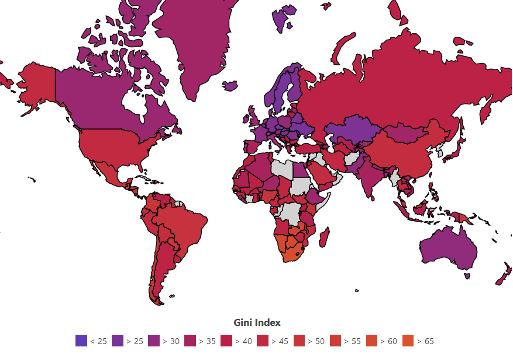
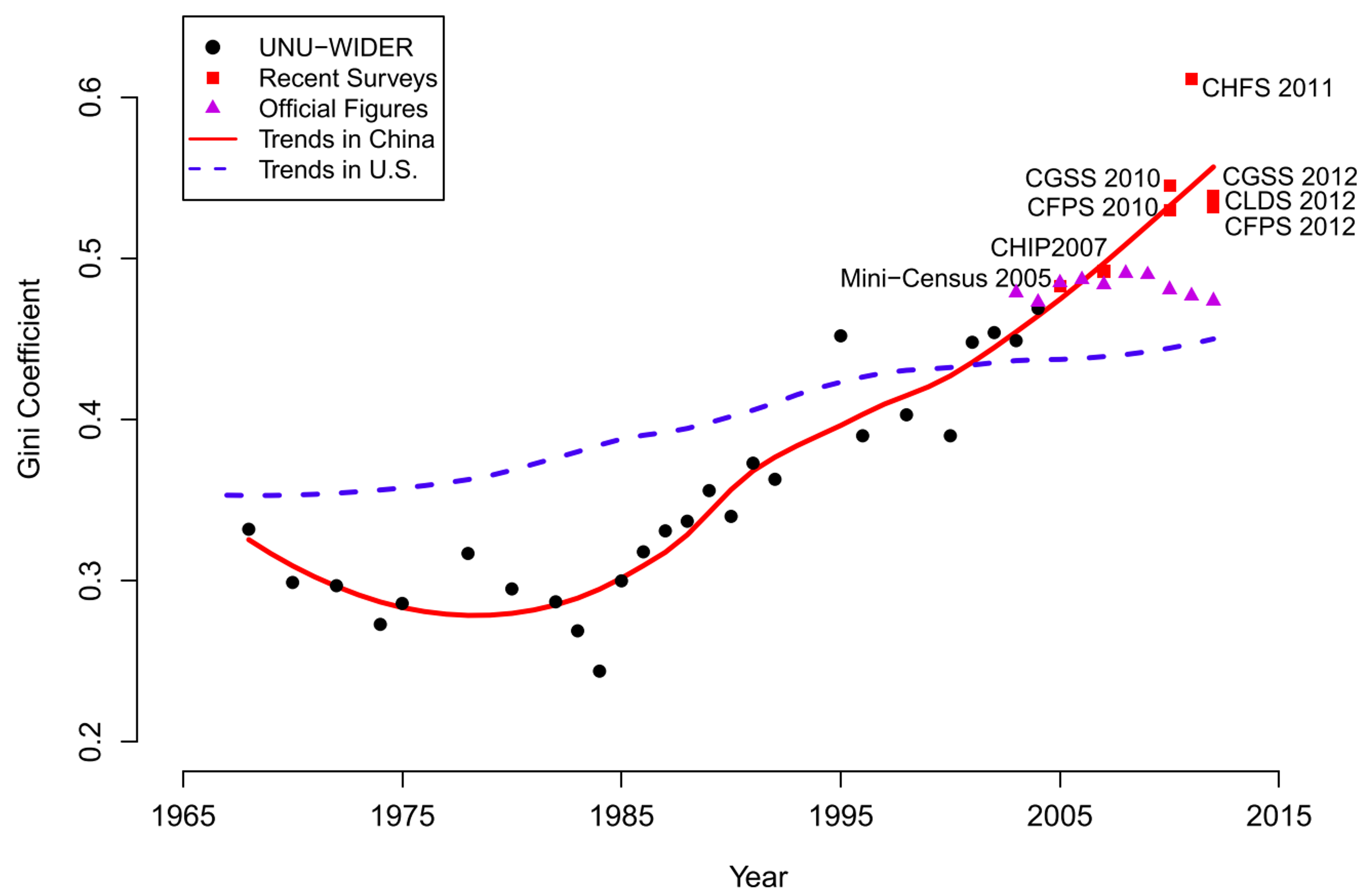
- 中国的基尼系数:根据学术研究(如 Xie & Zhou, 2014, PNAS),中国的基尼系数在改革开放后经历了快速上升,近年来一直处于较高水平。
4. 在SPSS中计算收入基尼系数
- 计算前的准备工作
- 变量类型:用于计算的变量必须是定距或定比变量(如收入、财富、教育年限)。
- 负数处理:基尼系数的计算不接受负值。必须筛选掉或处理好收入为负的个案。
- 缺失值处理:必须排除缺失值个案。
- 基尼系数的计算公式与SPSS实现思路 我们将介绍两种等价的计算方法。
- 方法一:基于累积份额的公式 $$ G = 1 - \sum_{k=1}^{N} (p_k \cdot (2 \cdot CP_k - P_k)) $$ 其中,\(N\)是总人口, \(p_k\)是每个人的权重(通常是1/N), \(P_k\)是每个人的收入占总收入的份额, \(CP_k\)是按收入排序后,到第k个人的累积收入份额。
- 方法二:基于排序的布朗公式 (Brown Formula) $$ G = \left| 1 - \frac{2}{N-1} \sum_{k=1}^{N} \frac{N-k+1}{N} \cdot \frac{y_k}{\bar{y}} \right| $$ 一个更便于程序计算的简化形式是: $$ G = \frac{2 \sum_{i=1}^{N} i \cdot y_i}{N \sum_{i=1}^{N} y_i} - \frac{N+1}{N} $$ 其中,\(y_i\)是按升序排列后第\(i\)个人的收入,\(N\)是总人口。
