第九讲 抽样分布、区间估计与均值检验
Last updated: Sep 18, 2025
从理论到实践
辅助知识点: 在上一讲中,我们通过模拟,直观地理解了总体、样本和抽样分布这三大核心概念。
本讲我们将学习
- 精确计算这三个分布的关键参数(均值、方差、标准差/标准误)。
- 利用我们手中的一个样本,对未知的总体参数进行区间估计(Confidence Interval)。
- 基于样本证据,对关于总体均值的某个断言进行科学的假设检验 (Hypothesis Testing)。
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 计算总体分布、样本分布及抽样分布
我们将以2015年总收入 (I3a_6) 为例,通过一个清晰的流程,来计算总体、样本及抽样分布的参数。
-
场景设定
- 首先将完整的CLDS数据集视为“总体”。
- 然后从中随机抽取一个样本 (n=500)。
- 最后计算理论上的抽样分布参数。
-
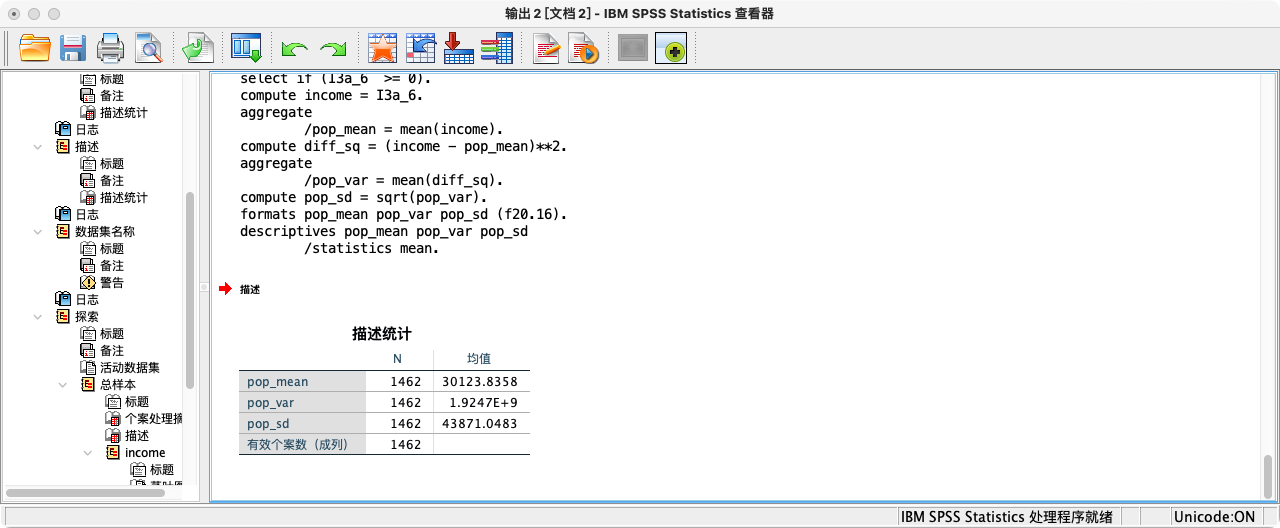
第一步:计算总体参数 (Population Parameters)
- 我们先筛选出有效数据,并计算其真实的均值(μ)、方差(σ²)和标准差(σ)。
- 注意:此时CLDS数据集相当于总体数据集。
* 准备数据,筛选有效值.
SELECT IF (I3a_6 >= 0).
COMPUTE income = I3a_6.
EXECUTE.
* 计算总体均值(μ).
AGGREGATE
/pop_mean = MEAN(income).
* 计算总体方差(σ²),其定义是离差平方和的加权均值.
COMPUTE diff_sq = (income - pop_mean)**2.
AGGREGATE
/pop_var = MEAN(diff_sq).
* 计算总体标准差(σ),即方差的正平方根.
COMPUTE pop_sd = SQRT(pop_var).
EXECUTE.
* 显示结果.
FORMATS pop_mean pop_var pop_sd (F20.16).
SUMMARIZE
/TABLES = pop_mean pop_var pop_sd
/FORMAT = VALIDLIST LIMIT=1.
-
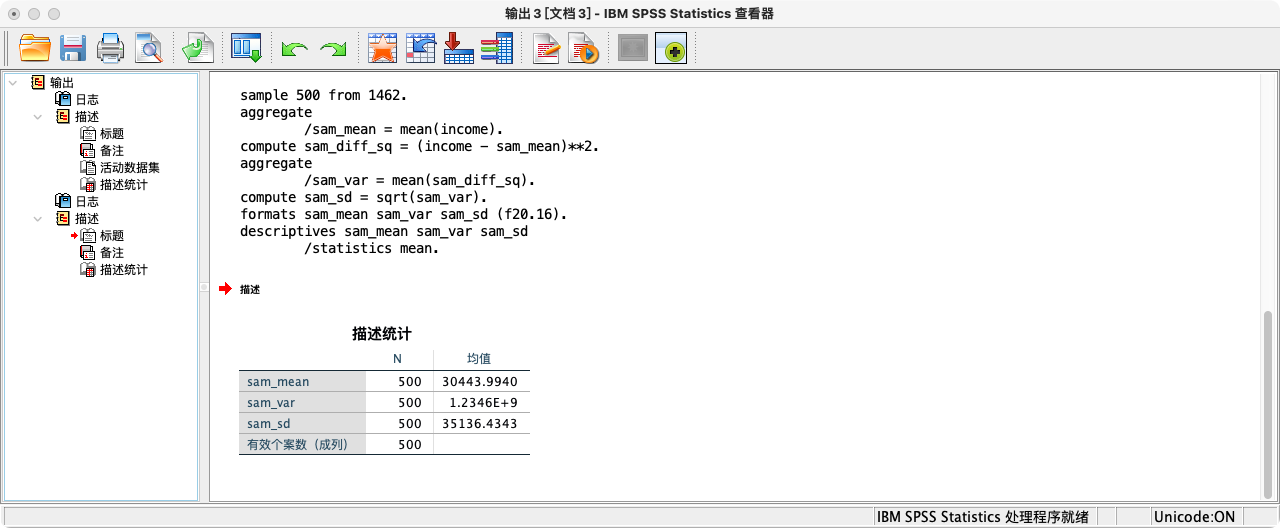
第二步:抽取样本,并计算样本统计量 (Sample Statistics)
- 现在我们从“总体”的1462个对象中,抽取一个n=500的样本。
* 重新加载完整数据以进行抽样.
GET FILE "clds2016_i.sav".
SELECT IF (I3a_6 >= 0).
COMPUTE income = I3a_6.
SET SEED=2024. /* 设定随机种子以保证结果可复现 */
SAMPLE 500 FROM 1462.
EXECUTE.
* 计算样本均值(X̄)、样本方差(s²_n)和样本标准差(s_n).
* 注意:这里我们先手动计算分母为n的“有偏”方差. 当我们不关注总体,只关注样本本身,计算方差的分母为n.
AGGREGATE
/sam_mean = MEAN(income).
COMPUTE sam_diff_sq = (income - sam_mean)**2.
AGGREGATE
/sam_var_n = MEAN(sam_diff_sq).
COMPUTE sam_sd_n = SQRT(sam_var_n).
EXECUTE.
FORMATS sam_mean sam_var_n sam_sd_n (F20.16).
SUMMARIZE
/TABLES = sam_mean sam_var_n sam_sd_n
/FORMAT = VALIDLIST LIMIT=1.
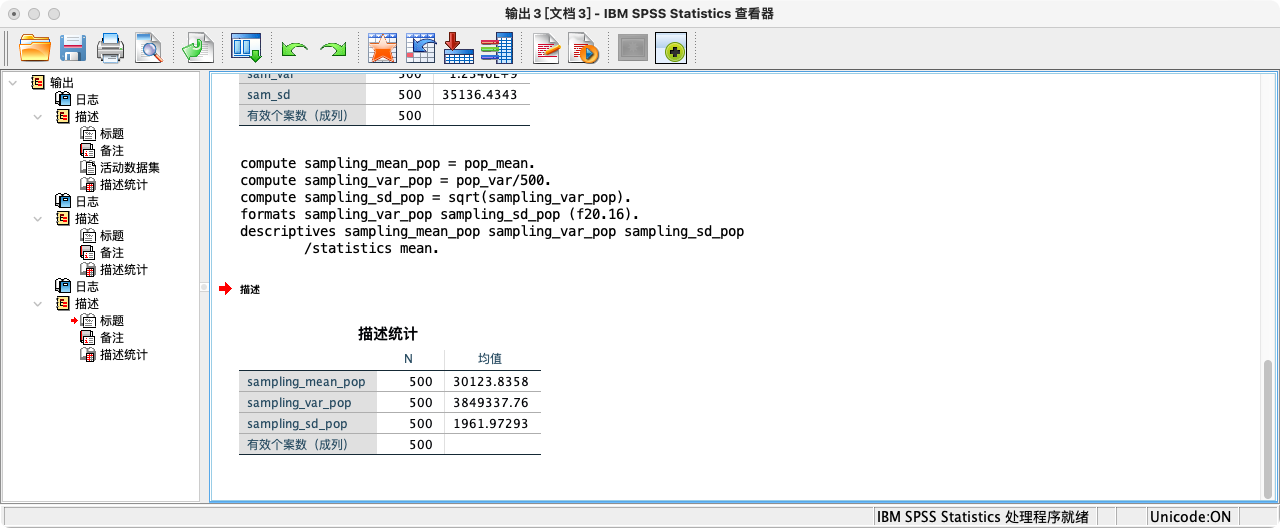
- 第三步:计算抽样分布的参数 (Sampling Distribution Parameters)
- 情况一:当总体已知时 (理论情况)
- 抽样分布的均值(μ_x̄)等于总体均值(μ)。
- 抽样分布的方差(σ²_x̄)等于总体方差(σ²)除以样本量n。
- 抽样分布的标准差,即标准误 (Standard Error, SE),等于总体标准差(σ)除以√n。
COMPUTE sampling_mean_pop = pop_mean.
COMPUTE sampling_var_pop = pop_var/500.
COMPUTE sampling_sd_pop = SQRT(sampling_var_pop). /* 这就是标准误 SE */
EXECUTE.
FORMATS sampling_mean_pop sampling_var_pop sampling_sd_pop (F20.16).
SUMMARIZE
/TABLES = sampling_mean_pop sampling_var_pop sampling_sd_pop
/FORMAT = VALIDLIST LIMIT=1.
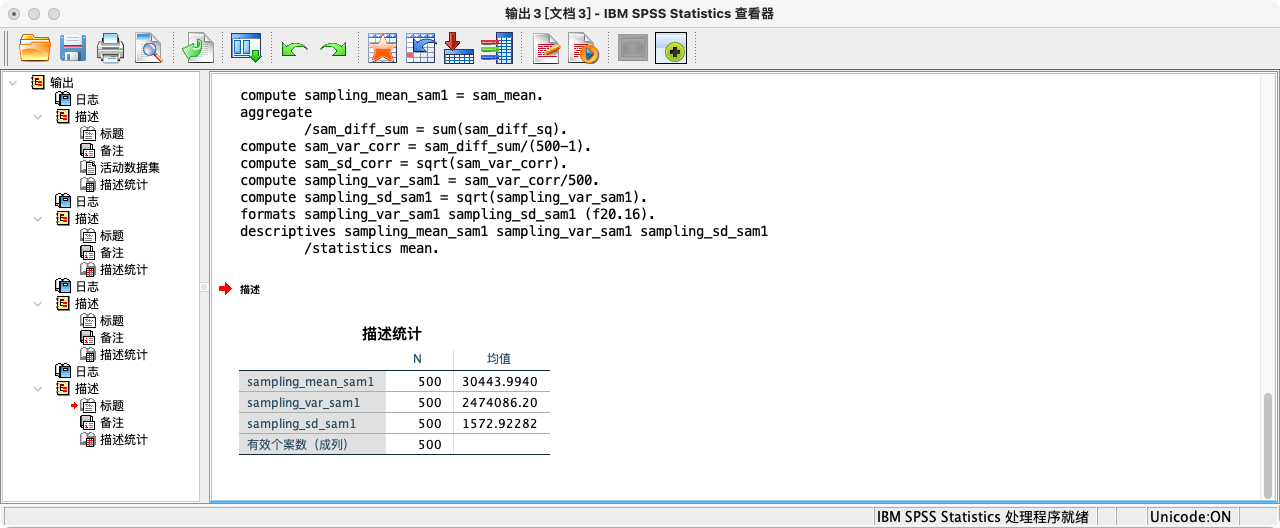
- 情况二:当总体未知时 (现实情况)
- 在现实中,我们没有总体参数,只能用样本统计量来估计抽样分布的参数。
- 方法A:手动计算 (应用贝塞尔校正)
辅助知识点:贝塞尔校正 (Bessel’s Correction) 当我们使用样本方差来估计总体方差时,直接计算的样本方差(分母为n)会倾向于低估真实的总体方差。为了得到一个更准确的无偏估计,我们需要将分母从
n调整为n-1。这就是贝塞尔校正。
/* 假设我们只有那个n=500的样本... */
COMPUTE sampling_mean_sam1 = sam_mean.
* 计算离差平方和.
AGGREGATE
/sam_diff_sum = SUM(sam_diff_sq).
* 计算经过校正的样本方差 s² (分母为n-1).
COMPUTE s_squared = sam_diff_sum/(500 - 1).
* 估计抽样分布的方差.
COMPUTE sampling_var_sam1 = s_squared/500.
* 估计标准误.
COMPUTE sampling_sd_sam1 = SQRT(sampling_var_sam1).
EXECUTE.
