第八讲 总体、样本与抽样分布
Last updated: Sep 18, 2025
核心概念梳理
辅助知识点
在学习统计推断前,我们必须清晰地辨别三个名字相似但意义迥异的概念。这三者的关系是整个统计推断的基石。
总体分布 (Population Distribution)
- 是什么? 指的是我们所研究的全体对象中,某个变量的真实分布情况。例如,中国所有劳动力的真实收入分布。
- 特点: 这是我们最想知道的,但通常是未知且不可得的。因为我们几乎不可能去测量每一个个体。它的参数(如总体均值 μ、总体标准差 σ)是固定但未知的常数。
样本分布 (Sample Distribution)
- 是什么? 指的是我们从总体中抽取出来的那一小部分数据中,某个变量的分布情况。例如,CLDS调查中几千名受访者的收入分布。
- 特点: 这是我们实际拥有的、看得见摸得着的数据。我们通过分析样本分布,来推断总体分布的样貌。它的统计量(如样本均值 X̄、样本标准差 s)是已知的,但每次抽样都可能不同。
抽样分布 (Sampling Distribution)
- 是什么? 这是一个理论上的、抽象的分布。想象我们从同一个总体中,反复抽取无数个大小相同(例如,n=200)的样本。每一个样本都会有一个自己的均值。把这无数个样本均值收集起来,它们自身就会形成一个分布,这个分布就叫做“均值的抽样分布”。
- 特点: 这是连接样本与总体的桥梁。中央极限定理告诉我们,这个分布近似于正态分布。它的标准差有一个特殊的名字,叫做标准误 (Standard Error)。我们正是利用抽样分布的这个性质,来判断我们的样本结果在多大程度上是可靠的,并据此构建置信区间。
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 管理输出查看器 (Output Viewer)
- 在进行大量分析时,保持输出结果窗口的整洁非常重要。
- 注意:SPSS的输出查看器没有“一键清空”按钮。一个有效的替代方法是关闭当前的查看器,再让SPSS自动生成一个新的。我们可以通过命名来管理它们。
* 给当前的输出窗口命名,方便后续引用.
OUTPUT NAME clds_output.
* 激活指定的输出窗口 (当打开多个窗口时有用).
OUTPUT ACTIVATE clds_output.
* 关闭指定的输出窗口,后续操作将自动打开一个干净的新窗口.
OUTPUT CLOSE clds_output.
2. 图表构建器 (GGRAPH 与 GPL)
- 图表构建器是SPSS中功能最强大的绘图工具,它允许用户通过图形化界面或专门的“图形生产语言 (Graphics Production Language, GPL)”来精细控制图表的每一个细节。
- 点选操作:图形 → 图表构建器 → 在图库中选择图形(如条形图、直线图、面积图、散点图和直方图等)并拖入空白处 → 在左侧变量列表中选择变量并拖入空白处 → 双击图表预览内容填入标题和坐标轴标签以及 → 在右侧栏目设置元素属性、图表外观及其他选项 → 确定
- 语法操作:
GGRAPH与GPL(Graphics Production Language) 共同构成了SPSS中最强大、最灵活的图形定制系统,其功能远超传统的图表命令。理解这套系统的逻辑,可以随心所欲地创造出符合出版要求的专业图表。 - 基本结构:
GGRAPH
/GRAPHDATASET NAME = "数据集" VARIABLES = 绘图变量名1(作为横轴) 绘图变量名2(作为纵轴,可以使用其统计量)
/GRAPHSPEC SOURCE = inline(即时绘图)或 /GRAPHSPEC SOURCE = gplfile("XXX.gpl")(读取模板).
BEGIN GPL
SOURCE: 绘图数据名 = userSource(id("数据集"))
DATA: 绘图变量名1 = col(source(绘图数据名), name("绘图变量名1"), unit.category()(表示分类变量,括号内无需填入内容))
DATA: 绘图变量名2 = col(source(绘图数据名), name("绘图变量名2"))
GUIDE: axis(dim(1), label("横轴名称"))
GUIDE: axis(dim(2), label("纵轴名称"))
GUIDE: text.title(label("标题名称"))
GUIDE: text.subtitle(label("副标题名称"))
GUIDE: text.footnote(label("脚注名称"))
SCALE: linear(dim(1), min(横轴下限), max(横轴上限))
SCALE: linear(dim(2), min(横轴下限), max(横轴上限))
ELEMENT: interval(position(绘图变量名1*绘图变量名2))
END GPL.
-
2.1 使用
GGRAPH和GPL的过程有三个步骤- 准备(
GGRAPH):首先需要决定这幅画要用到哪些数据(变量),以及是否需要对这些数据做一些初步的“调色”(如计算均值、计数等)。 - 规划 (
BEGIN GPL...END GPL.的SOURCE和DATA部分):需要明确定义画中的基本元素是什么,例如,“横轴代表分类变量‘地区’”、“纵轴代表连续变量‘收入’”。 - 绘制 (
BEGIN GPL...END GPL.的GUIDE,SCALE,ELEMENT部分):开始绘制具体的图形元素,比如“画一个条形图”、“画一条拟合线”、“给坐标轴加上标签”、“给图取个标题”等等。
- 准备(
-
2.2 两步结构详解
-
(1)
GGRAPH命令 —— 数据准备 -
功能:定义用于绘图的微型数据集,并指定要使用的变量。
GGRAPH
/GRAPHDATASET NAME="<数据集别名>" VARIABLES=<变量列表>
/GRAPHSPEC SOURCE=INLINE.
-
语法说明
/GRAPHDATASET NAME="<数据集别名>": 为本次绘图所用的数据指定一个临时的内部名称 (例如"graphdata")。这个名字将在后续的GPL部分被引用。VARIABLES=<变量列表>: 列出你想要在图中使用的一个或多个变量。- 可以直接使用变量名,如
gender income。 - 可以进行即时统计汇总,这是
