第七讲 理解大数定律与中央极限定理
Publish date: Aug 1, 2021
Last updated: Sep 13, 2025
Last updated: Sep 13, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
专题说明:为何用SPSS结合Stata进行模拟?
辅助知识点: 大数定律和中央极限定理是统计推断的理论基石。为了直观地“看”到这两个定理如何运作,最好的方法就是进行计算机模拟——即反复、大量地从一个已知的“总体”中抽样。
- 在本节中,我们将2016年的CLDS调查数据视为我们的 “总体 (Population)”。我们将首先使用 SPSS 对这个“总体”进行数据清理和准备,计算出其真实的参数(例如,总体平均受教育年限)。然后,我们将使用 Stata 来完成核心的模拟环节。这是因为Stata的循环编程功能在执行成千上万次重复抽样和数据汇总这类任务时,语法更为简洁和高效。
第一部分:大数定律 (Law of Large Numbers)
1. 何谓大数定律?
- 原文定义:“The Law of Large Numbers states that larger samples provide better estimates of a population’s parameters than do smaller samples. As the size of a sample increases, the sample statistics approach the value of the population parameters."1
- 核心思想解读
- 大数定律告诉我们一个非常朴素但至关重要的道理:样本规模越大,样本得到的结果就越接近总体的真实情况。
- 可以想象一下品尝一锅汤的味道:只尝一小口,味道可能带有偶然性;但如果舀起一大碗(大样本)来尝,得到的味道就几乎肯定能代表整锅汤的真实味道了。
- 在社会调查中,我们之所以相信一个设计良好的千人样本能够反映数亿人的看法,其背后的理论支撑正是大数定律。它保证了抽样调查的可靠性。
2. 模拟大数定律
我们将通过模拟来验证:随着抽样比例的增加,样本的平均受教育年限与总体的平均受教育年限之间的差距是否会持续缩小。
- 以下为SPSS语法:数据准备
- 第一步:将学历变量 (
I2_1) 转换为连续的教育年限变量 (year_edu)
RECODE I2_1 (1=0) (2=6) (3=9) (4 THRU 7=12) (8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS) INTO year_edu.
VARIABLE LABELS year_edu "受访者教育年限".
VARIABLE LEVEL year_edu (SCALE).
EXECUTE.
- 第二步:筛选有效个案,排除教育年限的缺失值
SELECT IF (MISSING(year_edu) = 0).
EXECUTE.
- 第三步:计算“总体”的真实平均教育年限 (
pop_edu_mean)
* 这会将计算出的总体均值,作为一个新变量添加回数据集的每一行,便于后续在Stata中进行比较.
AGGREGATE
/pop_edu_mean = MEAN(year_edu).
EXECUTE.
- 第四步:保存处理好的数据,以供Stata使用
SAVE TRANSLATE OUTFILE = "simulation1/sample.dta"
/TYPE = Stata
/VERSION = 14
/EDITION = SE
/KEEP = IID2016 year_edu pop_edu_mean
/REPLACE.