FORMATS sampling_mean_sam1 sampling_var_sam1 sampling_sd_sam1 (F20.16).
SUMMARIZE
/TABLES = sampling_mean_sam1 sampling_var_sam1 sampling_sd_sam1
/FORMAT = VALIDLIST LIMIT=1.
- 方法B:利用SPSS内置命令与输出管理系统(Output Management System,OMS)
- SPSS的
DESCRIPTIVES等标准命令在计算标准差和方差时,默认已经进行了贝塞尔校正(即分母为n-1)。它计算出的“均值标准误(SEMEAN)”就是我们需要的s / sqrt(n)。我们可以用输出管理系统(OMS)将这个结果直接捕获为一个新数据集。
- SPSS的
辅助知识点:输出管理系统 (Output Management System, OMS)
什么是OMS?
输出管理系统 (OMS) 是SPSS中一个非常强大的高级功能。通常情况下,我们运行一个分析命令(如
FREQUENCIES),它的结果会以表格和图形的形式显示在“输出查看器”窗口中。这些结果是“死的”,我们只能看,不能直接用于再分析。OMS 的作用就是充当一个“捕获器”或“拦截器”。它可以在结果被发送到输出查看器之前,将其拦截下来,并按照我们的指令,将这些表格转换成一个SPSS数据文件 (.sav)。
为什么要用OMS?
想象一下,你想比较100个不同变量的均值。如果用常规方法,你需要运行100次
DESCRIPTIVES,然后手动将100个均值从输出窗口抄写或复制到一个新的数据文件中。这个过程不仅繁琐,而且极易出错。使用OMS,你只需要编写一个简单的语法块,运行这100次
DESCRIPTIVES,OMS就会自动为你创建一个包含这100个均值的新数据集。这在进行元分析、模拟研究或需要对分析结果进行二次处理时,是不可或缺的利器。关键使用技巧:切换输出语言
在使用OMS将结果保存为数据文件之前,强烈建议将SPSS的输出语言临时切换为英语。
- 点选操作:编辑 → 选项 → 语言 → 在“输出”下拉菜单中选择“English”。
- 原因:如果使用中文输出,OMS生成的数据集中的变量名可能会是中文(例如“均值”、“标准差”)。虽然这在SPSS中可行,但在后续的语法编写或与其他软件交互时,使用英文变量名(如
Mean,StdDeviation)会更加标准和方便,避免潜在的编码问题。
语法操作:OMS 的工作模式就像一个三明治:OMS命令是顶部的面包片,OMSEND是底部的面包片,中间夹着的是你想要捕获其结果的常规分析命令。
OMS
/SELECT [内容类型]
/IF COMMANDS=["命令1" "命令2"...] SUBTYPES=["子类型1" "子类型2"...]
/DESTINATION FORMAT=SAV OUTFILE="<文件名.sav>".
[这里是你的常规分析命令,例如 DESCRIPTIVES, FREQUENCIES 等]
OMSEND.
语法说明
-
OMS ... OMSEND.这是一个成对出现的命令块。OMS标志着捕获开始,OMSEND标志着捕获结束。所有在这两者之间的命令的输出,都会被OMS系统进行处理。 -
/SELECT [内容类型]指定你想要捕获的输出内容的主要类型。TABLES: 表格 (这是最常用的选项)。HEADINGS: 标题文本。CHARTS: 图形。MODELS: 模型(如回归模型的摘要)。WARNINGS: 警告信息。
-
/IF COMMANDS=["命令列表"] SUBTYPES=["子类型列表"]这是一个过滤器,用于精确指定你只想捕获哪些命令的哪些特定表格。COMMANDS: 指定你感兴趣的命令名称,例如["Descriptives"],["Frequencies"],["T-Test"]。SUBTYPES: 指定该命令输出的众多表格中,你具体想要哪一个。- 如何找到正确的
SUBTYPES名称? 这是使用OMS最关键的一步。- 先正常运行一次你想捕获的命令(例如
DESCRIPTIVES income.)。 - 在输出查看器中,找到你想要捕获的那个表格。
- 右键点击该表格的标题(在左侧大纲视图中),选择**“复制OMS命令标识符”**和**“复制OMS表格子类型”**,然后粘贴到你的语法中。
- 先正常运行一次你想捕获的命令(例如
-
/DESTINATION FORMAT=<格式OUTFILE="<文件名>"指定捕获到的内容要以何种格式保存到哪个文件中。FORMAT:SAV: SPSS数据文件 (最常用)。XLSX: Excel文件。PDF: PDF文档。HTML,TEXT等。
OUTFILE: 指定保存的路径和文件名。
综合示例:捕获DESCRIPTIVES命令的描述统计表
-
目标:我们想运行
DESCRIPTIVES命令来计算变量income的均值、标准差等,并希望将输出的“描述统计”表格直接保存为一个名为my_descriptives.sav的新数据集。 -
语法实现
* 步骤一:开始OMS捕获会话.
OMS
/SELECT TABLES /* 我们想要捕获的是表格 */
/IF COMMANDS=["Descriptives"] SUBTYPES=["Descriptive Statistics"] /* 精确指定:只捕获DESCRIPTIVES命令的'Descriptive Statistics'子类型表格 */
/DESTINATION FORMAT=SAV OUTFILE= "sample_descriptives.sav" /* 将其保存为SAV文件 */.
* 步骤二:运行我们常规的分析命令.
* 这个命令的输出结果不会显示在查看器中,而是会被OMS拦截.
DESCRIPTIVES income
/STATISTICS = MEAN STDDEV VARIANCE SEMEAN.
* 步骤三:结束OMS捕获会话,此时文件将被写入磁盘.
OMSEND.
* 步骤四 (可选):打开新生成的数据集查看结果.
GET FILE "sample_descriptives.sav".
display dictionary.
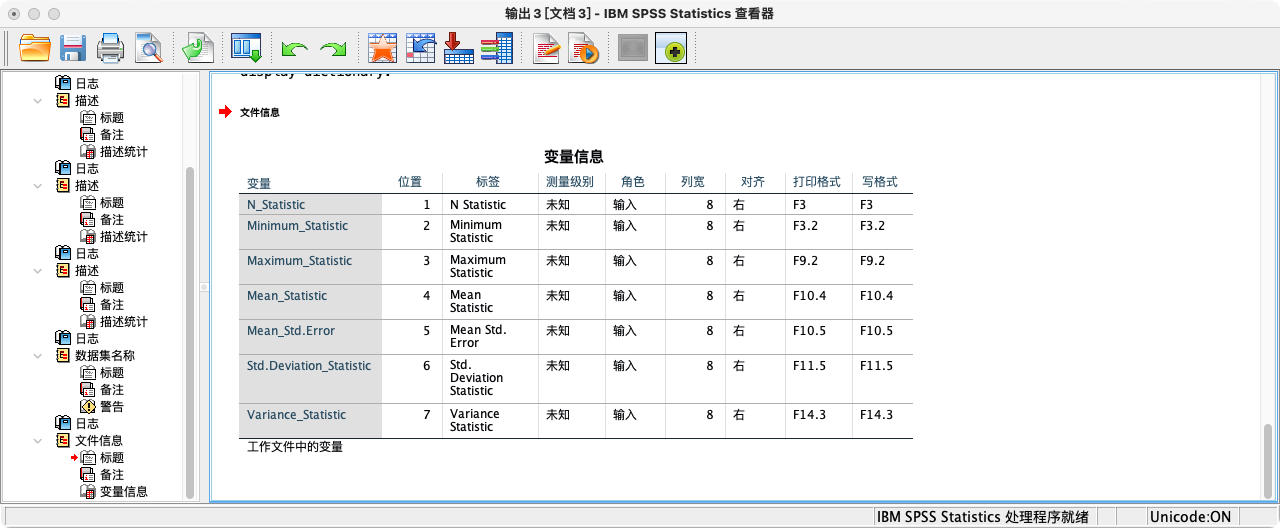
- 接下来我们将语法DESCRIPTIVES计算income的结果存储为数据。
* 假设我们仍在n=500的样本数据集中.
OMS
/SELECT TABLES
/IF COMMANDS=['Descriptives'] SUBTYPES=['Descriptive Statistics']
/DESTINATION FORMAT=SAV OUTFILE='sample_descriptives.sav'.
DESCRIPTIVES income
/STATISTICS=MEAN STDDEV VARIANCE SEMEAN.
OMSEND.
* 读取捕获的结果.
GET FILE "sample_descriptives.sav".
RENAME VARIABLES
(Mean_Statistic=sam_mean)
(Std. Deviation_Statistic=s)
(Variance_Statistic=s_squared)
(Std. Error of Mean_Statistic=SE_mean).
* 整理并计算.
COMPUTE sampling_mean_sam2 = sam_mean.
COMPUTE sampling_sd_sam2 = SE_mean.
COMPUTE sampling_var_sam2 = SE_mean**2.
EXECUTE.
SUMMARIZE
/TABLES = sampling_mean_sam2 sampling_var_sam2 sampling_sd_sam2
/FORMAT = VALIDLIST LIMIT=1.
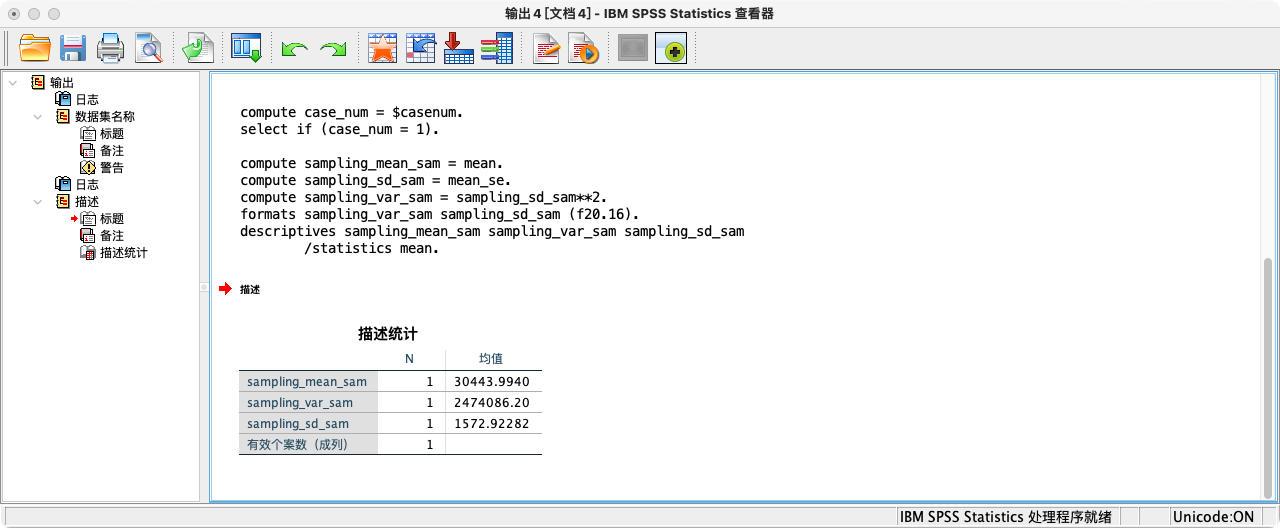
可以发现,手动计算和OMS方法得到的结果是完全一致的。
2. 根据样本信息,对总体进行区间估计
-
利用我们计算出的样本均值和标准误,我们可以为未知的总体均值构建一个置信区间。
-
案例背景:继续使用n=500的收入样本,计算总体平均收入的99%置信区间。
-
方法一:手动计算
- 公式:
样本均值 ± (给定置信度下的Z临界值 * 标准误) - 对于99%置信度,大样本(n>30)下的Z临界值约为2.58。
- 公式:
/* 假设 sampling_mean_sam1 和 sampling_sd_sam1 已计算好 */
COMPUTE interval_lower = sampling_mean_sam1 - 2.58 * sampling_sd_sam1.
COMPUTE interval_upper = sampling_mean_sam1 + 2.58 * sampling_sd_sam1.
EXECUTE.
FORMATS sampling_mean_sam1 interval_lower interval_upper (F20.16).
SUMMARIZE
/TABLES = sampling_mean_sam1 interval_lower interval_upper
/FORMAT = VALIDLIST LIMIT=1.