GGRAPH最强大的功能之一。例如,MEAN(income)[NAME="mean_income"]表示“计算income变量的均值,并将这个计算结果命名为mean_income以便后续使用”。常用的函数还有COUNT(),SUM(),MEDIAN()等。
- 可以直接使用变量名,如
/GRAPHSPEC SOURCE=INLINE: 这是一个固定写法,表示绘图的具体指令将紧跟在GGRAPH命令之后(即BEGIN GPL...END GPL.部分)。
-
(2)
BEGIN GPL ... END GPL.代码块 —— 图形绘制 -
功能:使用图形生产语言 (GPL) 描述图形的每一个细节。
-
语法说明
-
SOURCE: <别名= userSource(id("<数据集别名>"))- 功能:声明一个数据源,并将其与
GGRAPH中定义的<数据集别名>关联起来。 - 示例:
SOURCE: s = userSource(id("graphdata"))
- 功能:声明一个数据源,并将其与
-
DATA: <变量名= col(source(<别名>), name("<变量名>"), [unit.category()])- 功能:从数据源中正式定义一个用于绘图的变量。
unit.category(): (可选) 这是一个重要的声明,用于告诉GPL这个变量是一个分类变量,应在坐标轴上离散地展示。对于连续变量则无需添加。- 示例:
DATA: gender = col(source(s), name("gender"), unit.category())
-
GUIDE:- 功能:定义所有的“引导性”元素,如图名、坐标轴标签、图例等。
axis(dim(1), label("<横轴标签>")): 定义X轴(维度1)的标签。axis(dim(2), label("<纵轴标签>")): 定义Y轴(维度2)的标签。title(label("<主标题>"))subtitle(label("<副标题>"))footnote(label("<脚注>"))
-
SCALE:- 功能:定义坐标轴的刻度范围和类型。
linear(dim(1), min(<下限>), max(<上限>)): 为X轴设置线性的刻度范围。cat(dim(1), ...): 为X轴设置分类的刻度 (可用于调整类别顺序等)。
-
ELEMENT:- 功能:这是最核心的部分,用于定义要在图上绘制的几何图形。
interval(...): 绘制区间图形,如条形图、直方图。point(...): 绘制点图形,如散点图。line(...): 绘制线图形,如折线图、拟合线。path(...): 绘制路径图。position(...): 在ELEMENT内部,position函数用于指定变量如何映射到图形的位置上。position(x*y)是最常见的二维图形映射方式。
-
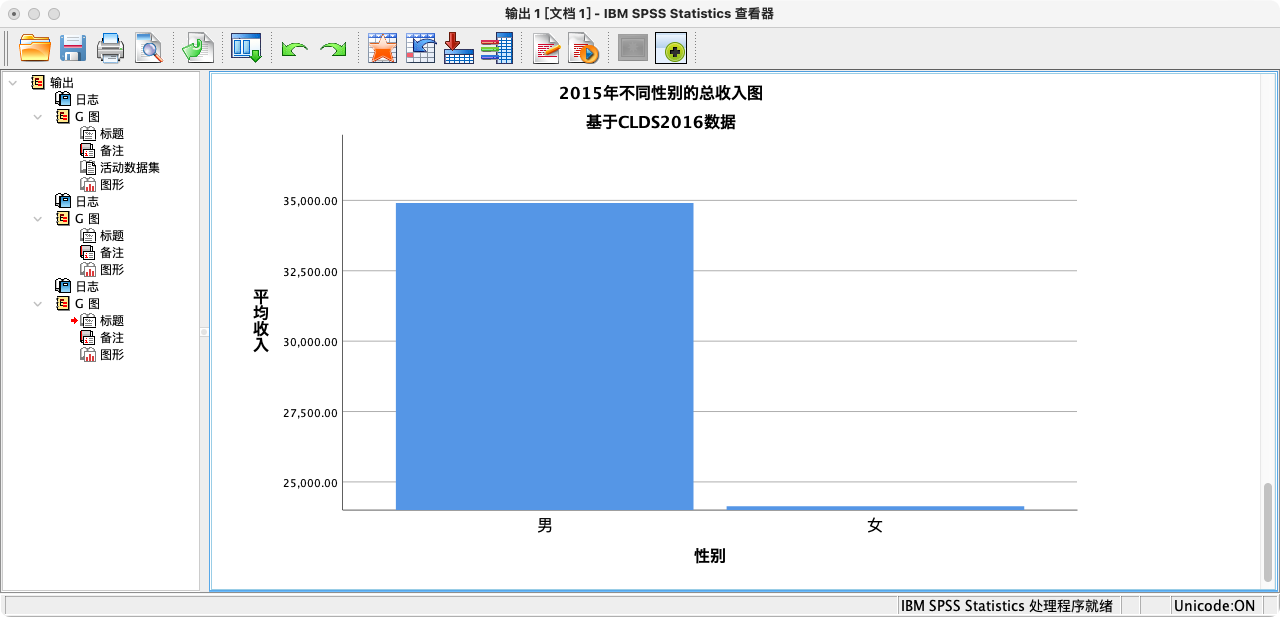
案例(2-1):绘制性别与平均收入的条形图
- 准备工作:筛选有效收入数据。
SELECT IF (I3a_6 >= 0).
COMPUTE income = I3a_6.
EXECUTE.
- 绘图语法
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES= gender MEAN(income)[NAME = "mean_income"]
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: clds=userSource(id("clds"))
DATA: gender=col(source(clds), name("gender"), unit.category())
DATA: mean_income=col(source(clds), name("mean_income"))
GUIDE: axis(dim(1), label("性别"))
GUIDE: axis(dim(2), label("平均收入"))
GUIDE: text.title(label("2015年不同性别的总收入图"))
GUIDE: text.subtitle(label("基于CLDS2016数据"))
ELEMENT: interval(position(gender*mean_income))
END GPL.
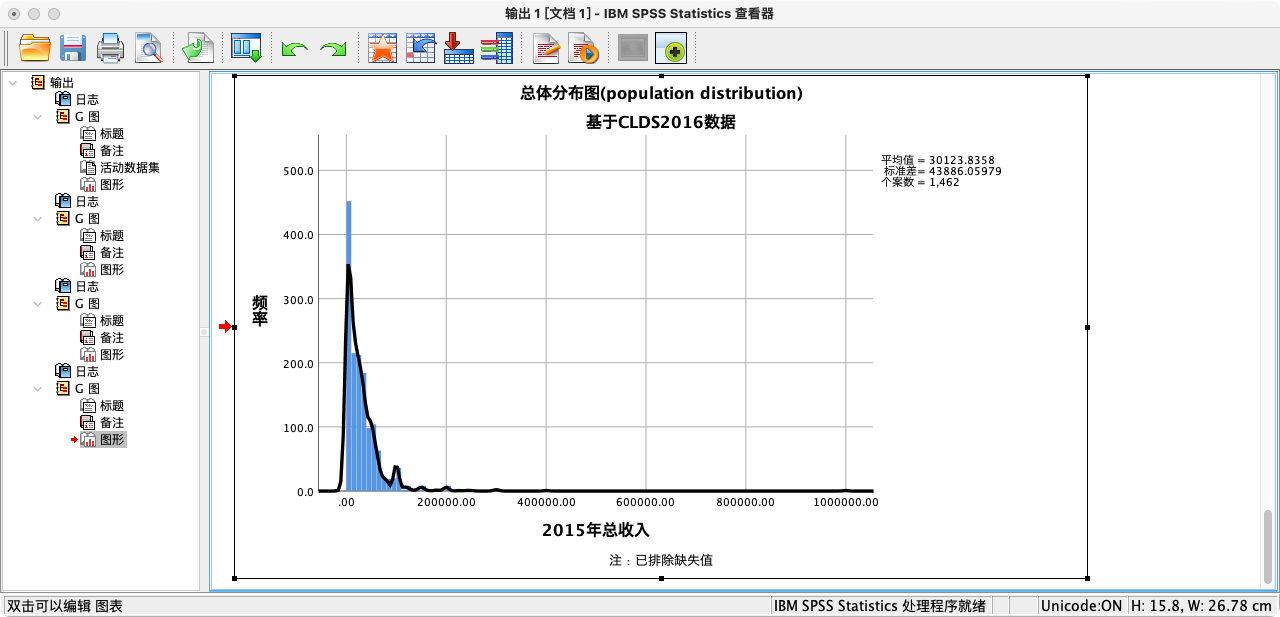
3. 绘制总体分布图 (Population Distribution)
- 在本案例中,我们将清理后的CLDS数据集视为我们的“总体”。我们将绘制这个总体中,收入变量的分布情况。
- 绘图要点
- 坐标轴标签设定横轴为“2015年总收入”,纵轴为“频率”
- 坐标轴取值设定横轴范围为0到100万
- 图表标题为“总体分布图(population distribution)”,副标题为“基于CLDS2016数据”,脚注为“注:已排除缺失值”
- 直方图带宽为1万,图形的形状为方形,概率密度图选择用高斯方法拟合曲线
案例(3-1):绘制总收入的总体分布图
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES=income
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: income=userSource(id("clds"))
DATA: income=col(source(income), name("income"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("总体分布图(population distribution)"))
GUIDE: text.subtitle(label("基于CLDS2016数据"))
GUIDE: text.footnote(label("注:已排除缺失值"))
SCALE: linear(dim(1), min(0), max(1000000))
ELEMENT: interval(position(summary.count(bin.rect(income,binWidth(10000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(income)))
END GPL.