- 以下为Stata命令:循环抽样与可视化
- 第一步:设置路径并读取由SPSS准备好的数据
* 定义一个路径的简写,方便后续调用
local path "/Users/ginglam/Public/data"
cd "`path'/simulation1"
use sample.dta, clear
- 第二步:编写循环程序,模拟不同规模的抽样
- 思路:我们写一个循环,让抽样比例从0.1%开始,每次增加0.1%,一直到100%。在每个比例下,我们都随机抽取一个样本,计算该样本的平均教育年限,并算出它与总体真实均值的差距。
* 这个循环会执行1000次 (从0.1到100,步长0.1)
foreach i of numlist 0.1(0.1)100 {
preserve // 临时保存当前数据状态
set seed 20200420 // 固定随机种子,确保结果可重复
sample `i' // 按 i% 的比例进行抽样
egen sam_edu_mean = mean(year_edu) // 计算样本均值
gen diff = abs(sam_edu_mean - pop_edu_mean) // 计算样本均值与总体均值的绝对差距
gen sample_prop = `i' // 记录当前的抽样比例
keep if _n == 1 // 每个循环只保留一条记录(差距和抽样比例)
save sample_`i'.dta, replace // 将这条记录存为临时文件
restore // 恢复到循环开始前的数据状态,准备下一次抽样
}
* 将1000个临时文件合并成一个最终结果文件
use sample_0.1.dta, clear