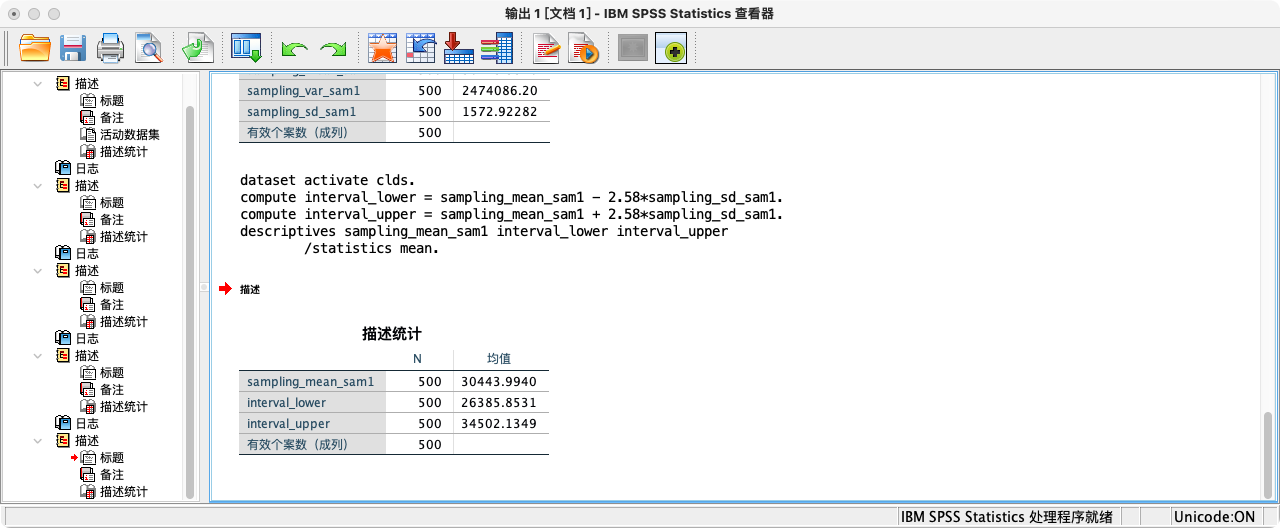
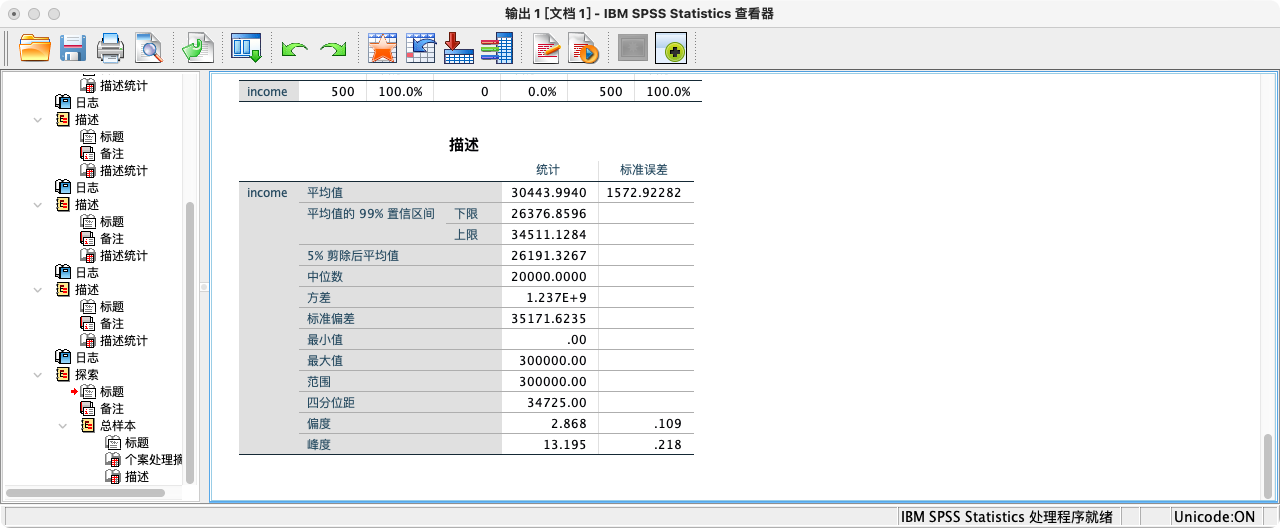
- 方法二:使用
EXAMINE命令 (推荐)
/* 在n=500的样本数据集中执行 */
EXAMINE income
/PLOT NONE
/CINTERVAL 99.
-
方法三:使用拔靴法 (Bootstrap) 修正
辅助知识点:为何使用拔靴法(Bootstrap)? 传统方法计算置信区间依赖于“抽样分布为正态分布”的理论假设。如果样本数据分布很不规则(如极度偏态、有极端值),这个假设可能不成立。拔靴法是一种强大的计算机模拟技术,它通过对现有样本进行上千次“有放回的再抽样”,来经验性地构建一个抽样分布,并据此计算置信区间。这个过程不依赖于正态假设,因此结果更为稳健(robust)。
-
点选操作:分析 → 描述统计 → 探索 → 在左侧变量列表中选择变量 → 选择统计 → 勾选描述并填入置信区间 → 继续 → 自助抽样 → 勾选执行自助抽样(填入样本数小于原始样本数) → 填入置信区间 → 继续 → 确定;
-
语法操作:
BOOTSTRAP命令本身不产生任何输出。它的作用像一个“开关”或“前缀”,用于声明紧随其后的那个分析命令(如T-TEST,REGRESSION,MEANS等)需要使用拔靴法来计算其标准误和置信区间。
BOOTSTRAP
/SAMPLING METHOD=SIMPLE
/VARIABLES TARGET=[目标变量列表] INPUT=[输入变量列表]
/CRITERIA CILEVEL=[置信水平] CITYPE=PERCENTILE NSAMPLES=[样本数].
* [这里紧跟一个常规的分析命令,例如 T-TEST, EXAMINE, REGRESSION 等].
语法说明
BOOTSTRAP- 这是命令的起始标志。
/SAMPLING METHOD=SIMPLE- 指定抽样方法。
SIMPLE(简单有放回抽样)是默认且最常用的选项。
- 指定抽样方法。
/VARIABLES指定在拔靴法抽样过程中需要关注的变量。TARGET: 指定因变量或分析的核心目标变量。INPUT: 指定自变量或分组变量。在某些分析中(如独立样本T检验、回归分析)必须指定。
/CRITERIA设置拔靴法运行的准则。CILEVEL: 指定要计算的置信度,通常为95或99。CITYPE: 指定计算置信区间的方法。PERCENTILE(百分位法)和BCa(偏态校正加速法)是两种常用且推荐的方法。NSAMPLES: 指定要生成的自助样本的数量。这个数值越大,结果越稳定,但计算时间也越长。通常推荐设置为1000到5000之间。
/* 在n=500的样本数据集中执行 */
BOOTSTRAP
/CRITERIA CILEVEL=99
NSAMPLES=1000. /* 设置重复抽样1000次 */
EXAMINE income
/PLOT NONE
/CINTERVAL 99.
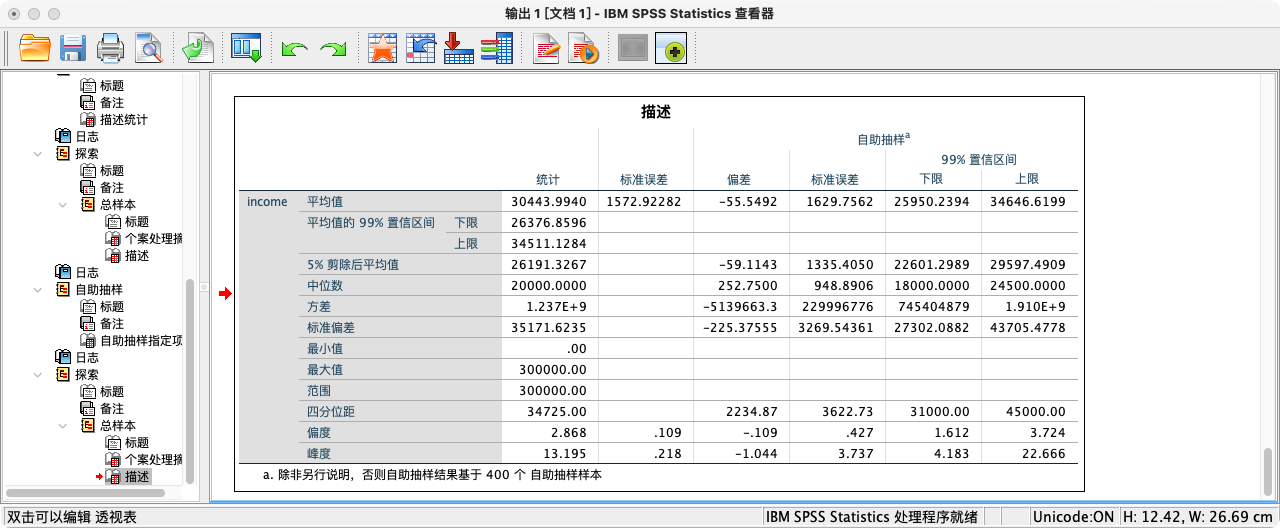
- 注意观察拔靴法生成的置信区间(在Bootstrap表格中)与传统方法计算的区间(在Descriptives表格中)的差异。
随堂练习
- 以生活幸福感(
I7_6_1)作为变量,随机抽取400个样本(随机种子为20200501)。在总体情况未知的前提下,计算样本均值、(校正后的)样本方差,并估计出标准误。 - 利用该样本,计算生活幸福感总体均值的95%置信区间。
3. 绘制抽样分布图和区间分布图
- 注意:以下为Stata命令
- 抽样分布图
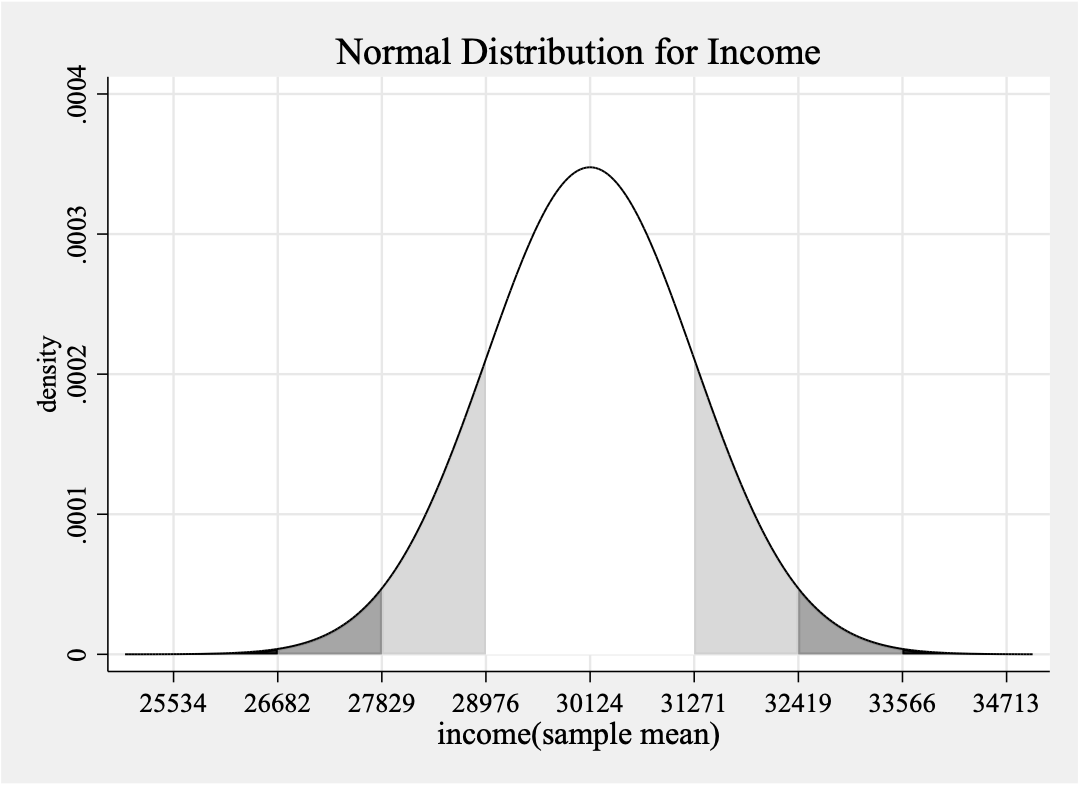
local path "/Users/ginglam/Public/data"
#delimit;
graph twoway
(function y=normalden(x,30123.83584,1147.37221), range(25000 35000)lw(medthin)color(gs16) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(31271.20805 32418.58026)lw(medthin)color(gs13) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(32418.58026 33565.95247)lw(medthin)color(gs9) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(33565.95247 34713.32468)lw(medthin)color(gs0) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(27829.09142 28976.46363)lw(medthin)color(gs13) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(26681.71921 27829.09142)lw(medthin)color(gs9) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(25534.34700 26681.71921)lw(medthin)color(gso) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(25000 35000)lw(medthin)lpattern(solid)),
title("Normal Distribution for Income")
xtitle("income(sample mean)", size(medlarge)) ytitle("density")
legend(off)
xlabel(25534 26682 27829 28976 30124 31271 32419 33566 34713, grid gmin gmax);
graph export "`path'\Week 10\1.normal_income(with notation).png", as(png) width(4000) replace;
#delimit cr
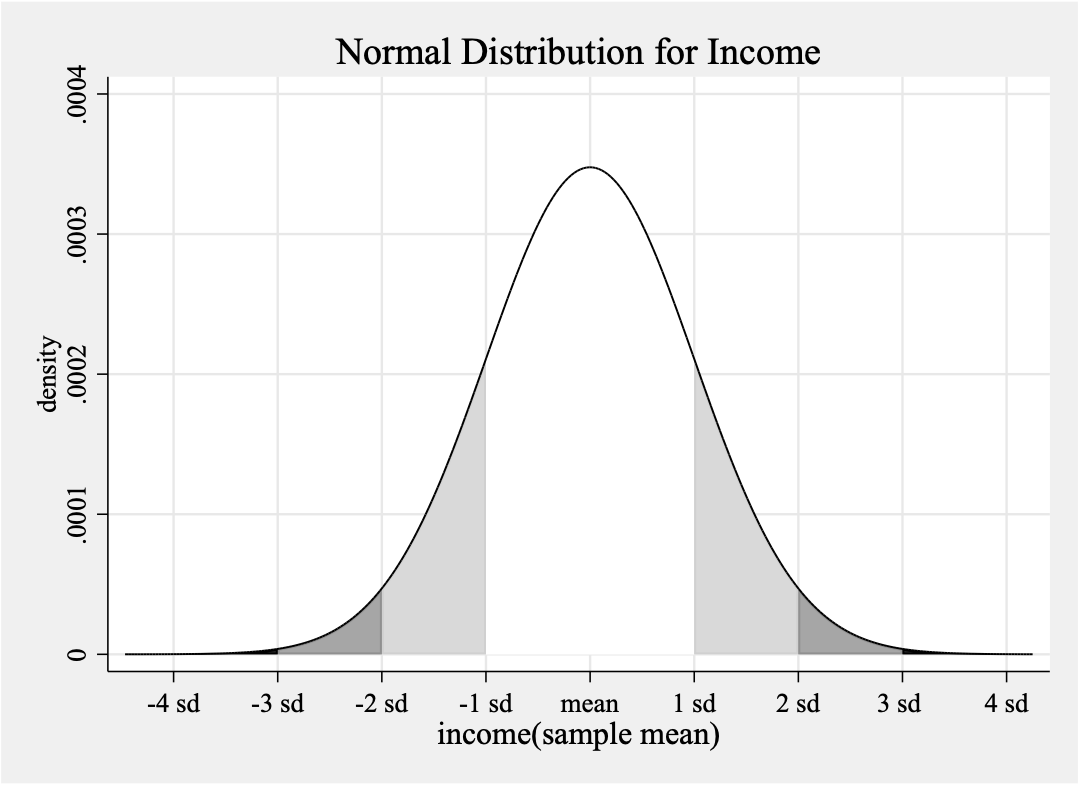
#delimit;
graph twoway
(function y=normalden(x,30123.83584,1147.37221), range(25000 35000)lw(medthin)color(gs16) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(31271.20805 32418.58026)lw(medthin)color(gs13) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(32418.58026 33565.95247)lw(medthin)color(gs9) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(33565.95247 34713.32468)lw(medthin)color(gs0) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(27829.09142 28976.46363)lw(medthin)color(gs13) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(26681.71921 27829.09142)lw(medthin)color(gs9) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(25534.34700 26681.71921)lw(medthin)color(gso) recast(area))
(function y=normalden(x,30123.83584,1147.37221), range(25000 35000)lw(medthin)lpattern(solid)),
title("Normal Distribution for Income")
xtitle("income(sample mean)", size(medlarge)) ytitle("density")
legend(off)
xlabel(25534.34700 "-4 sd" 26681.71921 "-3 sd" 27829.09142 "-2 sd" 28976.46363 "-1 sd" 30123.83584 "mean" 31271.20805 "1 sd" 32418.58026 "2 sd" 33565.95247 "3 sd " 34713.32468 "4 sd", grid gmin gmax);
graph export "`path'\Week 10\2.normal_income(without notation).png", as(png) width(4000) replace;
#delimit cr
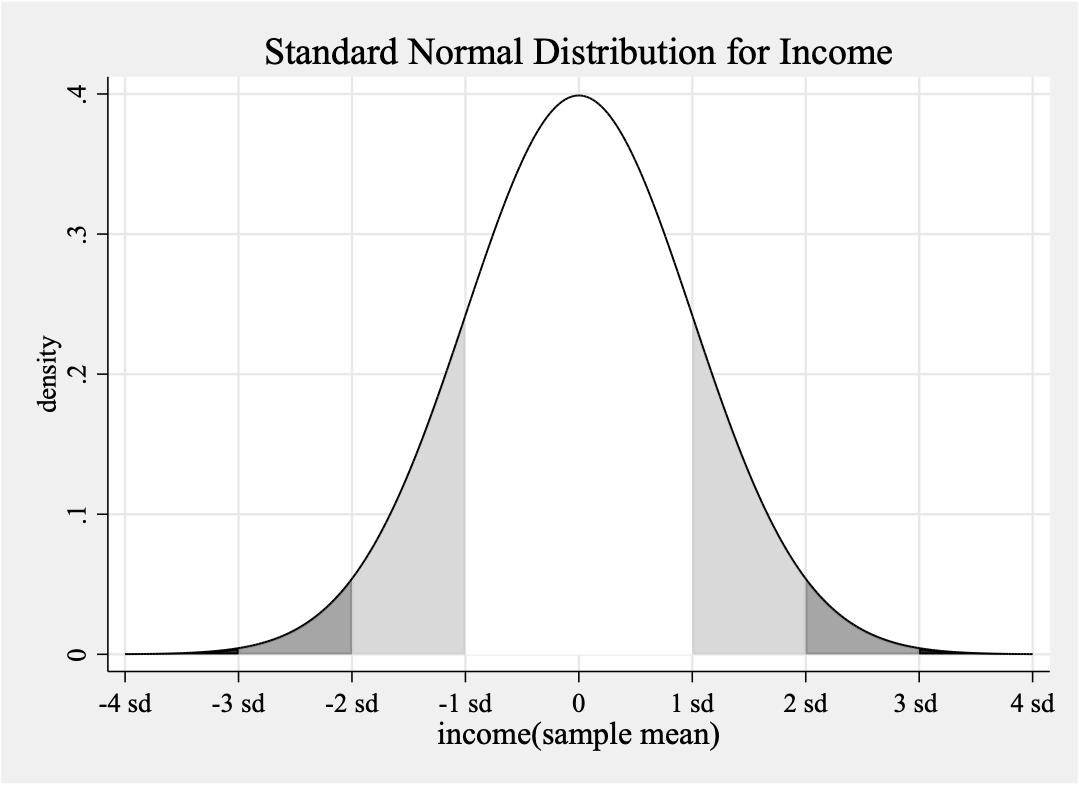
- 标准正态分布
#delimit;
graph twoway
(function y=normalden(x), range(-4 4)lw(medthin)color(gs16) recast(area))
(function y=normalden(x), range(1 2)lw(medthin)color(gs13) recast(area))
(function y=normalden(x), range(2 3)lw(medthin)color(gs9) recast(area))