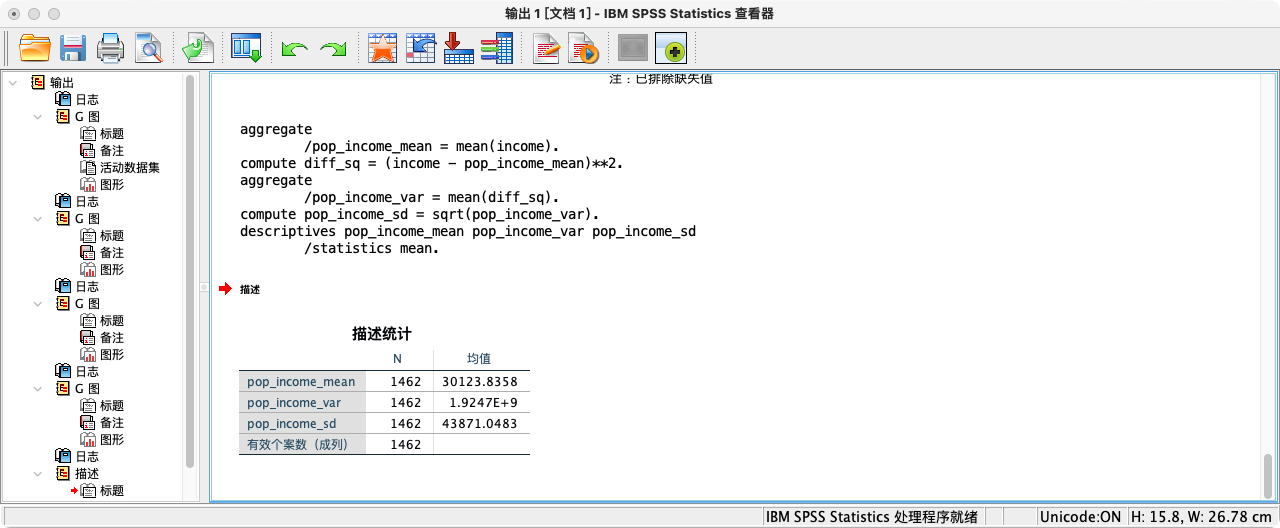
- 计算总体的真实参数
* 使用 AGGREGATE 计算总体均值.
AGGREGATE
/pop_income_mean = MEAN(income).
* 手动计算总体方差 (离差平方的均值).
COMPUTE diff_sq = (income - pop_income_mean)**2.
AGGREGATE
/pop_income_var = MEAN(diff_sq).
* 计算总体标准差.
COMPUTE pop_income_sd = SQRT(pop_income_var).
EXECUTE.
* 查看的总体参数.
FORMATS pop_income_mean pop_income_var pop_income_sd (F20.16).
SUMMARIZE
/TABLES = pop_income_mean pop_income_var pop_income_sd
/FORMAT = VALIDLIST LIMIT=1.
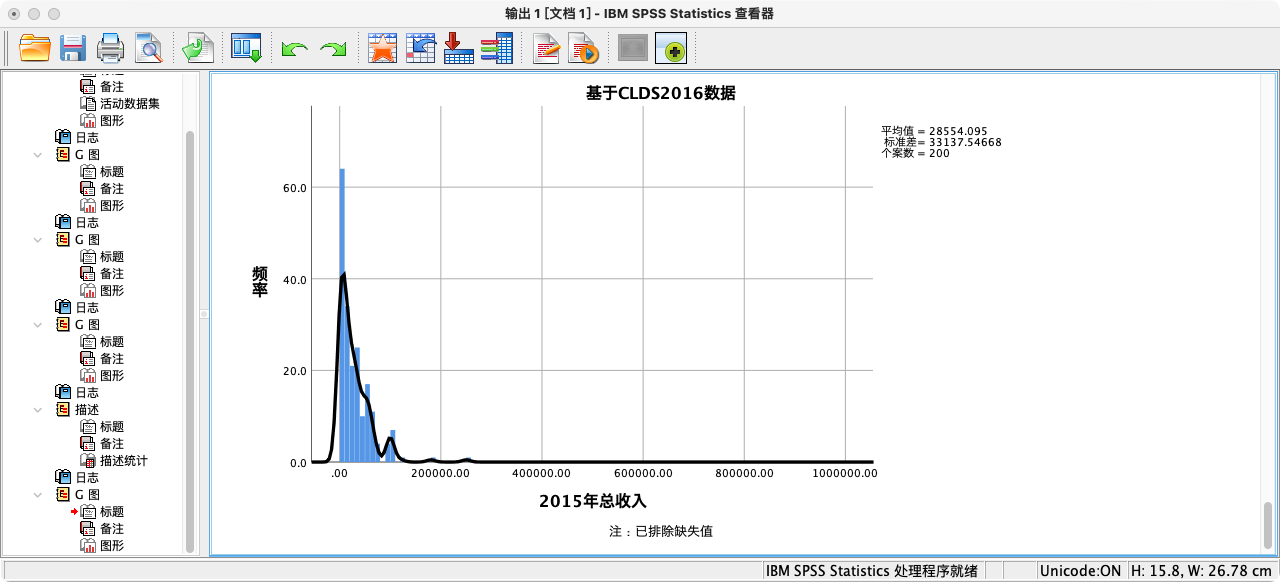
4. 绘制样本分布图 (Sample Distribution)
- 现在,我们从“总体”中抽取一个随机样本,并观察这个样本的分布情况。
- 设定随机种子:为了让抽样结果可以复现,我们在抽样前设定一个种子。
SET SEED = 20220925.
- 执行抽样:从总体中随机抽取200个个案。
- 注意:
SAMPLE命令会永久性地改变当前数据集。在执行前务必保存原始数据。这里我们直接在筛选后的数据上操作。
- 注意:
* 计算总体中的有效个案数N,假设结果为1462.
SAMPLE 200 FROM 1462.
EXECUTE.
- 绘制样本分布图 (GPL语法同上,仅修改标题)
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES=income
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: income=userSource(id("clds"))
DATA: income=col(source(income), name("income"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("样本分布图(sample distribution)"))
GUIDE: text.subtitle(label("基于CLDS2016数据"))
GUIDE: text.footnote(label("注:已排除缺失值"))
SCALE: linear(dim(1), min(0), max(1000000))
ELEMENT: interval(position(summary.count(bin.rect(income,binWidth(10000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(income)))
END GPL.
- 计算总收入的样本统计量
AGGREGATE
/sam_income_mean = MEAN(income).
COMPUTE diff_sam_sq = (income - sam_income_mean)**2.
AGGREGATE
/sam_income_var = MEAN(diff_sam_sq).
COMPUTE sam_income_sd = SQRT(sam_income_var).
FORMATS sam_income_mean sam_income_var sam_income_sd (F20.16).
SUMMARIZE
/TABLES = sam_income_mean sam_income_var sam_income_sd
/FORMAT = VALIDLIST LIMIT=1.
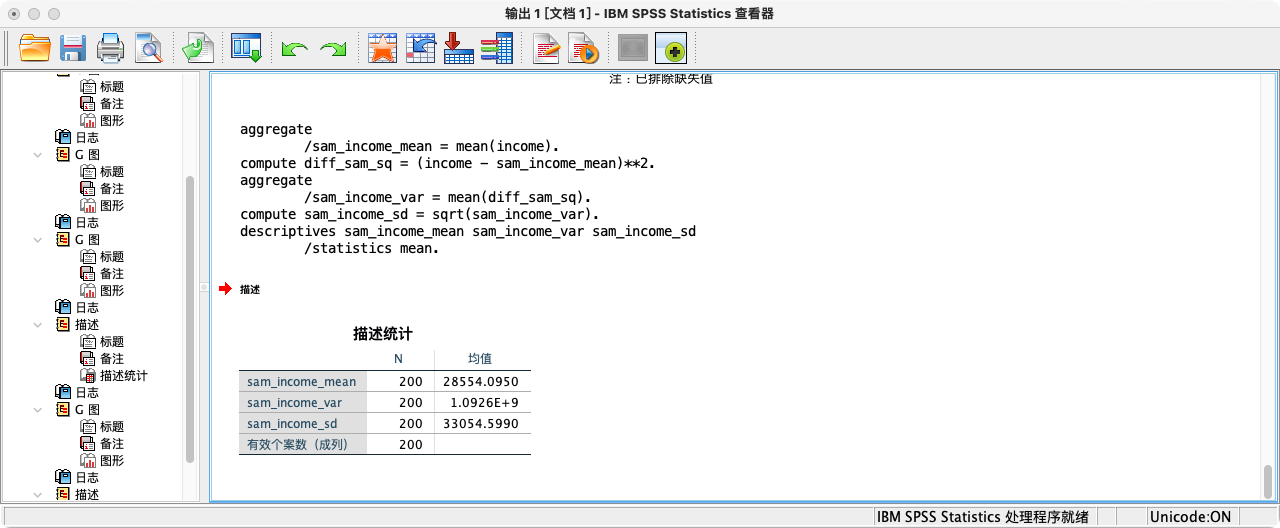
思考:比较样本的均值、标准差和总体参数,它们有多接近?如果重新抽一次样,结果会一样吗?