5. SPSS实现:累积份额法
- 核心思路:先用
AGGREGATE命令计算出总体层面的统计量(总人数、总收入),并将其添加回每个个案,然后进行个体层面的计算。
* 步骤一:筛选出收入为非负数的有效个案.
SELECT IF (I3a_6 >= 0).
* 步骤二:按收入对个案进行升序排序.
SORT CASES BY I3a_6 (A).
* 步骤三:计算总人数,并将其作为新变量添加回每个个体.
AGGREGATE
/total_num "总样本量" = N.
EXECUTE.
* 步骤四:计算每个人的权重(p).
COMPUTE id_percent = 1 / total_num.
* 步骤五:计算总收入,并将其作为新变量添加回每个个体.
AGGREGATE
/total_income "总收入" = SUM(I3a_6).
* 步骤六:计算每个人的收入份额(P).
COMPUTE income_percent = I3a_6 / total_income.
* 步骤七:计算收入的累积份额(CP).
* CSUM函数需要数据预先排序,我们已在步骤二完成.
CREATE cum_income = CSUM(income_percent).
* 步骤八:应用基尼系数公式的求和部分,对所有人的计算部分求和,并得出最终基尼系数.
COMPUTE id_invert_gini = id_percent * (2 * cum_income - income_percent).
AGGREGATE
/invert_gini = SUM(id_invert_gini).
COMPUTE gini = 1 - invert_gini.
* 步骤九:汇报最终基尼系数.