(function y=normalden(x), range(3 4)lw(medthin)color(gs0) recast(area))
(function y=normalden(x), range(-2 -1)lw(medthin)color(gs13) recast(area))
(function y=normalden(x), range(-3 -2)lw(medthin)color(gs9) recast(area))
(function y=normalden(x), range(-4 -3)lw(medthin)color(gso) recast(area))
(function y=normalden(x), range(-4 4)lw(medthin)lpattern(solid)),
title("Standard Normal Distribution for Income")
xtitle("income(sample mean)", size(medlarge)) ytitle("density")
legend(off)
xlabel(-4 "-4 sd" -3 "-3 sd" -2 "-2 sd" -1 "-1 sd" 0 "0" 1 "1 sd" 2 "2 sd" 3 "3 sd " 4 "4 sd", grid gmin gmax);
graph export "`path'\Week 10\3.standard normal_income(with notation).png", as(png) width(4000) replace;
#delimit cr
- 绘制区间分布图
cd "`path'\data"
use clds2016_i.dta,clear
drop if I3a_6 == . | I3a_6 < 0
rename I3a_6 income
foreach i of numlist 1(1)100 {
preserve
set seed `i'0430
sample 500,count
ci mean income,level(95)
gen income_lower = r(lb)
gen income_upper = r(ub)
keep if _n == 1
keep income_lower income_upper
sxpose,clear force
destring _var1,replace
rename _var1 interval_`i'
gen id = _n
gen id_`i' = `i'
sa "simulation4/income_`i'.dta",replace
restore
}
cd "`path'\data\simulation4"
use income_1.dta,clear
foreach i of numlist 2(1)100 {
merge 1:1 id using income_`i'.dta,nogen
}
sa income_all.dta,replace
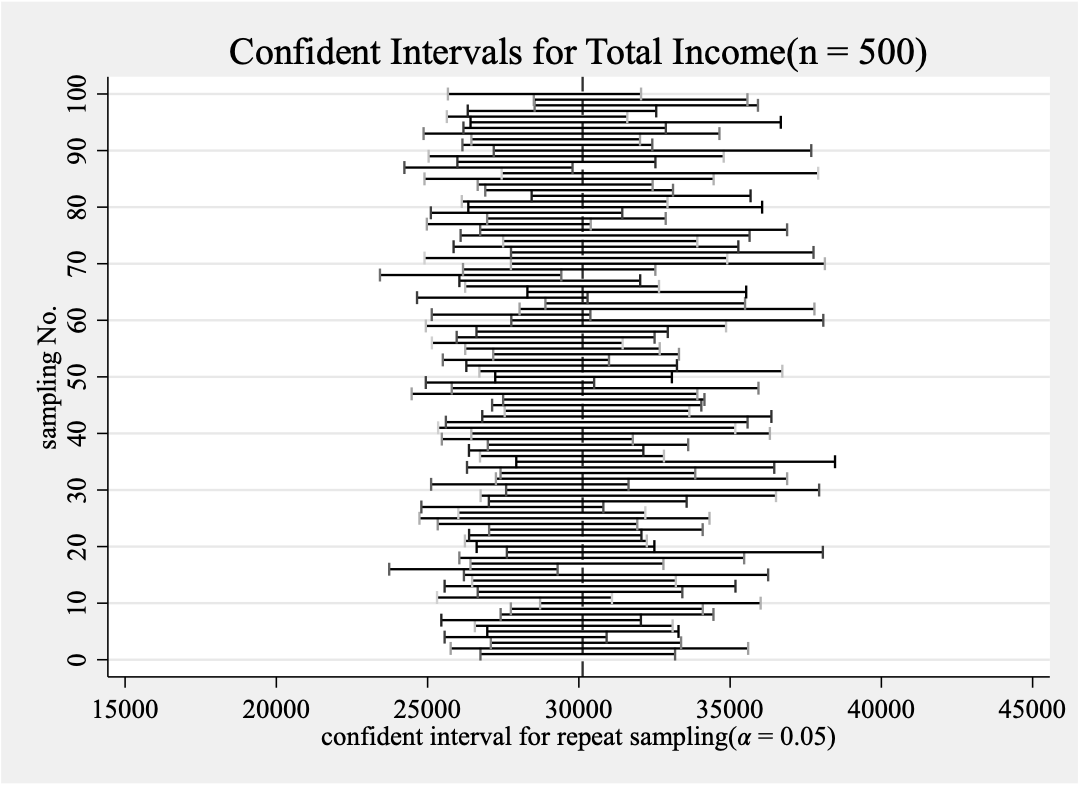
- 将重复抽样结果绘制在同一张图上
use income_all,clear
local c "connect"
local v "interval"
local s "msymbol(pipe)"
local l "lw(medthick)"
#delimit;
twoway (`c' id_1 `v'_1,`s'`l')(`c' id_2 `v'_2,`s'`l')
(`c' id_3 `v'_3,`s'`l')(`c' id_4 `v'_4,`s'`l')
(`c' id_5 `v'_5,`s'`l')(`c' id_6 `v'_6,`s'`l'),
xline(30123.83584131327,lpattern(dash))legend(off)
title("Confident Intervals for Total Income(n = 500)")
xtitle("confident interval for repeat sampling(𝛼 = 0.05)") ytitle("sampling No.")
xlabel(15000(5000)45000)ylabel(0(1)6);
graph export "`path'\Week 10\4.confident interval.png", as(png) width(4000) replace;
twoway (`c' id_1 `v'_1,`s')(`c' id_2 `v'_2,`s')
(`c' id_3 `v'_3,`s')(`c' id_4 `v'_4,`s')
(`c' id_5 `v'_5,`s')(`c' id_6 `v'_6,`s')
(`c' id_7 `v'_7,`s')(`c' id_8 `v'_8,`s')
(`c' id_9 `v'_9,`s')(`c' id_10 `v'_10,`s')
(`c' id_11 `v'_11,`s')(`c' id_12 `v'_12,`s')
(`c' id_13 `v'_13,`s')(`c' id_14 `v'_14,`s')
(`c' id_15 `v'_15,`s')(`c' id_16 `v'_16,`s')
(`c' id_17 `v'_17,`s')(`c' id_18 `v'_18,`s')
(`c' id_19 `v'_19,`s')(`c' id_20 `v'_20,`s')
(`c' id_21 `v'_21,`s')(`c' id_22 `v'_22,`s')
(`c' id_23 `v'_23,`s')(`c' id_24 `v'_24,`s')
(`c' id_25 `v'_25,`s')(`c' id_26 `v'_26,`s')
(`c' id_27 `v'_27,`s')(`c' id_28 `v'_28,`s')
(`c' id_29 `v'_29,`s')(`c' id_30 `v'_30,`s')
(`c' id_31 `v'_31,`s')(`c' id_32 `v'_32,`s')
(`c' id_33 `v'_33,`s')(`c' id_34 `v'_34,`s')
(`c' id_35 `v'_35,`s')(`c' id_36 `v'_36,`s')
(`c' id_37 `v'_37,`s')(`c' id_38 `v'_38,`s')
(`c' id_39 `v'_39,`s')(`c' id_40 `v'_40,`s')
(`c' id_41 `v'_41,`s')(`c' id_42 `v'_42,`s')
(`c' id_43 `v'_43,`s')(`c' id_44 `v'_44,`s')
(`c' id_45 `v'_45,`s')(`c' id_46 `v'_46,`s')
(`c' id_47 `v'_47,`s')(`c' id_48 `v'_48,`s')
(`c' id_49 `v'_49,`s')(`c' id_50 `v'_50,`s')
(`c' id_51 `v'_51,`s')(`c' id_52 `v'_52,`s')
(`c' id_53 `v'_53,`s')(`c' id_54 `v'_54,`s')
(`c' id_55 `v'_55,`s')(`c' id_56 `v'_56,`s')
(`c' id_57 `v'_57,`s')(`c' id_58 `v'_58,`s')
(`c' id_59 `v'_59,`s')(`c' id_60 `v'_60,`s')
(`c' id_61 `v'_61,`s')(`c' id_62 `v'_62,`s')
(`c' id_63 `v'_63,`s')(`c' id_64 `v'_64,`s')
(`c' id_65 `v'_65,`s')(`c' id_66 `v'_66,`s')
(`c' id_67 `v'_67,`s')(`c' id_68 `v'_68,`s')
(`c' id_69 `v'_69,`s')(`c' id_70 `v'_70,`s')
(`c' id_71 `v'_71,`s')(`c' id_72 `v'_72,`s')
(`c' id_73 `v'_73,`s')(`c' id_74 `v'_74,`s')
(`c' id_75 `v'_75,`s')(`c' id_76 `v'_76,`s')
(`c' id_77 `v'_77,`s')(`c' id_78 `v'_78,`s')
(`c' id_79 `v'_79,`s')(`c' id_80 `v'_80,`s')
(`c' id_81 `v'_81,`s')(`c' id_82 `v'_82,`s')
(`c' id_83 `v'_83,`s')(`c' id_84 `v'_84,`s')
(`c' id_85 `v'_85,`s')(`c' id_86 `v'_86,`s')
(`c' id_87 `v'_87,`s')(`c' id_88 `v'_88,`s')
(`c' id_89 `v'_89,`s')(`c' id_90 `v'_90,`s')
(`c' id_91 `v'_91,`s')(`c' id_92 `v'_92,`s')
(`c' id_93 `v'_93,`s')(`c' id_94 `v'_94,`s')
(`c' id_95 `v'_95,`s')(`c' id_96 `v'_96,`s')
(`c' id_97 `v'_97,`s')(`c' id_98 `v'_98,`s')
(`c' id_99 `v'_99,`s')(`c' id_100 `v'_100,`s'),
xline(30123.83584131327,lpattern(dash))legend(off)
title("Confident Intervals for Total Income(n = 500)")
xtitle("confident interval for repeat sampling(𝛼 = 0.05)") ytitle("sampling No.")