5. 绘制抽样分布图 (Sampling Distribution)
- 为了“看”到抽样分布,我们需要进行模拟。以下我们加载一个预先模拟好的数据集
income_sample.dta。 - 数据说明:这个文件是通过编程,从我们的“总体”中反复抽样生成的。例如,
sam_income_100这一列,包含了500个数值,每个数值都是一次独立抽样(n=100)所得到的样本均值。
GET STATA FILE "simulation3/income_sample.dta".
DATASET NAME sample.
DATASET ACTIVATE sample.
案例(5-1):比较不同样本量下的抽样分布
- 样本规模 n=100 的抽样分布
GGRAPH
/GRAPHDATASET NAME = "sample" VARIABLES=sam_income_100
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: sam_income_100=userSource(id("sample"))
DATA: sam_income_100=col(source(sam_income_100), name("sam_income_100"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("抽样分布图(sampling distribution)"))
GUIDE: text.subtitle(label("样本规模为100,随机抽取500次"))
SCALE: linear(dim(1), min(10000), max(50000))
ELEMENT: interval(position(summary.count(bin.rect(sam_income_100,binWidth(1000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(sam_income_100)))
END GPL.
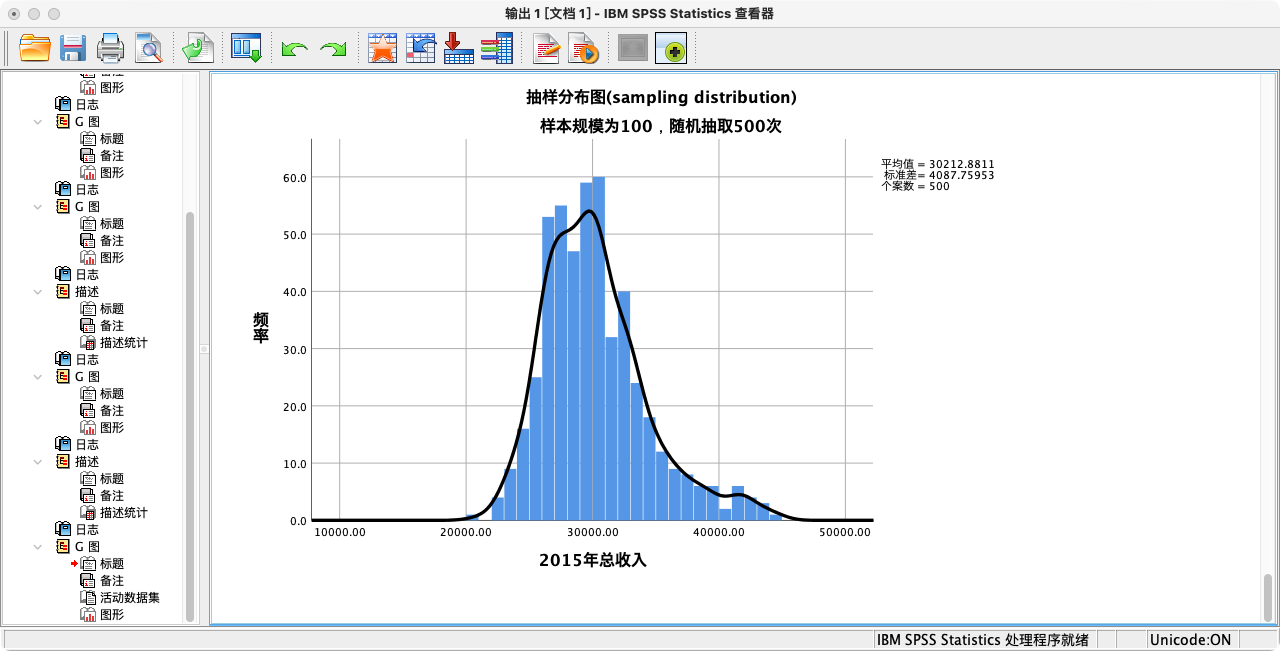
- 计算总收入的样本统计量(n=100)
AGGREGATE
/sam100_income_mean = MEAN(sam_income_100).
COMPUTE diff_sam100_sq = (sam_income_100 - sam100_income_mean)**2.
AGGREGATE
/sam100_income_var = MEAN(diff_sam100_sq).
COMPUTE sam100_income_sd = SQRT(sam100_income_var).
FORMATS sam100_income_mean sam100_income_var sam100_income_sd (F20.16).
SUMMARIZE
/TABLES = sam100_income_mean sam100_income_var sam100_income_sd
/FORMAT = VALIDLIST LIMIT=1.
- 样本规模 n=200 的抽样分布
GGRAPH
/GRAPHDATASET NAME = "sample" VARIABLES=sam_income_200
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: sam_income_200=userSource(id("sample"))
DATA: sam_income_200=col(source(sam_income_200), name("sam_income_200"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("抽样分布图(sampling distribution)"))
GUIDE: text.subtitle(label("样本规模为200,随机抽取500次"))
SCALE: linear(dim(1), min(10000), max(50000))
ELEMENT: interval(position(summary.count(bin.rect(sam_income_200,binWidth(1000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(sam_income_200)))
END GPL.
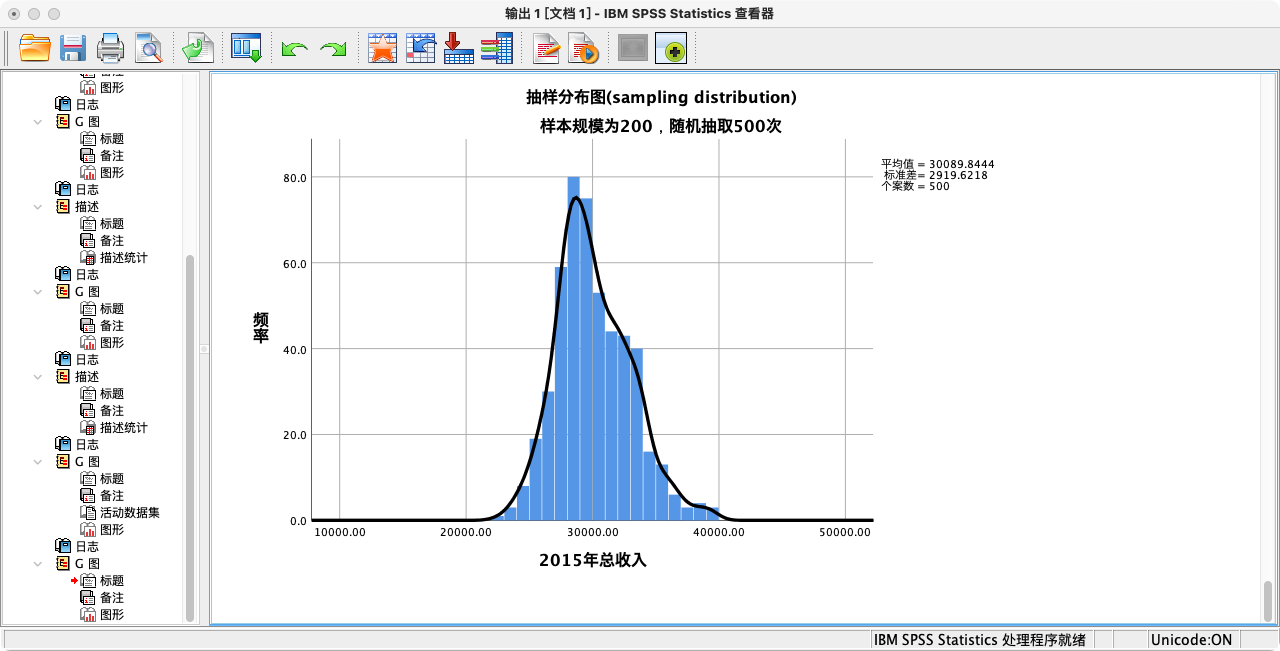
- 计算总收入的样本统计量(n=200)
AGGREGATE
/sam200_income_mean = MEAN(sam_income_200).
COMPUTE diff_sam200_sq = (sam_income_200 - sam200_income_mean)**2.