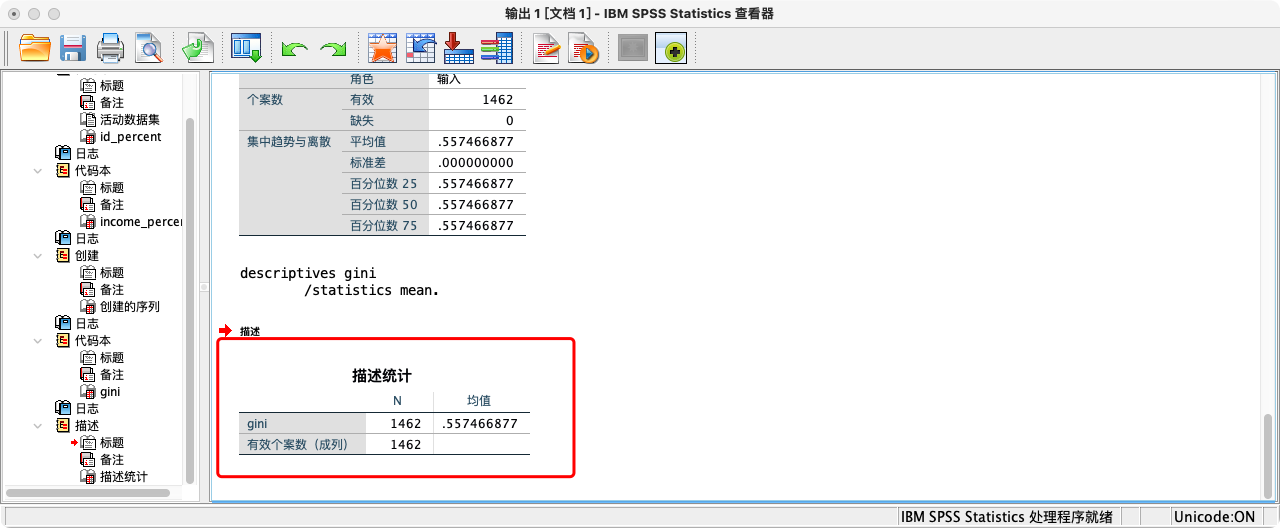
FORMATS gini (F10.8).
SUMMARIZE
/TABLES = gini
/FORMAT = VALIDLIST LIMIT=1.
EXECUTE.
辅助知识点:为何基尼系数最终会以每个个体的新变量取值的形式呈现?
在使用SPSS语法进行复杂指标(如基尼系数)的计算时,我们经常会遇到一个看似奇怪的过程:我们明明只想得到一个最终的数值(例如,基尼系数=0.55),但在计算过程中,我们却创建了许多新变量,并且像总人数、总收入这样的整体层面的统计量,会被赋值给数据集中的每一个个体(即出现在每一行)。
因为,逐行计算是统计软件计算指标或系数的常规方式!
SPSS处理数据转换命令(如COMPUTE)的基本方式是逐行处理。当你写下COMPUTE new_var = var1 / 10.时,SPSS会像一个勤劳但视野有限的工人,一行一行地读取var1的值,除以10,然后将结果存入当前行的new_var中。
这就带来一个根本性的问题:如果某一行的计算需要用到不属于这一行的信息(例如,需要用到整个数据集的总人数或总收入),该怎么办?在计算第一行时,这位“工人”并不知道整个数据集到底有多少行,也不知道所有人的收入加起来是多少。
为了解决这个问题,我们需要一个能提供“全局视野”的步骤,AGGREGATE命令正是扮演了这个角色。它的工作流程可以理解为:
第一步:聚合 —— 算出“全局信息”
AGGREGATE会暂时脱离“逐行”模式,像一位经理一样,“站得高看得远”,扫描整个数据集,计算出我们需要的摘要统计量(例如,总样本量 N,总收入 SUM(income))。
第二步:赋值 —— 将“全局信息”赋予每一行
然后,它会将这些计算出的“全局信息”,作为一个新的变量,“复制-粘贴”到原始数据集的每一行。
让我们通过一个简化的表格来理解这个过程:
原始数据:
ID Income 1 2000 2 5000 3 8000 运行
AGGREGATE /Total_N=N /Total_Income=SUM(income).之后…“赋值”后的数据:
ID Income Total_N Total_Income 1 2000 3 15000 2 5000 3 15000 3 8000 3 15000 “赋值”的意义
一旦这个过程完成,奇妙的事情就发生了:现在,当SPSS回到逐行计算的模式时,每一行都同时拥有了个体层面的私有信息(自己的Income)和全局层面的公共信息(Total_N 和 Total_Income)。 这使得原本不可能的计算变得轻而易举。例如,现在我们可以轻松地使用COMPUTE命令来计算每个人的收入份额,因为在计算每一行时,所需的所有信息(income 和 Total_Income)都已经“准备就绪”了,可以利用公式算出最后的基尼系数。
初学者可以边计算,边对照着数据视图新创建的变量,来理解整个计算过程,把握统计软件逐行计算的本质!