xlabel(15000(5000)45000)ylabel(0(10)100);
graph export "`path'\Week 10\5.confident interval.png", as(png) width(4000) replace;
#delimit cr
4.编制均值表
- 均值表
MEANS命令是SPSS中用于分组计算描述性统计量的快捷工具。它的核心功能是为一个或多个连续变量(因变量),按照一个或多个分类变量(自变量)的分组,来计算其均值、标准差、样本量等统计指标。 MEANS与FREQUENCIES/DESCRIPTIVES的区别FREQUENCIES和DESCRIPTIVES主要用于单个变量的整体描述。MEANS则专注于探索变量之间的关系:一个分类变量如何影响一个连续变量的均值。它是进行T检验和方差分析(ANOVA)之前,进行数据探索的理想工具。
- 点选操作:分析 → 比较平均值 → 平均值 → 在左侧变量列表中选择变量(若分组,在层中选择分组变量) → 点击“选项” → 选择统计量 → 继续 → 可选自助抽样 → 勾选执行自助抽样(填入样本数小于原始样本数) → 填入置信区间 → 继续 → 确定
- 语法操作:
MEANS TABLES = dependent_var BY group_var1 [BY group_var2 ...]
/CELLS = [统计量1] [统计量2] ...
-
MEANS TABLES = dependent_var BY group_var1 ...这是命令的主体,用于定义表格的结构。dependent_var: 指定一个或多个你想要计算其统计量的连续变量(因变量)。BY: 这是一个关键字,用于引出分组变量。group_var1: 指定一个或多个用于分组的分类变量(自变量)。- 如果省略
BY和分组变量,MEANS命令将只计算整个数据集的描述统计量。
-
/CELLS用于指定你希望在输出表格的单元格中显示哪些统计量。MEAN: 均值 (默认)。COUNT: 个案数/样本量 (默认)。STDDEV: 标准差 (默认)。VAR: 方差。SEMEAN: 均值标准误。MIN: 最小值。MAX: 最大值。SUM: 总和。SKEW: 偏度。KURT: 峰度。ALL: 显示所有可用的统计量。DEFAULT: 显示默认的三个统计量 (MEAN,COUNT,STDDEV)。
案例(4-1):编制2015年总收入均值表
- 导入2016年中国劳动力动态调查数据和构造income变量
GET FILE "clds2016_i.sav".
EXECUTE.
DATASET NAME clds.
DATASET ACTIVATE clds.
SELECT IF (I3a_6 >= 0).
COMPUTE income = I3a_6.
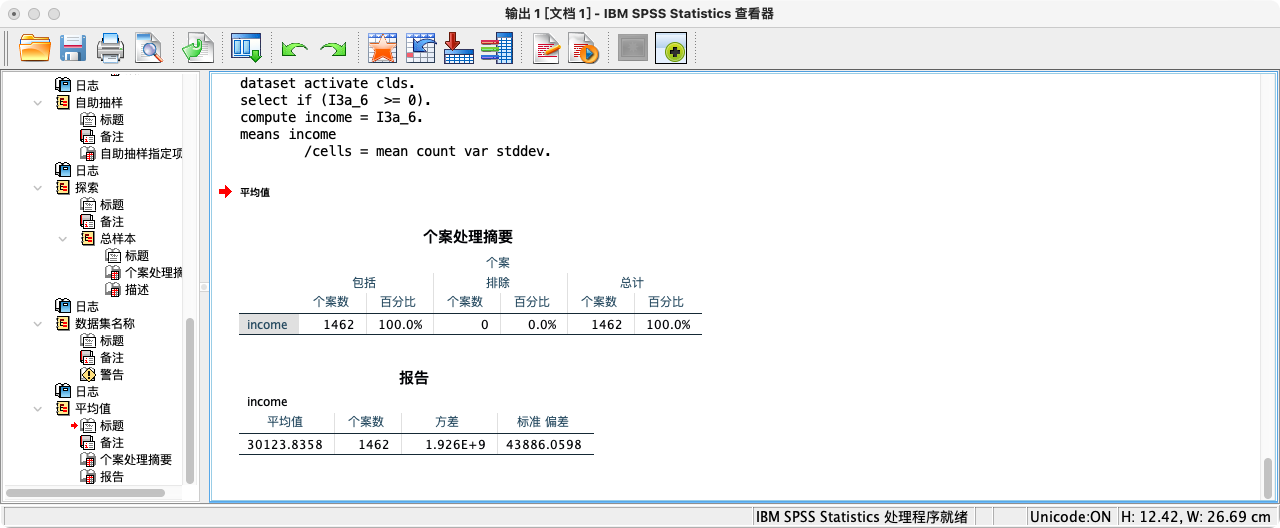
- 查看2015年总收入的均值、样本量、方差和标准差
MEANS income
/CELLS = MEAN COUNT VAR STDDEV.
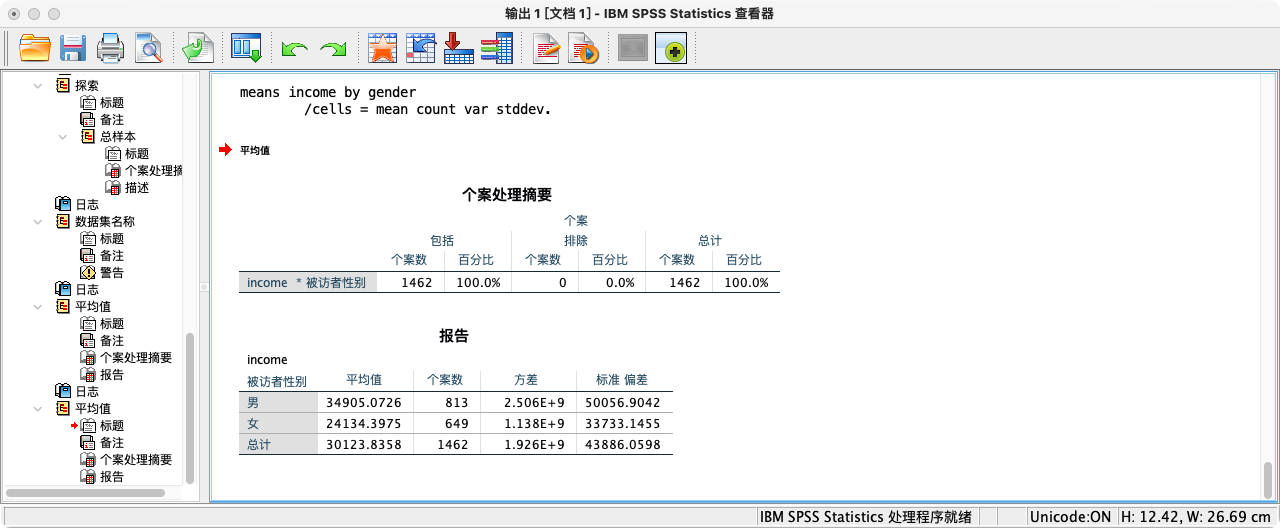
- 按性别分组描述
MEANS income BY gender
/CELLS = MEAN COUNT VAR STDDEV.
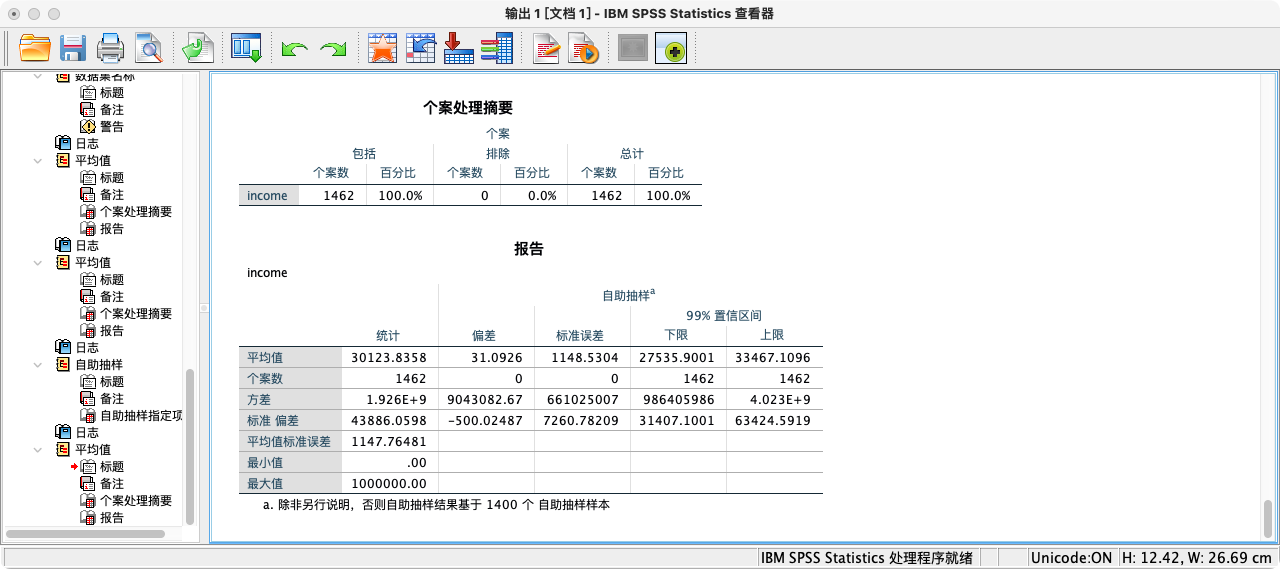
- 均值表附加功能:用拔靴法计算置信区间
BOOTSTRAP
/VARIABLES TARGET = income
/CRITERIA CILEVEL = 99 NSAMPLES = 1400.
MEANS income
/CELLS = MEAN COUNT VAR STDDEV SEMEAN MIN MAX.
随堂练习:按性别分组呈现最高教育程度(I2_1)的基本统计信息
5. 单样本均值T检验
-
核心问题:我们手中的样本均值,是否支持“总体均值等于某个特定数值”的说法?
-
假设检验的逻辑:我们先假设“总体均值确实等于那个特定值”(即虚无假设 H₀),然后计算我们手中的样本结果在这种假设下出现的概率(p-value)。如果概率极低(通常p < 0.05),我们就推翻这个假设。
-
案例:根据CLDS整个数据集(注意,现在我们将其视为一个样本),在99%的置信水平下,判断中国劳动力2015年总收入的总体均值是否等于25000元?
- H₀ (虚无假设):总体平均收入 μ = 25000元。
- H₁ (研究假设):总体平均收入 μ ≠ 25000元。
-
方法一:手动计算检验统计量 (理解内部原理)
- 我们计算一个t统计量(在大样本下近似Z统计量),它衡量了样本均值与假设的总体均值之间相差了多少个“标准误”。
- 第一种方法又可以通过三种方式判断
- 第一种方式:通过Z值判断(若Z值大于2.576,则拒绝原假设)
*第一步:计算样本均值.
AGGREGATE
/sam_income_mean = mean(income).
*第二步:计算样本离差平方.
COMPUTE diff_sq = (income - sam_income_mean)**2.
*第三步:计算样本离差平方和.
AGGREGATE
/diff_sq_sum = sum(diff_sq).
*第四步:计算总体方差(经过贝塞尔校正).
COMPUTE income_var = diff_sq_sum/(1462-1).
*第五步:计算总体标准差(经过贝塞尔校正).
COMPUTE income_sd = sqrt(income_var).
*第六步:计算抽样分布标准差.
COMPUTE income_se = income_sd/sqrt(1462).
*第七步:设定虚无假设正确时的总体均值.
*若虚无假设正确,总体均值为25000.
COMPUTE pop_income_mean = 25000.
*第八步:计算Z值(以抽样分布的标准差为单位,度量样本均值到总体均值的距离).
COMPUTE Z_score = (sam_income_mean-pop_income_mean)/income_se.
FORMATS Z_score (F20.16).
SUMMARIZE
/TABLES = Z_score
/FORMAT = VALIDLIST LIMIT=1.