AGGREGATE
/sam200_income_var = MEAN(diff_sam200_sq).
COMPUTE sam200_income_sd = SQRT(sam200_income_var).
FORMATS sam200_income_mean sam200_income_var sam200_income_sd (F20.16).
SUMMARIZE
/TABLES = sam200_income_mean sam200_income_var sam200_income_sd
/FORMAT = VALIDLIST LIMIT=1.
- 样本规模 n=500 的抽样分布
GGRAPH
/GRAPHDATASET NAME = "sample" VARIABLES=sam_income_500
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: sam_income_500=userSource(id("sample"))
DATA: sam_income_500=col(source(sam_income_500), name("sam_income_500"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("抽样分布图(sampling distribution)"))
GUIDE: text.subtitle(label("样本规模为500,随机抽取500次"))
SCALE: linear(dim(1), min(10000), max(50000))
ELEMENT: interval(position(summary.count(bin.rect(sam_income_500,binWidth(1000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(sam_income_500)))
END GPL.
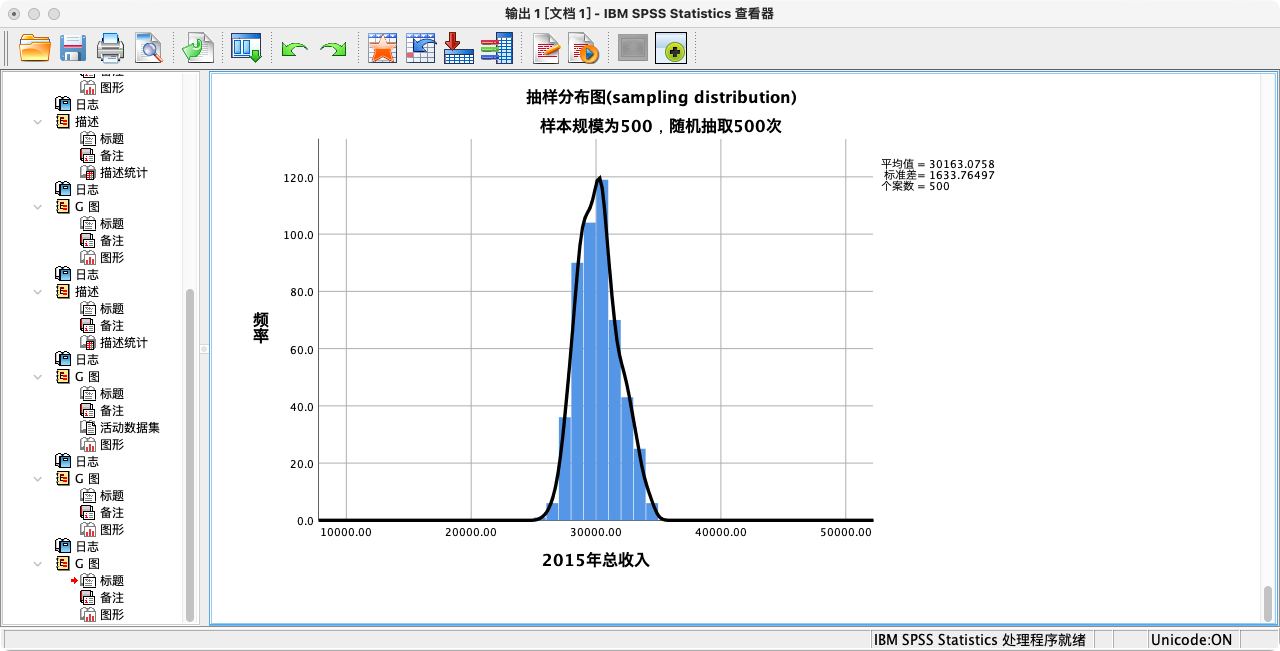
- 计算总收入的样本统计量(n=500)
AGGREGATE
/sam500_income_mean = MEAN(sam_income_500).
COMPUTE diff_sam500_sq = (sam_income_500 - sam500_income_mean)**2.
AGGREGATE
/sam500_income_var = MEAN(diff_sam500_sq).
COMPUTE sam500_income_sd = SQRT(sam500_income_var).
FORMATS sam500_income_mean sam500_income_var sam500_income_sd (F20.16).
SUMMARIZE
/TABLES = sam500_income_mean sam500_income_var sam500_income_sd
/FORMAT = VALIDLIST LIMIT=1.
- 样本规模 n=1000 的抽样分布
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES=sam_income_1000
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: sam_income_1000=userSource(id("clds"))
DATA: sam_income_1000=col(source(sam_income_1000), name("sam_income_1000"))
GUIDE: axis(dim(1), label("2015年总收入"))
GUIDE: axis(dim(2), label("频率"))
GUIDE: text.title(label("抽样分布图(sampling distribution)"))
GUIDE: text.subtitle(label("样本规模为1000,随机抽取500次"))
SCALE: linear(dim(1), min(10000), max(50000))
ELEMENT: interval(position(summary.count(bin.rect(sam_income_1000,binWidth(1000)))),shape.interior(shape.square))
ELEMENT: line(position(density.kernel.gaussian(sam_income_1000)))
END GPL.
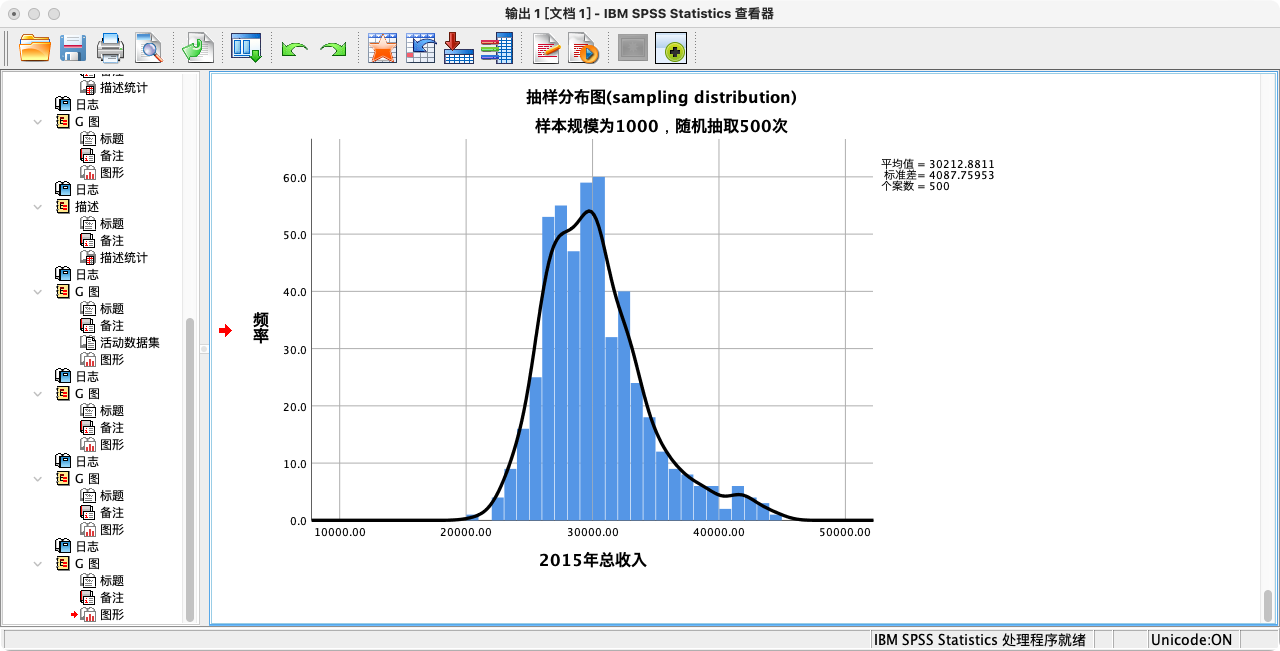
- 计算总收入的样本统计量(n=1000)
AGGREGATE
/sam1000_income_mean = MEAN(sam_income_1000).
COMPUTE diff_sam1000_sq = (sam_income_1000 - sam1000_income_mean)**2.