foreach i of numlist 0.2(0.1)100 {
append using sample_`i'.dta
}
save "edu_lln_result.dta", replace
- 第三步:将模拟结果可视化
twoway (lowess diff sample_prop) (scatter diff sample_prop, msize(tiny)), ///
title("大数定律模拟") ///
xtitle("抽样比例 (%)") ///
ytitle("样本均值与总体均值的差距") ///
legend(label(1 "拟合线") label(2 "散点"))
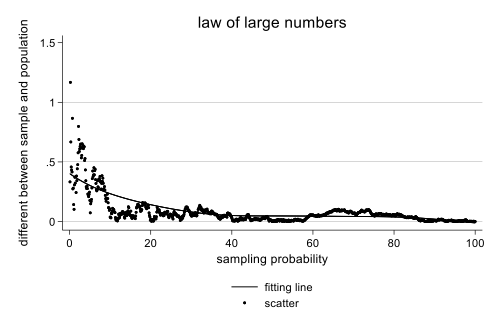
结果解读 从图中可以清晰地看到,当抽样比例(横轴)非常小时,样本均值与总体均值的差距(纵轴)波动很大,充满了不确定性。但随着抽样比例的不断增大,这个差距迅速且稳定地趋向于0。这正是大数定律的可视化证明。
第二部分:中央极限定理 (Central Limit Theorem)
3. 何谓中央极限定理?
- 原文定义:“This is a theorem that shows that as the size of a sample, n, increases, the sampling distribution of a statistic approximates a normal distribution even when the distribution of the values in the population are skewed or in other ways not normal."2