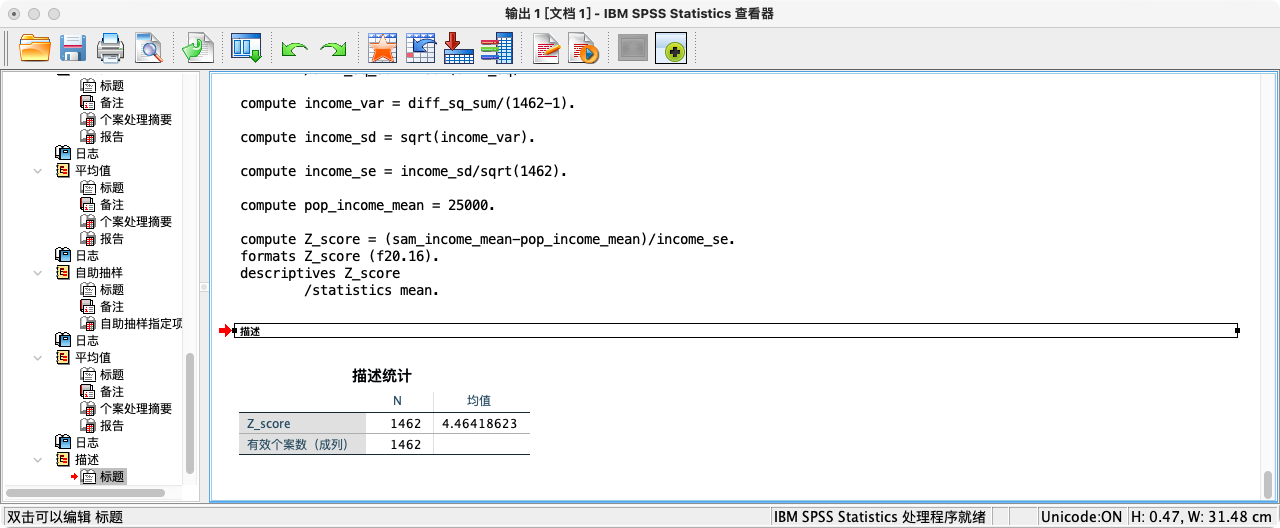
-
可知实际Z值(4.464186)大于99%置信区间的Z值(2.576),拒绝虚无假设.
- 第二种方式:通过置信区间判断(若99%置信度下得到的区间估计值不包含25000,则拒绝虚无假设)
*这里第一至六的步骤同第一种方式.
*第七步:在99%置信区间下,估计总体均值的区间上限和区间下限.
COMPUTE income_upper = sam_income_mean+2.576*income_se.
COMPUTE income_lower = sam_income_mean-2.576*income_se.
FORMATS income_lower income_upper (F20.16).
SUMMARIZE
/TABLES = income_lower income_upper
/FORMAT = VALIDLIST LIMIT=1.
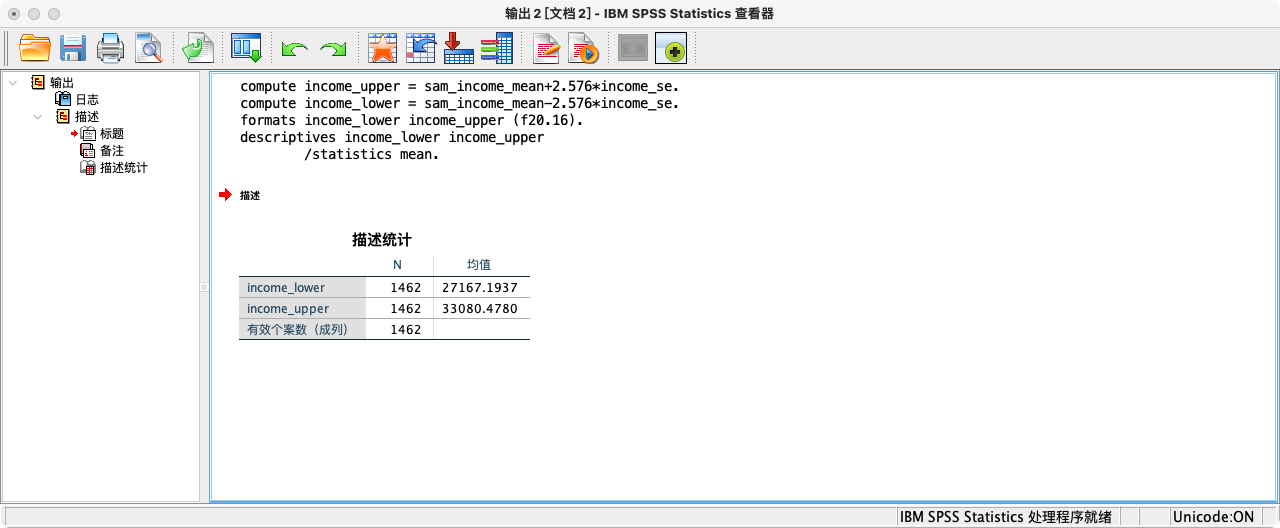
-
可知区间下限为27167.193698,不包含25000,拒绝虚无假设
- 第三种方式:通过p值判断(在99%置信区间下,p值若小于α即0.01,则拒绝虚无假设)
FORMATS sam_income_mean pop_income_mean income_se(F20.16).
SUMMARIZE
/TABLES = sam_income_mean pop_income_mean income_se
/FORMAT = VALIDLIST LIMIT=1.
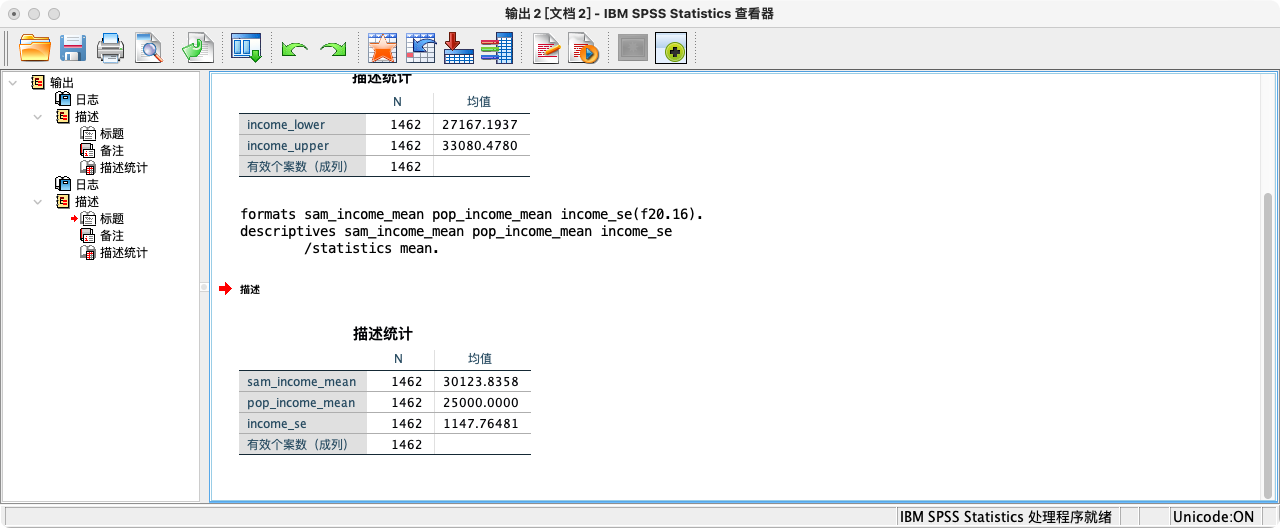
- 尽管大样本(n ≥ 30)的抽样分布为正态分布,但SPSS软件的总体均值检验默认将正态分布视作t分布的特例
- 根据t分布特性,在大样本情况下,t分布近似标准正态分布;随着样本规模增加,t分布越近似标准正态分布
- 因此,总体均值检验可以利用正态分布特性,也可以利用t分布特性
- 在正态分布下,P值等于整个正态分布的累积密度(面积=1)与样本均值处的累积密度(面积 = cdf.normal(样本均值,总体均值,抽样分布标准差)或cdf.normal(实际Z值,0,1))之差的2倍
- 在t分布下,P值等于整个t分布的累积密度(面积=1)与样本均值处的累积密度(面积 = cdf.t(实际Z值,自由度))之差的2倍
COMPUTE p_value_normal_1 = (1 - CDF.NORMAL(30123.835841,25000,1147.764807007452400))*2.
COMPUTE p_value_normal_2 = (1 - CDF.NORMAL(4.464186,0,1))*2.
COMPUTE p_value_t = (1 - CDF.T(4.464186,1461))*2.
FORMATS p_value_normal_1 p_value_normal_2 p_value_t (F20.16).
SUMMARIZE
/TABLES = p_value_normal_1 p_value_normal_2 p_value_t
/FORMAT = VALIDLIST LIMIT=1.
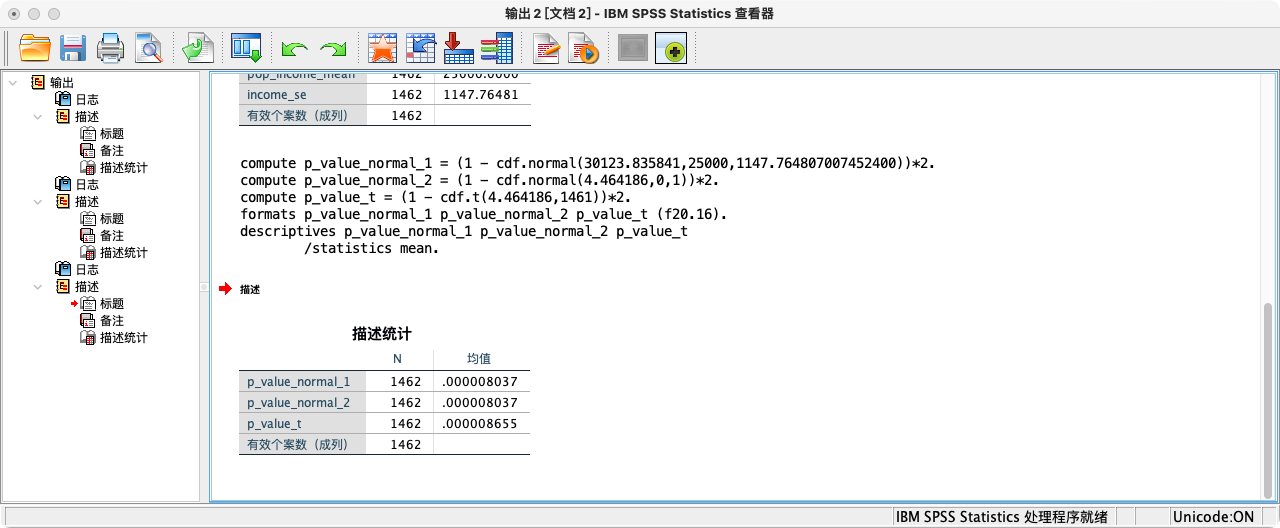
-
可知p值(=0.000008037或0.000008654714756)小于0.01,拒绝虚无假设
-
方法二:使用
T-TEST命令 (标准流程) -
点选操作:分析 → 比较平均值 → 单样本T检验 → 在左侧变量列表中选择检验变量 → 在“检验值”中填入总体均值 → 点击“选项” → 填入置信区间 → 继续 → 可选自助抽样 → 勾选执行自助抽样(填入样本数小于原始样本数) → 填入置信区间 → 继续 → 确定
-
语法操作:
T-TEST
/TESTVAL = <检验值>
/MISSING = ANALYSIS
/VARIABLES = <待检验变量>
/CRITERIA = CI(<置信水平>).
语法说明
-
T-TEST- 这是命令的起始标志。
-
/TESTVAL = <检验值>- 这是单样本T检验最核心的部分。你在这里指定一个具体的数值,这个数值就是你虚无假设 (H₀) 中声称的总体均值。
- 示例:如果我们想检验总体均值是否等于25000,就写
/TESTVAL = 25000。
-
/VARIABLES = <待检验变量>- 指定你想要进行检验的那个连续变量(即你的样本数据)。
- 示例:
/VARIABLES = income。
-
/CRITERIA = CI(<置信水平>)- 用于设定检验的标准。
CI代表Confidence Interval(置信区间)。- 括号内的数值是你想要的置信水平,通常为
0.95(95%) 或0.99(99%)。这对应于显著性水平α=0.05和α=0.01。 - 示例:
/CRITERIA = CI(0.95)。
-
/MISSING- 定义如何处理缺失值。
ANALYSIS: 按分析排除缺失值。即如果一个案在待检验变量上是缺失的,就将其从本次检验中排除 (默认)。LISTWISE: 按列表排除缺失值。如果一个案在/VARIABLES中指定的任何一个变量上是缺失的,就将其排除。在单样本检验中,ANALYSIS和LISTWISE的效果通常是相同的。
-
在这里,我们使用检验总体收入均值是否为25000元。
* 确保在完整的CLDS样本数据集中.
GET FILE "clds2016_i.sav".
SELECT IF (I3a_6 >= 0).
COMPUTE income = I3a_6.
EXECUTE.