AGGREGATE
/sam1000_income_var = MEAN(diff_sam1000_sq).
COMPUTE sam1000_income_sd = SQRT(sam1000_income_var).
FORMATS sam1000_income_mean sam1000_income_var sam1000_income_sd (F20.16).
SUMMARIZE
/TABLES = sam1000_income_mean sam1000_income_var sam1000_income_sd
/FORMAT = VALIDLIST LIMIT=1.
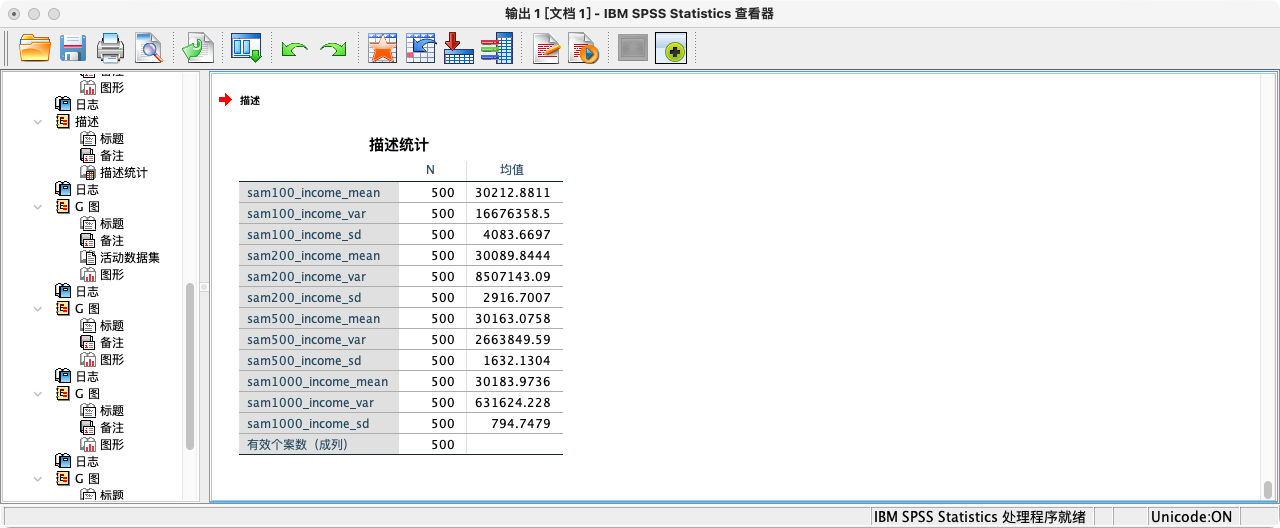
- 同时报告不同样本规模抽样分布的均值、方差和标准差.
DESCRIPTIVES sam100_income_mean sam100_income_var sam100_income_sd
sam200_income_mean sam200_income_var sam200_income_sd
sam500_income_mean sam500_income_var sam500_income_sd
sam1000_income_mean sam1000_income_var sam1000_income_sd
/STATISTICS MEAN.
观察与结论
比较不同样本规模下的抽样分布图,可以清晰地看到中央极限定理的效果:
- 两个分布的中心都围绕在总体均值附近。
- 当样本规模从100增大到500时,抽样分布明显变得更高、更瘦。这说明样本均值的波动范围变小了,即我们的估计变得更精确了。这个分布的标准差,就是标准误。
6. 理解标准误 (Standard Error)
-
标准误是衡量抽样不确定性的核心指标。它告诉我们,样本统计量(如样本均值)在多次抽样中,平均会偏离总体参数(总体均值)多远。
-
场景一:总体参数已知 (理论情况)
- 标准误的计算公式为:$$ SE_{\bar{x}} = \frac{\sigma}{\sqrt{n}} $$ 其中, σ 是总体标准差, n 是样本大小。
-
场景二:总体参数未知 (现实情况)
- 我们用样本标准差
s来估计总体标准差σ。 - 标准误的估计公式为:$$ \hat{SE}_{\bar{x}} = \frac{s}{\sqrt{n-1}} $$
- 这个值,SPSS可以直接通过
DESCRIPTIVES命令中的SEMEAN选项计算出来。
- 我们用样本标准差
-
注意:样本方差的贝塞尔校正 (Bessel’s Correction)
- 当我们用样本来估计总体方差时,如果直接用样本的方差公式,会倾向于低估总体的真实方差。
- 为了得到一个无偏估计,我们在计算样本方差时,分母使用
n-1而不是n。 - SPSS的所有标准统计程序(如
DESCRIPTIVES,T-TEST等)在计算方差和标准差时,默认都使用了 n-1 的校正。
-
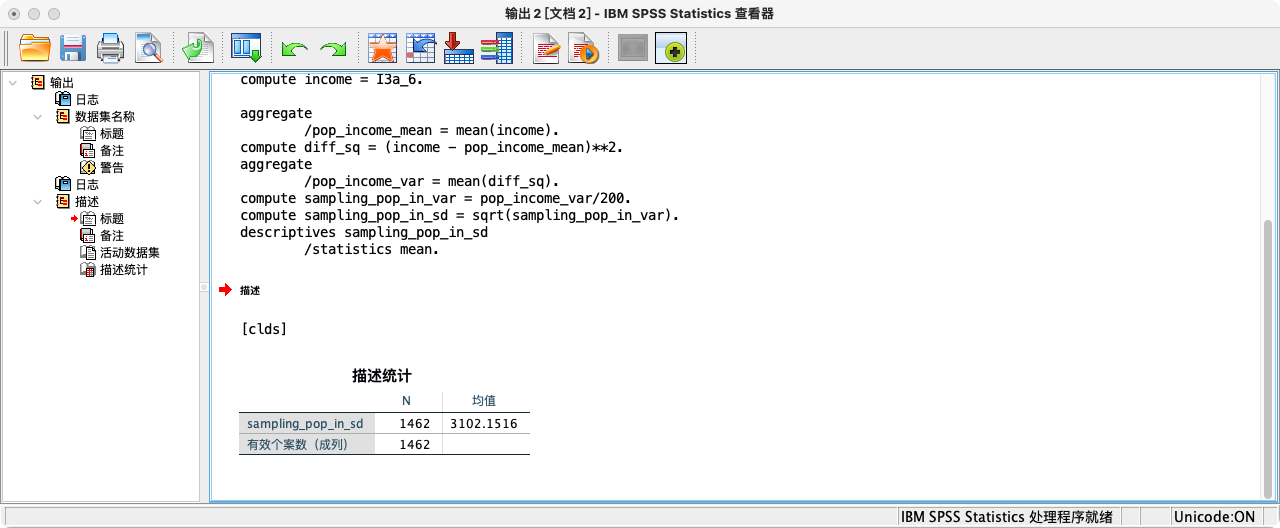
总体已知,利用总体信息
AGGREGATE
/pop_income_mean = MEAN(income).
COMPUTE diff_sq = (income - pop_income_mean)**2.
AGGREGATE
/pop_income_var = MEAN(diff_sq).
COMPUTE sampling_pop_in_var = pop_income_var/200.
COMPUTE sampling_pop_in_sd = SQRT(sampling_pop_in_var).
FORMATS sampling_pop_in_sd (F20.16).
SUMMARIZE
/TABLES = sampling_pop_in_sd
/FORMAT = VALIDLIST LIMIT=1.