6.个案摘要SUMMARIZE
SUMMARIZE命令是SPSS中一个功能强大的、面向语法的报告生成工具。它的核心功能是创建个案摘要 (Case Summaries) 报告,可以灵活地展示数据集中指定变量的原始值,并能按照分组进行简单的统计汇总。SUMMARIZE与LIST和DESCRIPTIVES的区别LIST: 是最简单的命令,它只是将变量的原始值“倾倒”到输出窗口,格式控制非常有限。DESCRIPTIVES: 用于计算变量的整体描述统计量(如均值、标准差),但不显示单个个案的原始值。SUMMARIZE: 介于两者之间。它既可以像LIST一样展示个案的原始值,又可以像DESCRIPTIVES一样计算分组统计量,并且提供了比LIST更丰富的格式化选项,能生成更美观、更具可读性的报告。
- 语法操作:
SUMMARIZE
/TABLES = var1 var2 ... [BY group_var1] [BY group_var2 ...]
/FORMAT = [格式选项]
/TITLE = '报告标题'
/FOOTNOTE = '报告脚注'
/CELLS = [单元格内容].
语法说明
/TABLES = varlist [BY group_varlist]- 这是命令的主体,用于定义报告的结构。
varlist: 指定要在报告中列出的一个或多个变量。BY group_varlist: (可选) 指定一个或多个用于分组的分类变量。SUMMARIZE会为每个组别生成摘要信息。
/FORMAT- 用于控制报告的整体格式,非常灵活。
VALIDLIST: 以逐个个案列表的形式显示报告。如果不指定,SUMMARIZE会默认计算并显示分组的统计摘要。NOCASENUM: 在VALIDLIST模式下,不显示行首的个案编号列,使报告更简洁。LIMIT = n: 这是一个非常有用的技巧,用于将输出限制为前n个个案。当只想查看数据的前几行以确认格式时,此选项非常高效。
/CELLS- 用于定义表格单元格中要显示的内容。
DEFAULT: 默认选项。在VALIDLIST模式下,它显示变量的原始值。在分组摘要模式下,它显示MEAN,STDDEV,N。- 可以指定多种统计量,如