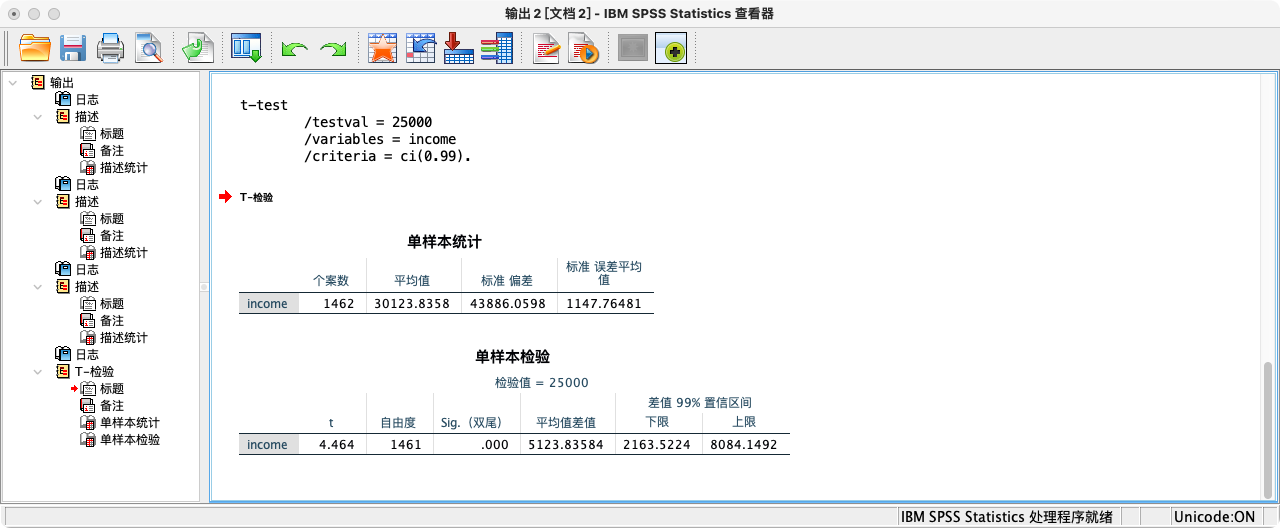
T-TEST
/TESTVAL = 25000
/VARIABLES = income
/CRITERIA = CI(0.99).
-
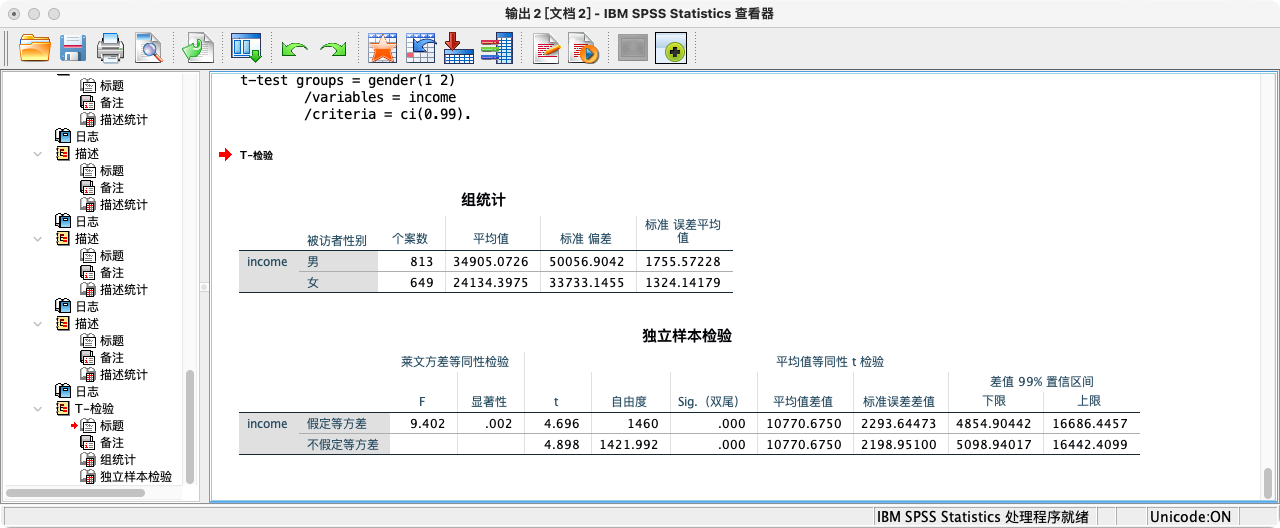
结果解读:查看“Sig. (2-tailed)”即p值。这里p值(0.000)远小于我们的显著性水平α (1-0.99=0.01),因此我们拒绝H₀。结论:样本证据强烈表明,总体平均收入不等于25000元。
-
方法三:采用拔靴法(从已有1462个样本不断重复抽取1400个样本)修正抽样分布标准误后,再进行假设检验
BOOTSTRAP
/VARIABLES TARGET = income
/CRITERIA CILEVEL = 99 NSAMPLES = 1400.
T-TEST
/TESTVAL = 25000
/VARIABLES = income
/CRITERIA = ci(0.99).
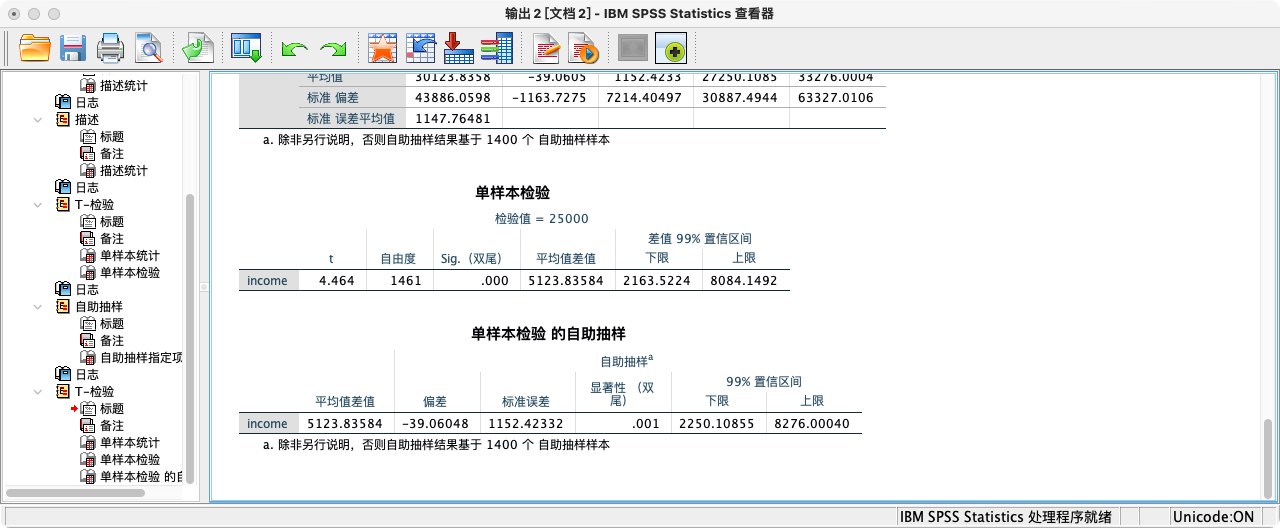
- 可知p值(=0.000714)小于0.01,拒绝虚无假设,接受研究假设
随堂练习:试检验2015年中国劳动者的平均最高教育程度(I2_1)是否等于8年,置信区间为95%
6. 独立样本均值T检验
- 核心问题:两个独立总体的均值是否存在差异?(例如,男性的总体平均收入与女性的总体平均收入是否相等?)
- 点选操作:分析 → 比较平均值 → 独立样本T检验 → 选择检验变量 → 选择分组变量(定义比较组时,填入变量取值)→ 选项(填入置信区间) → 继续 → 可选自助抽样 → 勾选执行自助抽样(填入样本数小于原始样本数) → 填入置信区间 → 继续 → 确定
- 语法操作:
T-TEST GROUPS = <分组变量>(<组1的值<组2的值>)
/MISSING = ANALYSIS
/VARIABLES = <检验变量>
/CRITERIA = CI(<置信水平>).
语法说明
T-TEST- 这是命令的起始标志。
GROUPS = <分组变量>(<组1的值<组2的值>)- 这是独立样本T检验最核心的部分,用于定义你要比较的两个组。
<分组变量>: 指定一个分类变量,这个变量的取值定义了不同的组别(例如gender)。(<组1的值<组2的值>): 在括号中,明确指定你想要进行比较的两个组的具体数值。- 示例1 (数值型): 如果在
gender变量中,1代表男性,2代表女性,那么应该写成GROUPS = gender(1 2)。 - 示例2 (字符串型): 如果分组变量是字符串,需要用单引号括起来,例如
GROUPS = group('Control' 'Treatment')。
- 示例1 (数值型): 如果在
- 注意: 传统的
T-TEST命令一次只能比较两个组。
/VARIABLES = <检验变量>指定你想要比较其均值的那个连续变量。- 示例:
/VARIABLES = income。
- 示例:
/CRITERIA = CI(<置信水平>)用于设定检验的标准和输出的置信区间。CI代表Confidence Interval(置信区间)。- 括号内的数值是你想要的置信水平,通常为
0.95(95%) 或0.99(99%)。 - 示例:
/CRITERIA = CI(0.95)。
/MISSING定义如何处理缺失值。ANALYSIS是默认且常用的选项,表示仅在当次分析所涉及的变量(即分组变量和检验变量)上存在缺失值时,才排除该个案。
案例(6-1):在99%置信水平下,判断中国男性和女性2015年总收入的总体均值是否相等?
-
请写出虚无假设、研究假设和检验过程
- H₀ (虚无假设):μ_男性 = μ_女性 (或 μ_男性 - μ_女性 = 0)。
- H₁ (研究假设):μ_男性 ≠ μ_女性。
-
方法一:在大样本(n ≥ 30)情况下,根据统计公式直接进行计算,包含三种方式 (理解内部原理)
- 第一种方法又可以通过三种方式判断
- 第一种方式:通过Z值判断(若Z值大于2.576,则拒绝原假设)
- 先查看男性样本和女性样本2015年总收入的个案数、均值、方差和标准差
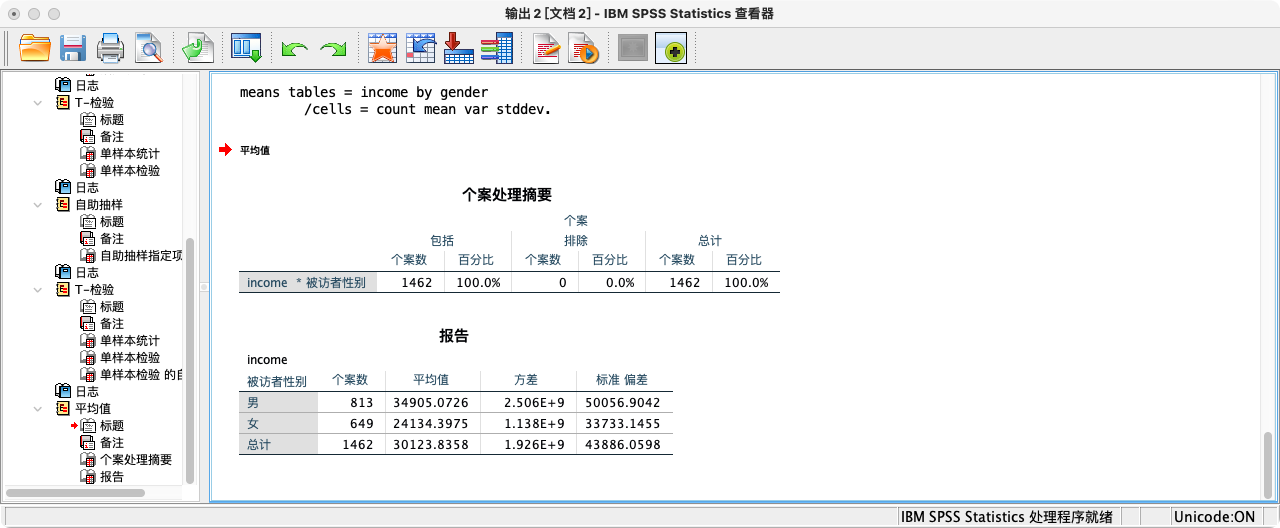
MEANS TABLES = income BY gender
/CELLS = COUNT MEAN VAR STDDEV.
*第一步:以男女样本均值之差作为总体均值之差的无偏估计.
COMPUTE male_mean = 34905.0726.
COMPUTE female_mean = 24134.397535.
COMPUTE diff_mean = male_mean - female_mean.
*第二步:计算男女样本均值之差所构成的抽样分布的方差.
COMPUTE male_n = 813.
COMPUTE female_n = 649.
COMPUTE male_var = 2505693660.582166.
COMPUTE female_var = 1137925108.002217.
COMPUTE diff_var = male_var/male_n + female_var/female_n.
COMPUTE diff_se = sqrt(diff_var).
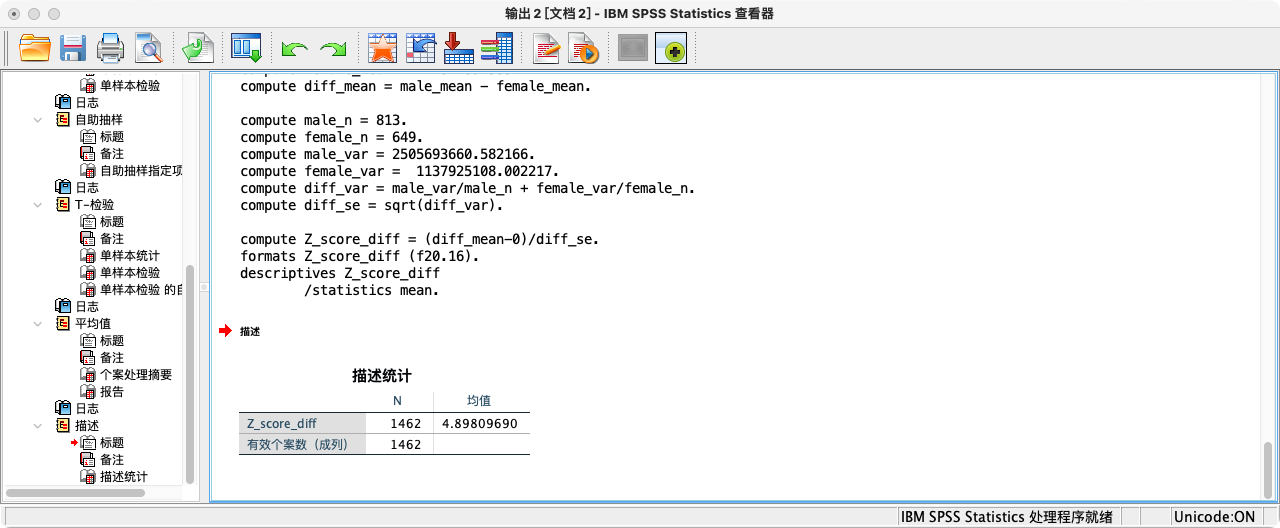
* 第三步:计算Z值(以抽样分布的标准差为单位,度量男女样本均值之差到总体均值之差即0的距离).