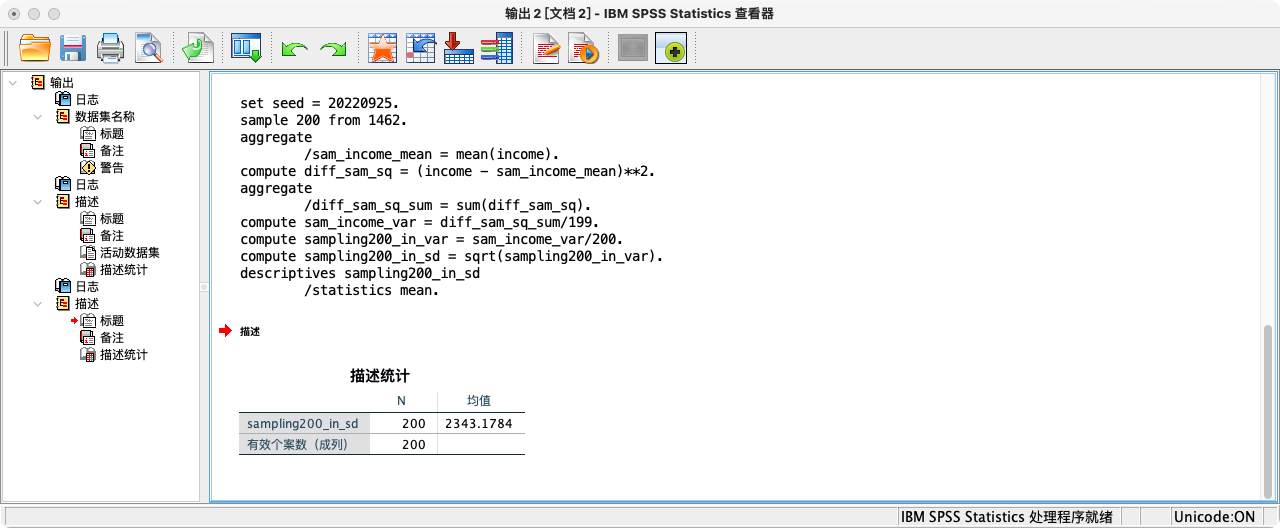
- 总体未知,利用样本信息
SET SEED = 20220925.
SAMPLE 200 FROM 1462.
AGGREGATE
/sam_income_mean = MEAN(income).
COMPUTE diff_sam_sq = (income - sam_income_mean)**2.
AGGREGATE
/diff_sam_sq_sum = SUM(diff_sam_sq).
COMPUTE sam_income_var = diff_sam_sq_sum/199.
COMPUTE sampling200_in_var = sam_income_var/200.
COMPUTE sampling200_in_sd = SQRT(sampling200_in_var).
FORMATS sampling200_in_sd (F20.16).
SUMMARIZE
/TABLES = sampling200_in_sd
/FORMAT = VALIDLIST LIMIT=1.
- 可以使用descriptives语法直接报告结果
- 注意:descriptives语法报告的结果,均把当前数据集视为样本而非总体,其结果已进行贝塞尔校正
DESCRIPTIVES income
/STATISTICS = MEAN STDDEV VARIANCE MIN MAX SEMEAN.
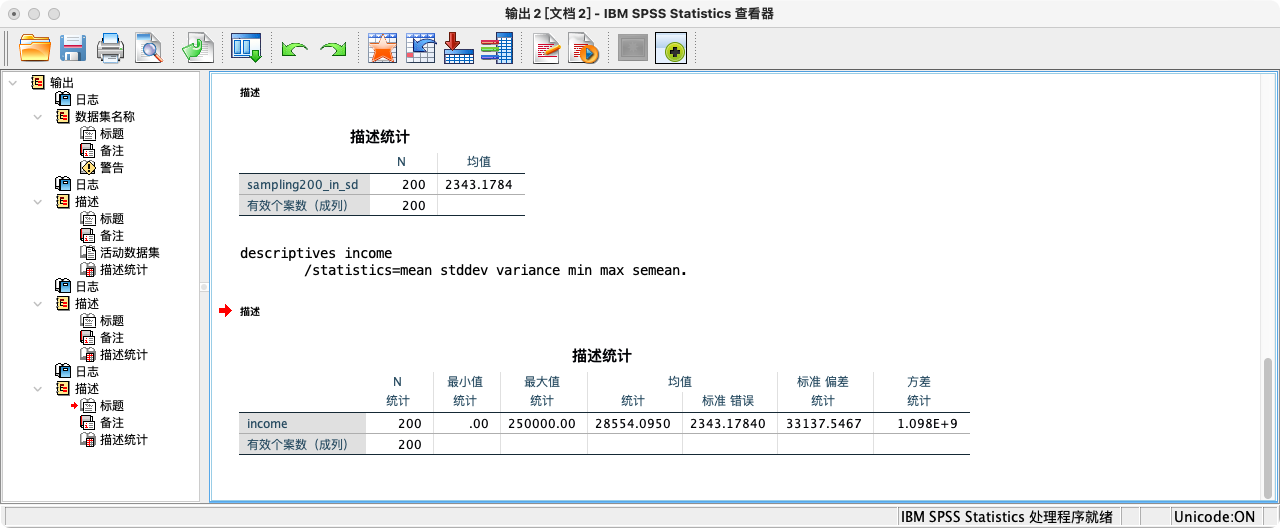
- 解读:输出结果中的
SEMEAN(均值标准误),就是 SPSS 帮你计算好的s / sqrt(n)的值。
7. 根据样本信息估计总体的置信区间
- 置信区间 (Confidence Interval) 是我们利用样本信息,对未知的总体参数给出的一个“区间估计”。
- 例如,一个“95%置信区间”意味着,如果我们反复用同样的方法进行抽样和计算,有95%的几率,我们构建出的这些区间会包含真实的总体参数。
- 点选操作:分析 → 描述统计 → 探索 → 在左侧变量列表中选择变量 → 选择统计 → 勾选描述并输入置信区间 → 确定
- 语法操作:使用
EXAMINE命令(参考第五讲)。
案例(7-1):利用一个样本(n=200)估计总收入的95%置信区间
EXAMINE VARIABLES=income
/PLOT NONE
/STATISTICS DESCRIPTIVES
/CINTERVAL 95.
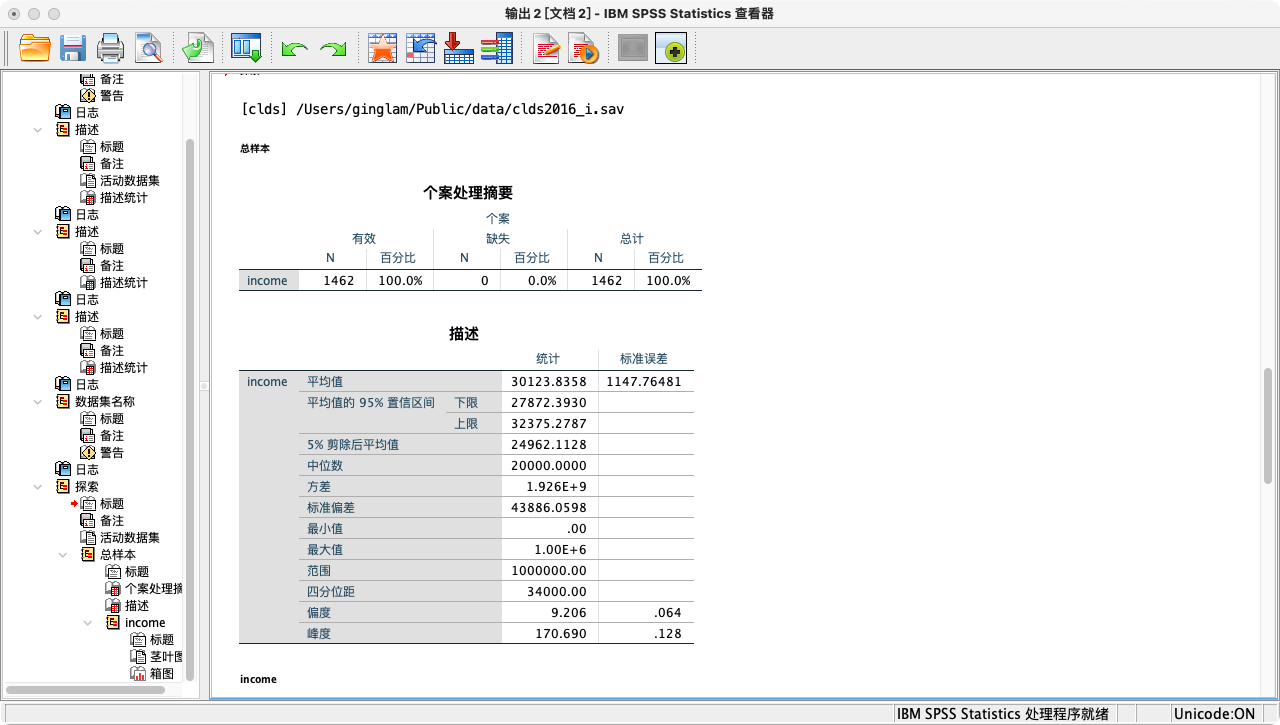
- 解读:在输出的“描述”表格中,找到“均值的95%置信区间”的“下限”和“上限”。这就是我们根据这200个样本数据,对总体平均收入给出的一个估计范围。
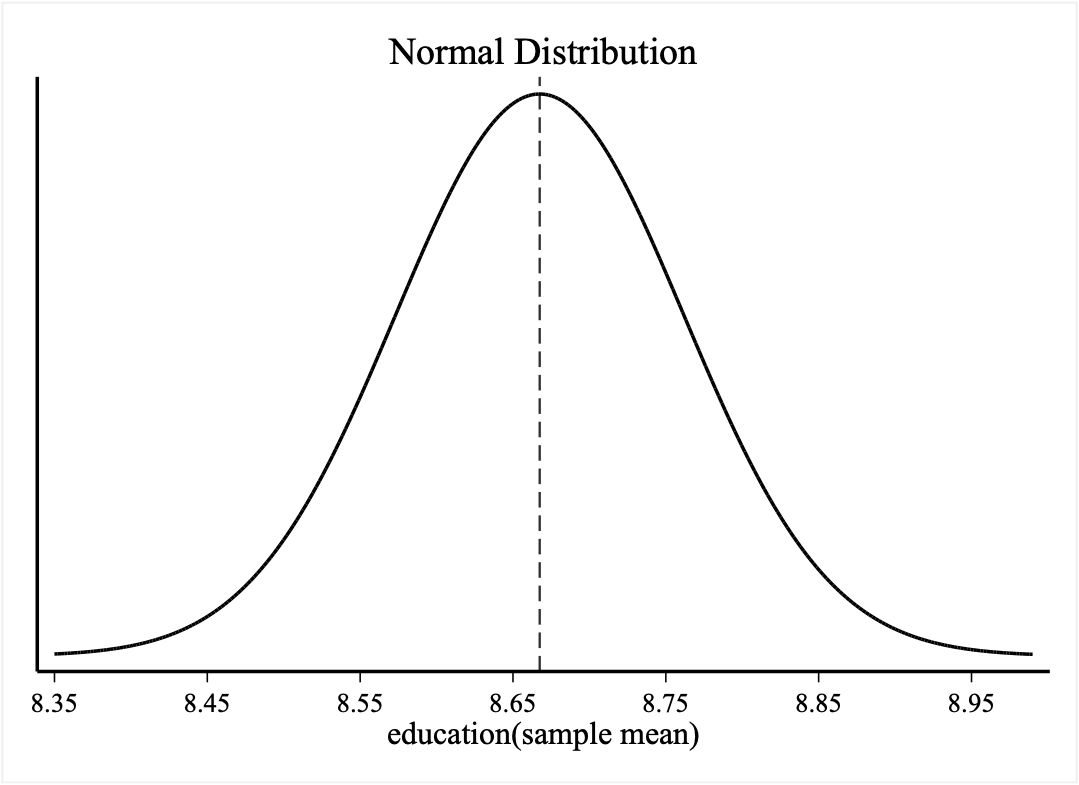
8.绘制教育年限的抽样分布.