- 核心思想解读
- 中央极限定理是统计推断的灵魂。它揭示了一个惊人的规律:无论原始总体的分布形状如何(哪怕是极度偏态的),只要我们不断地从中抽取足够大的样本,这些样本的“均值”所形成的分布(我们称之为“抽样分布”)将自动趋向于一个正态分布(钟形曲线)。
- 定理还告诉我们两件事:
- 这个由样本均值构成的正态分布,其中心(均值)就等于总体真实的均值。
- 随着我们抽取的样本规模
n越来越大,这个正态分布会变得越来越“瘦高”,意味着样本均值会更紧密地围绕在总体均值的周围,估计也变得更精确。
4. 模拟中央极限定理
- 模拟思路
- 我们设定几种不同的样本规模
n(例如 n=5, n=30, n=100, n=500)。 - 对于每一种规模
n,我们重复进行500次独立的抽样。 - 每一次抽样,我们都计算出一个样本均值。这样,对于每个
n,我们都会得到500个样本均值。 - 最后,我们分别绘制这500个样本均值的分布图,观察其形状如何随着
n的增大而变化。
- 我们设定几种不同的样本规模
- 以下为Stata命令
* 定义路径
local path "/Users/ginglam/Public/data"
* 外层循环:改变样本规模 n (从5开始,每次增加100,直到2005)
foreach i of numlist 5 30 100 500 {
* 加载原始数据
use "`path'/simulation1/sample.dta", clear
* 为每个样本规模创建一个文件夹来存放临时文件
mkdir "`path'/simulation2/sample`i'"