MEAN,COUNT,SUM,VARIANCE,MEDIAN等。 FIRST: 这是一个特殊的关键字。它告诉SPSS,不要进行任何计算,只需显示当前数据集(或当前分组)中第一个个案在该变量上的数值。LAST: 与FIRST类似,显示最后一个个案的数值。
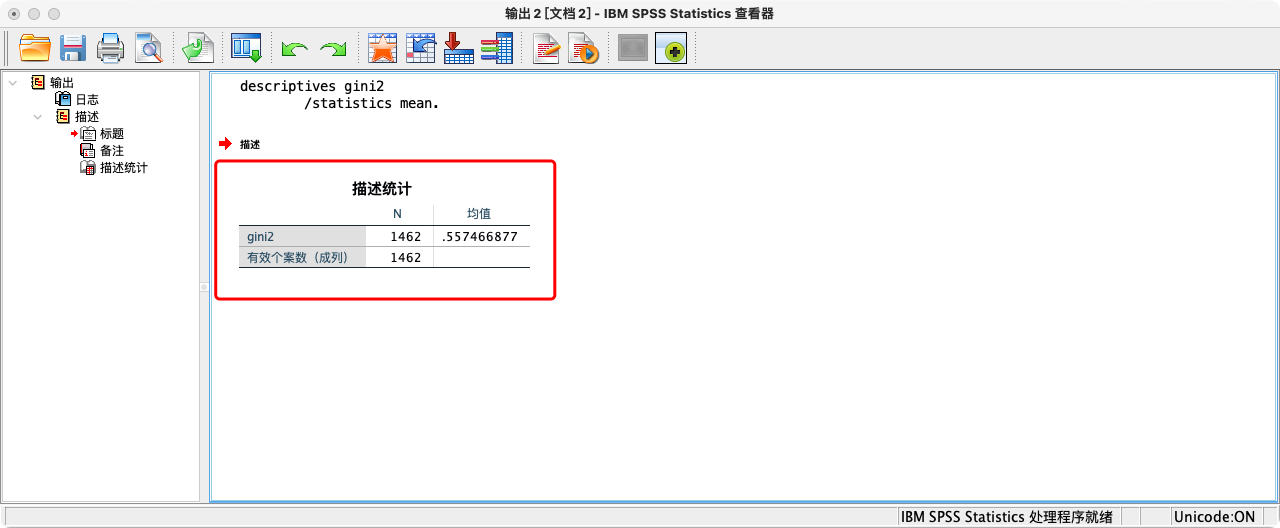
由于我们在计算基尼系数时,已把基尼系数赋值为每个个体的新变量取值(变量名为gini_method1),因此查看基尼系数的语法为:
SUMMARIZE
/TABLES = gini_method1
/FORMAT = VALIDLIST LIMIT=1.
7. SPSS实现:排序法
- 核心思路:该方法更直接,利用排序后的行号
($casenum)作为公式中的排序编号i。
* 准备工作:确保使用干净的原始数据.
DATASET ACTIVATE clds.
* 步骤一:筛选出收入为非负数的有效个案.
SELECT IF (I3a_6 >= 0).
* 步骤二:按收入对个案进行升序排序.
SORT CASES BY I3a_6 (A).
* 步骤三:计算所需的总体统计量和个体层面的加权值.
* 计算总样本量 N.
* 计算总收入 Sum(y).
* 计算加权收入 i * y_i.
COMPUTE case_num = $casenum.
COMPUTE weighted_income = case_num * I3a_6.
* 步骤四:一次性聚合所有需要的总和项.
* 使用 AGGREGATE 创建一个只包含最终结果的新数据集.
DATASET DECLARE gini_result.
AGGREGATE
/N = N
/Total_Income = SUM(I3a_6)
/Total_Weighted_Income = SUM(weighted_income).
EXECUTE.
* 步骤五:在新数据集中应用公式计算基尼系数.
COMPUTE gini2 = (2 * Total_Weighted_Income / (N * Total_Income)) - ((N+1)/N).
FORMATS gini2 (F10.8).
SUMMARIZE
/TABLES = gini2
/FORMAT = VALIDLIST LIMIT=1.
EXECUTE.