- 预设知道总体信息
- 教育年限总体均值=8.667468,总体标准差=4.223336,总体个数=2081
- 若教育年限的样本个数为2005,其理想抽样分布为正态分布N(8.667468,0.00889604)
- 以下为Stata命令
#delimit;
graph twoway
(function y=normalden(x,8.667468,0.09431883), range(8.35 8.99) lw(medthick)),
xline(8.667468, lpattern(dash))
title("Normal Distribution")
xtitle("education(sample mean)", size(medlarge)) ytitle("")
ylabel("",nogrid)
xlabel(8.35(0.1)8.99)
xscale(lw(medthick)) yscale(lw(medthick))
graphregion(fcolor(white));
#delimit cr
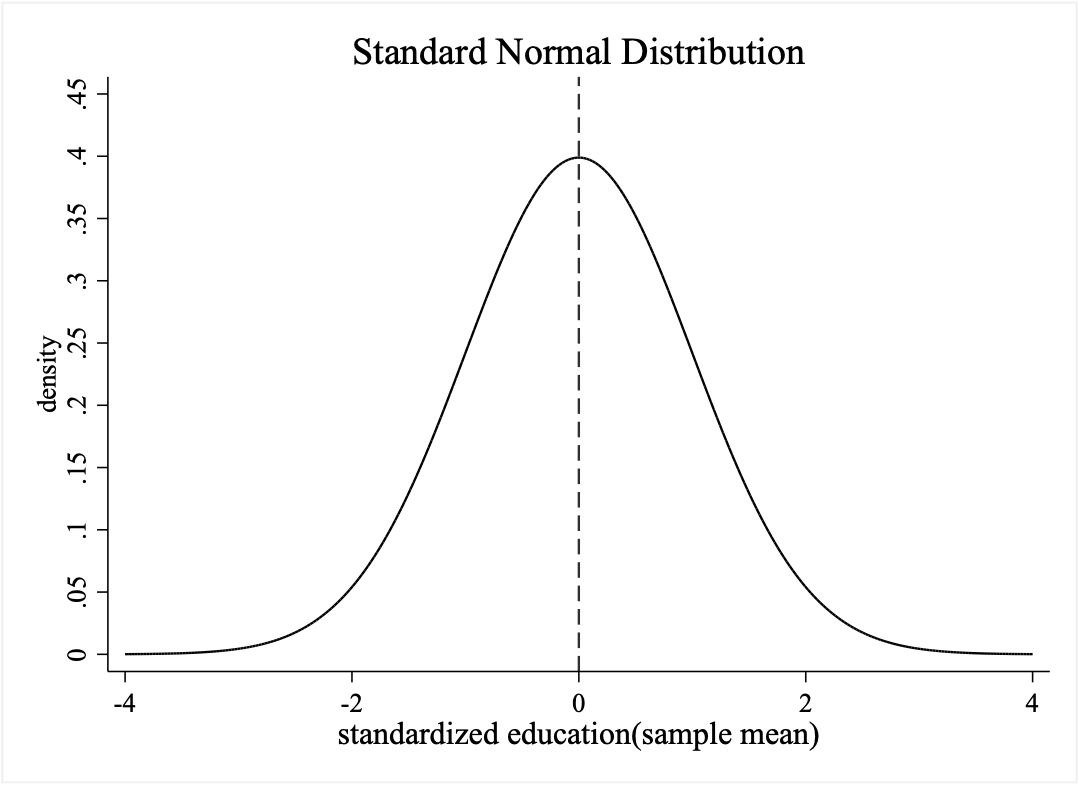
9.将教育年限的抽样分布标准化,绘制标准正态分布
- 以下为Stata命令
#delimit;
graph twoway
(function y=normalden(x),range(-4 4)),
xline(0,lpattern(dash))
title("Standard Normal Distribution")
ylabel(0(0.05)0.45,nogrid)
xtitle("standardized education(sample mean)", size(medlarge)) ytitle("density")
graphregion(fcolor(white));
#delimit cr
随堂练习:根据2015年平均每周工作时间(I3a_1)计算其总体均值的95%置信区间。
练习参考答案
* 步骤一:准备数据. GET FILE "clds2016_i.sav". SELECT IF (I3a_1 > 0). /* 假设工作时间大于0为有效值 */ * 步骤二:使用EXAMINE命令计算. EXAMINE VARIABLES=I3a_1 /PLOT NONE /STATISTICS DESCRIPTIVES /CINTERVAL 95. EXECUTE.
附:抽样分布的理论形态(Stata绘图补充)
辅助知识点: 中央极限定理告诉我们抽样分布趋向于正态分布。如果我们知道了总体的均值和标准差,我们就能精确地画出这个理论上的正态分布曲线。
标准化与标准正态分布 任何一个正态分布,都可以通过
(X - μ) / σ的公式转换为一个均值为0,标准差为1的标准正态分布。这是进行假设检验(如t检验、Z检验)的理论基础。
Disqus comments are disabled.