cd "`path'/simulation2/sample`i'"
* 内层循环:对于给定的样本规模n,重复抽样500次
foreach j of numlist 1/500 {
preserve
set seed `j'2021 // 设置随机种子
sample `i', count // 按数量n=`i`进行抽样
egen sam_edu_mean = mean(year_edu) // 计算该样本的均值
keep if _n == 1 // 只保留含均值的一行
keep sam_edu_mean
save sample_`j'.dta, replace // 保存这个均值
restore
}
* 将500次抽样的均值合并起来
use sample_1.dta, clear
foreach k of numlist 2/500 {
append using sample_`k'.dta
}
* 绘制这500个样本均值的分布直方图,并叠加正态曲线
histogram sam_edu_mean, percent bin(20) kdensity ///
title("样本规模 n = `i', 重复500次") ///
xtitle("样本平均教育年限的分布")
* 导出图片
graph export "`path'/simulation2/graph_`i'.png", as(png) width(800) replace
graph close
}
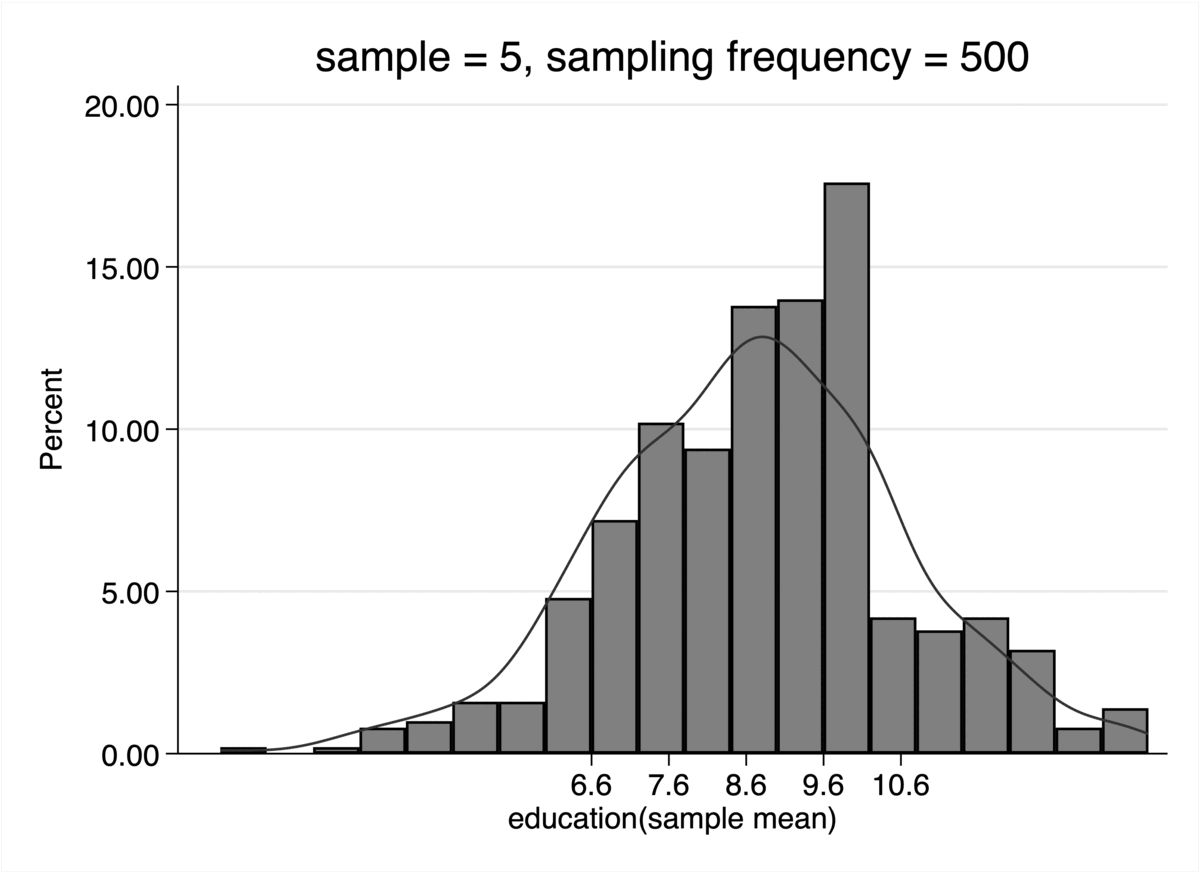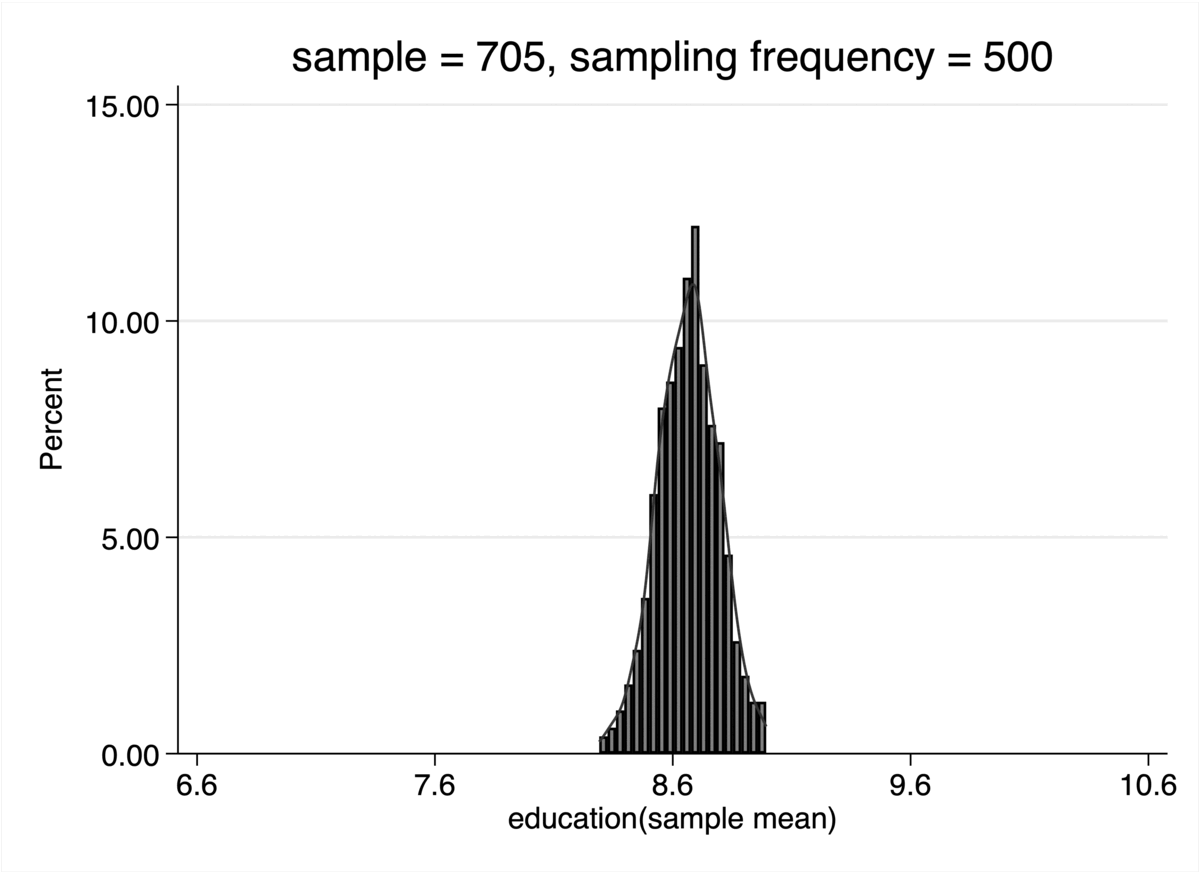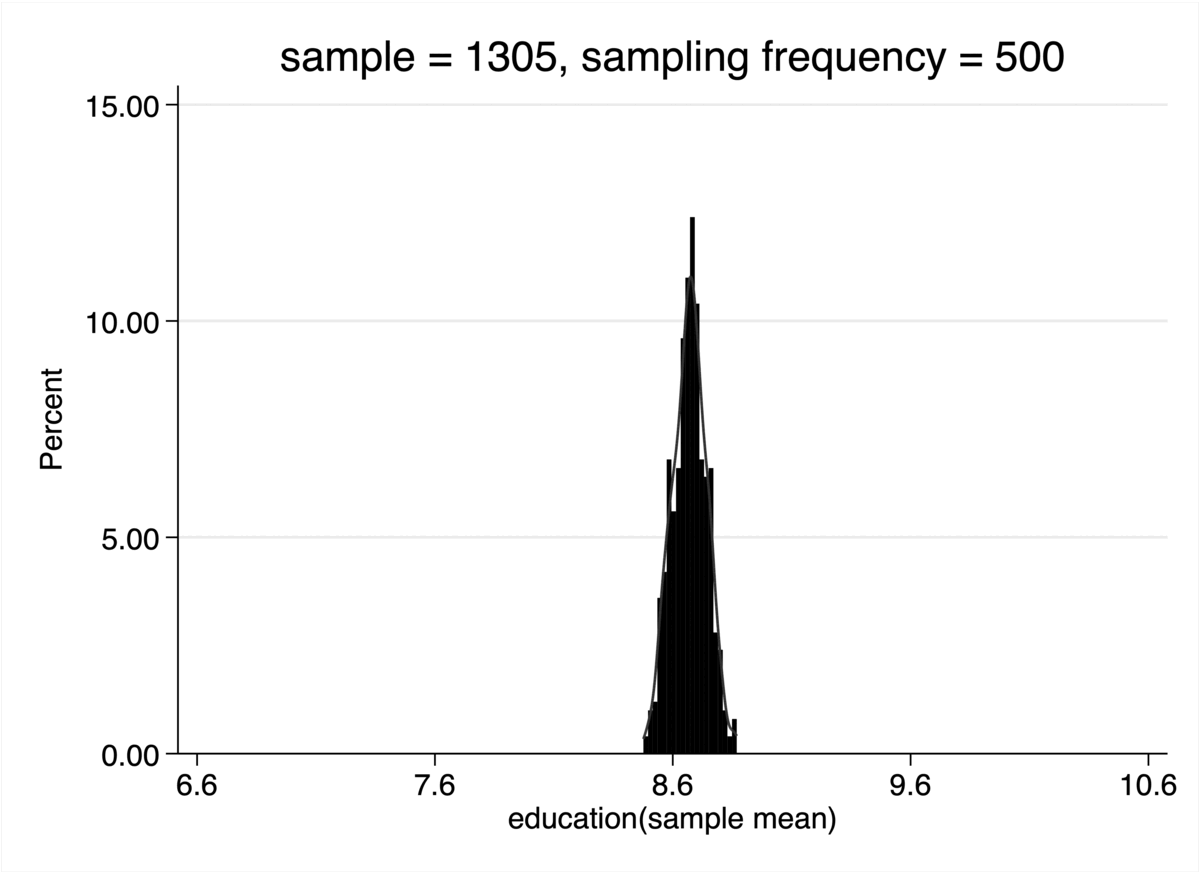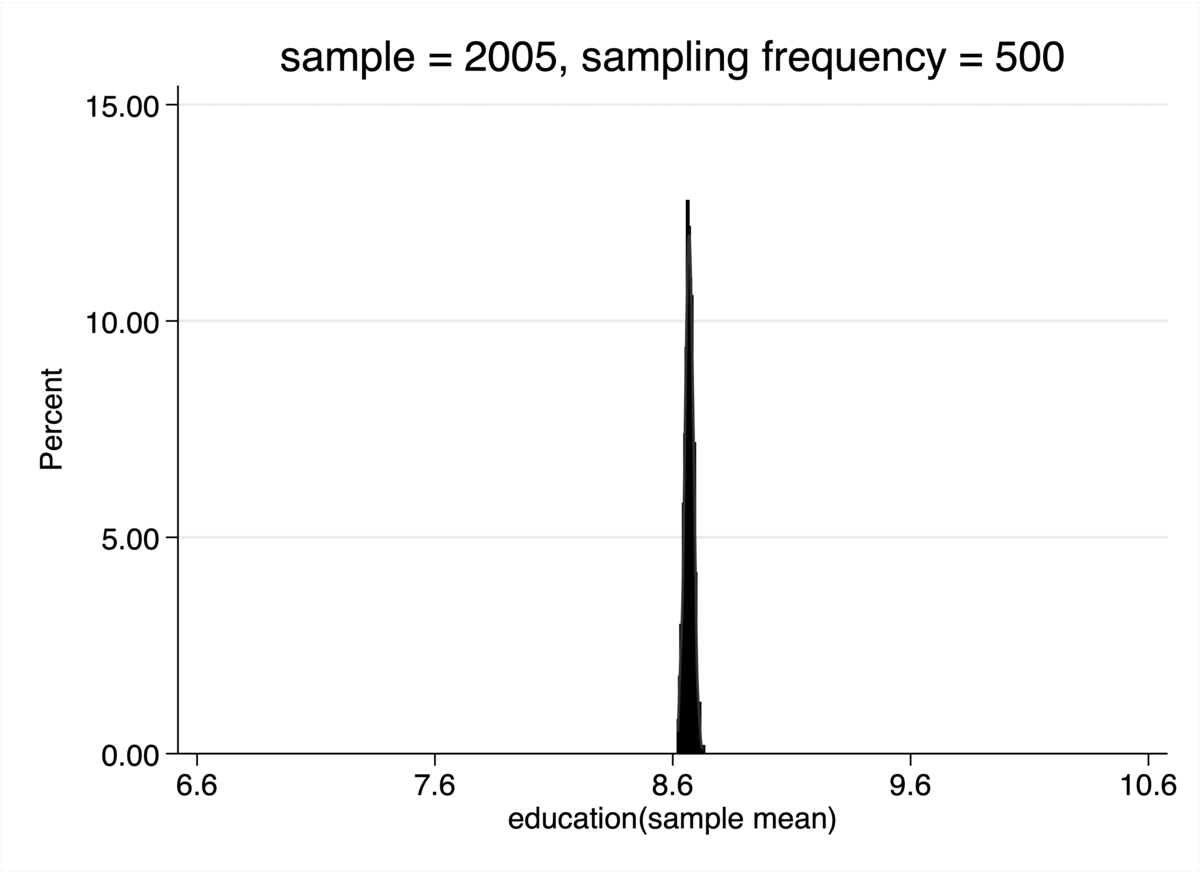
结果解读
中央极限定理的威力
- 当样本规模 n 很小 (如 n=5) 时,500个样本均值构成的分布还比较杂乱,看不出明显的形状。
- 当 n 逐渐增大 (如 n=30, n=100) 时,这个分布的形状越来越清晰地呈现为一个对称的钟形曲线——即正态分布。
- 同时,随着 n 的持续增大,这个钟形曲线变得越来越窄、越来越高,这表明样本均值的分布越来越集中在总体的真实均值附近,抽样的结果也越来越稳定可靠。
-
Lohmeier, J. (2010). Law of large numbers. In N. J. Salkind (Ed.), Encyclopedia of research design (pp. 704-705). SAGE Publications, Inc., https://dx.doi.org/10.4135/9781412961288.n215 ↩︎
-
Lewis-Beck, M. S., Bryman, A., & Futing Liao, T. (2004). Central limit theorem. In The SAGE encyclopedia of social science research methods (pp. 114-115). Sage Publications, Inc., https://dx.doi.org/10.4135/9781412950589.n108 ↩︎
Disqus comments are disabled.