方法比较: 两种方法在数学上是等价的,计算结果应该非常接近。方法二在SPSS中的实现更为简洁高效。
随堂练习:计算教育年限的基尼系数
- 任务:使用
I2_1变量,先将其转换为教育年限,然后计算教育资源分配的基尼系数。 - 编码规则:
- 未上过学 -> 0年
- 小学/私塾 -> 6年
- 初中 -> 9年
- 普通高中/职业高中/技校/中专 -> 12年
- 大专 -> 15年
- 大学本科 -> 16年
- 硕士 -> 19年
- 博士 -> 22年
练习参考答案
DATASET ACTIVATE clds. * 步骤一:将学历重新编码为教育年限. RECODE I2_1 (1=0) (2=6) (3=9) (4 THRU 7=12) (8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS) INTO edu_year. VARIABLE LABELS edu_year "教育年限". * 步骤二:使用方法二计算教育年限的基尼系数. SELECT IF (edu_year >= 0). SORT CASES BY edu_year (A). COMPUTE case_num = $casenum. COMPUTE weighted_edu = case_num * edu_year. AGGREGATE /N = N /Total_Edu = SUM(edu_year) /Total_Weighted_Edu = SUM(weighted_edu). EXECUTE. COMPUTE gini_edu = (2 * Total_Weighted_Edu / (N * Total_Edu)) - ((N+1)/N). FORMATS gini_edu (F10.8). SUMMARIZE /TABLES = gini_method2 /FORMAT = VALIDLIST LIMIT=1. EXECUTE.
附注:使用Stata软件进行快捷计算
辅助知识点:专业软件的优势 虽然在SPSS中通过手动编写语法可以深入理解计算过程,但像Stata这类统计软件通常内置了专门的命令,可以一键完成劳伦兹曲线绘制和基尼系数计算,大大提高了效率。了解这些工具,可以让我们把更多精力放在结果的解读上。
- 以下为Stata命令,请勿在SPSS中运行。
- 读取数据
cd "/Users/ginglam/Public/data"
import spss using "clds2016_i.sav", clear
- 安装相关命令 (只需安装一次)
ssc install inequal7, replace
ssc install lorenz, replace
- 绘制劳伦兹曲线
lorenz I3a_6
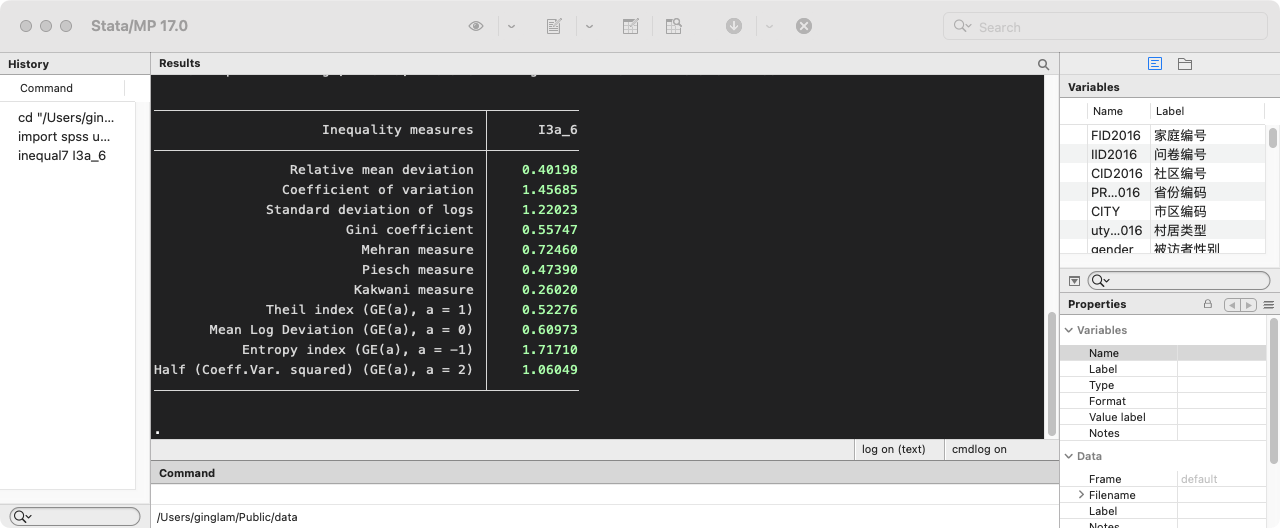
- 计算基尼系数及其他不平等指数
inequal7 I3a_6
Disqus comments are disabled.