COMPUTE Z_score_diff = (diff_mean-0)/diff_se.
FORMATS Z_score_diff (F20.16).
SUMMARIZE
/TABLES = Z_score_diff
/FORMAT = VALIDLIST LIMIT=1.
-
可知实际Z值(4.898096895558914)大于99%置信区间的Z值(2.576),拒绝虚无假设,接受研究假设
- 第二种方式:通过置信区间区间判断(若99%置信度下得到的区间估计值不包含0,则拒绝虚无假设)
- 这里第一、二步同第一种方式
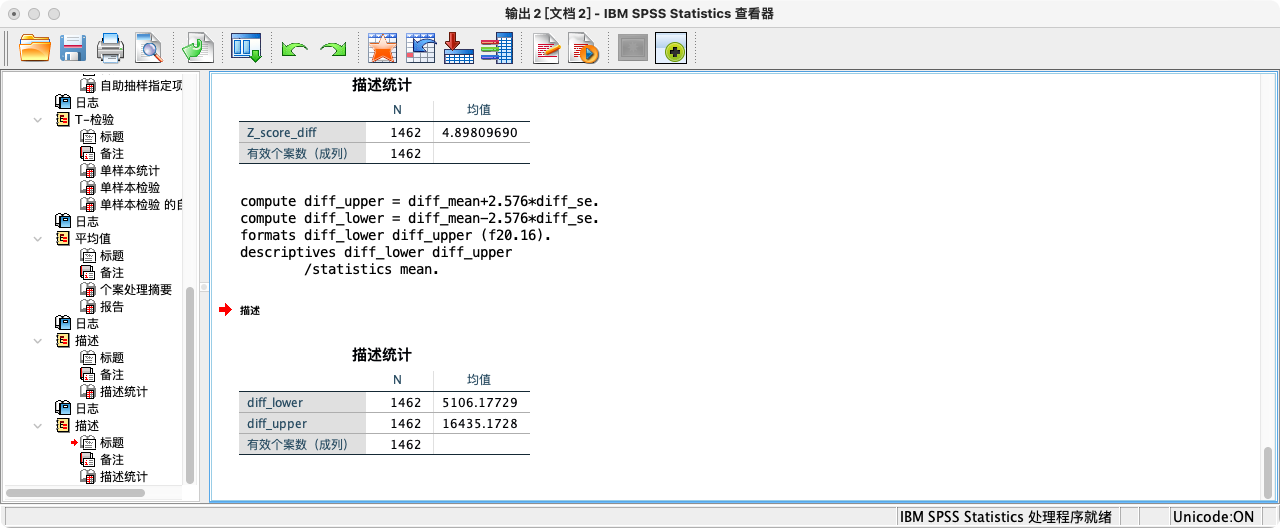
*第三步:在99%置信区间下,估计男女收入总体差值之均值的区间上限和区间下限.
COMPUTE diff_upper = diff_mean+2.576*diff_se.
COMPUTE diff_lower = diff_mean-2.576*diff_se.
FORMATS diff_lower diff_upper (F20.16).
SUMMARIZE
/TABLES = diff_lower diff_upper
/FORMAT = VALIDLIST LIMIT=1.
-
可知区间下限为5106.177290,不包含0,拒绝虚无假设,接受研究假设
- 第二种方式:通过p值判断(在99%置信区间下,p值若小于α即0.01,则拒绝虚无假设)
FORMATS diff_mean diff_se Z_score_diff(F20.16).
SUMMARIZE
/TABLES = diff_mean diff_se Z_score_diff
/FORMAT = VALIDLIST LIMIT=1.
COMPUTE p_normal_diff_1 = (1 - cdf.normal(10770.675065,0,2198.951000))*2.
COMPUTE p_normal_diff_2 = (1 - cdf.normal(4.898096895558914,0,1))*2.
FORMATS p_normal_diff_1 p_normal_diff_2 (F20.16).
SUMMARIZE
/TABLES = p_normal_diff_1 p_normal_diff_2
/FORMAT = VALIDLIST LIMIT=1.
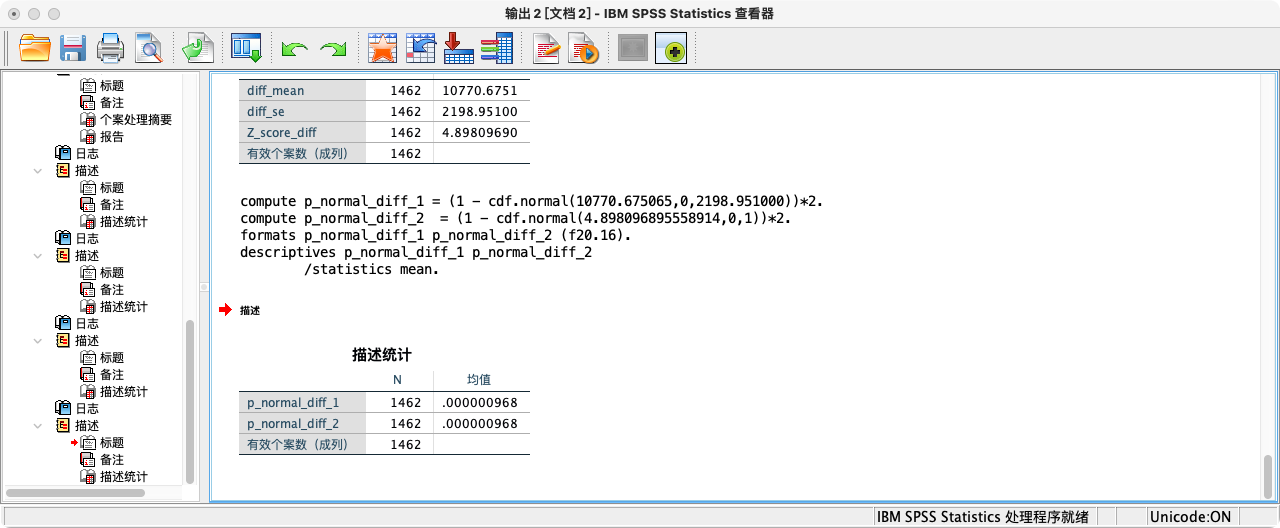
- 可知p值(=0.000000967693164)小于0.01,拒绝虚无假设,接受研究假设
若认为抽样分布为t分布,则假设检验须考虑两种情形
第一种情形:认为男性和女性2015年总收入具有相同的方差
- 由于每一种情形也具有三种判断方式,以下仅以p值为例
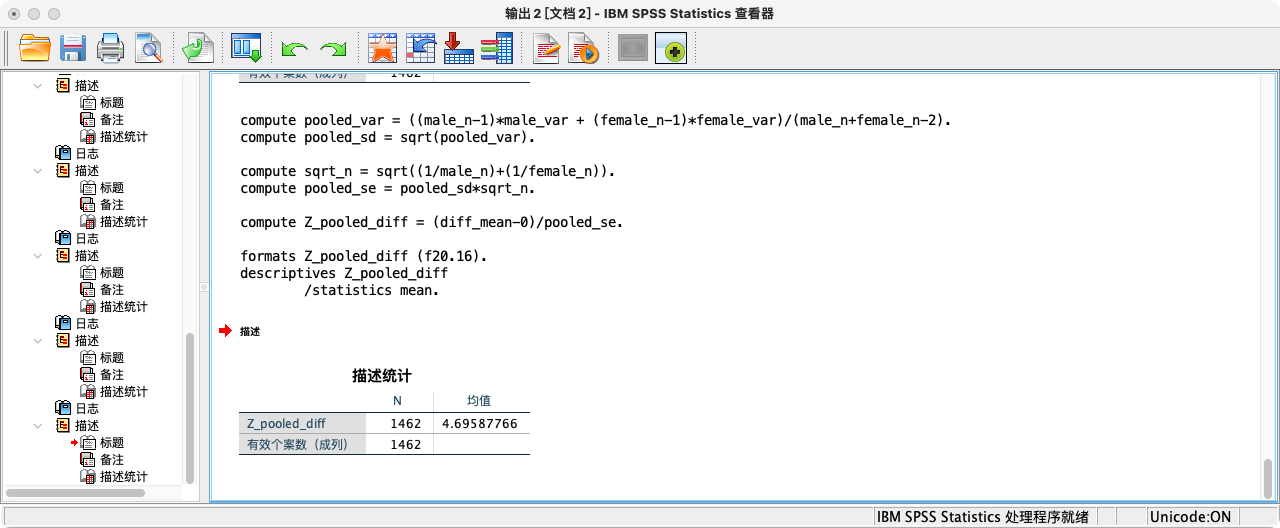
*第一步:计算男女总体收入之差的方差的混合估计量(variance of pooled estimator).
COMPUTE pooled_var = ((male_n-1)*male_var + (female_n-1)*female_var)/(male_n+female_n-2).
COMPUTE pooled_sd = sqrt(pooled_var).
*第二步:计算男女总体收入之差的抽样分布的标准差.
COMPUTE sqrt_n = sqrt((1/male_n)+(1/female_n)).
COMPUTE pooled_se = pooled_sd*sqrt_n.
*第三步:计算Z值.
COMPUTE Z_pooled_diff = (diff_mean-0)/pooled_se.
*第四步:通过p值判断(在99%置信度下,p值若小于α即0.01,则拒绝虚无假设).
FORMATS Z_pooled_diff (F20.16).
SUMMARIZE
/TABLES = Z_pooled_diff
/FORMAT = VALIDLIST LIMIT=1.
* 注意:此时自由度=男性样本数+女性样本数-2.
COMPUTE p_diff_t_1 = (1 - cdf.t(4.695877661100175,1460))*2.
FORMATS p_diff_t_1 (F20.16).
SUMMARIZE
/TABLES = p_diff_t_1
/FORMAT = VALIDLIST LIMIT=1.
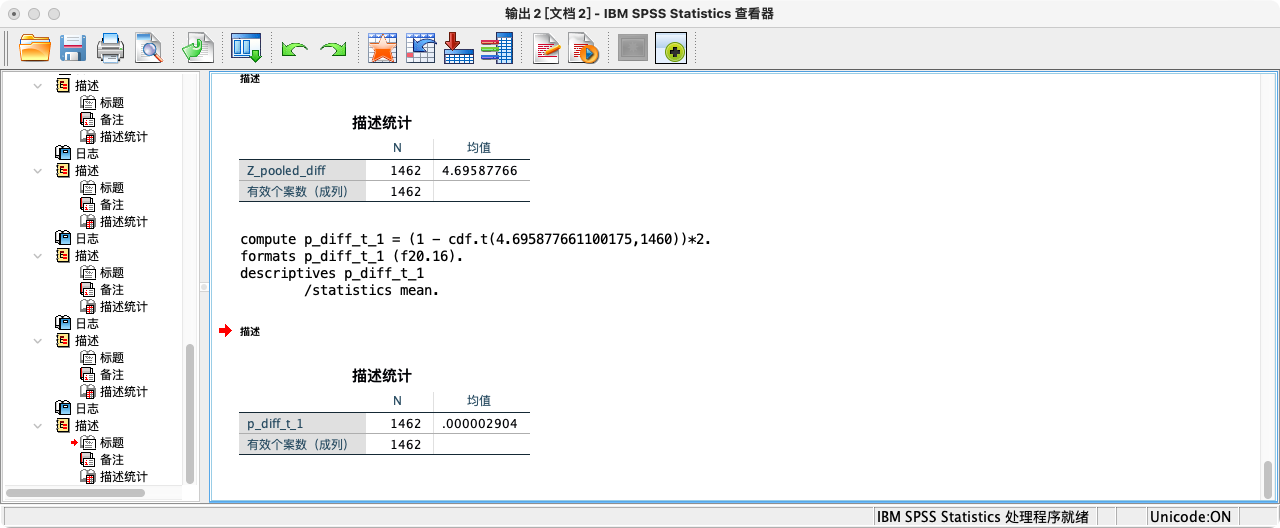
- 可知p值(=0.000002904076144)小于0.01,拒绝虚无假设,接受研究假设
第二种情形:认为男性和女性2015年总收入具有相同的方差
- 以下仅以p值为例
*第一步:计算抽样分布方差和Z值.
COMPUTE diff_var = male_var/male_n + female_var/female_n.
COMPUTE diff_se = sqrt(diff_var).
COMPUTE Z_score_diff = (diff_mean-0)/diff_se.
*第二步:计算自由度,取四舍五入值.
COMPUTE df_diff = (diff_var**2)/((((male_var/male_n)**2)/(male_n-1))+(((female_var/female_n)**2)/(female_n-1))).
*第三步:通过p值判断(在99%置信区间下,p值若小于α即0.01,则拒绝虚无假设).
FORMATS Z_score_diff df_diff (F20.16).
SUMMARIZE
/TABLES = Z_score_diff df_diff
/FORMAT = VALIDLIST LIMIT=1.
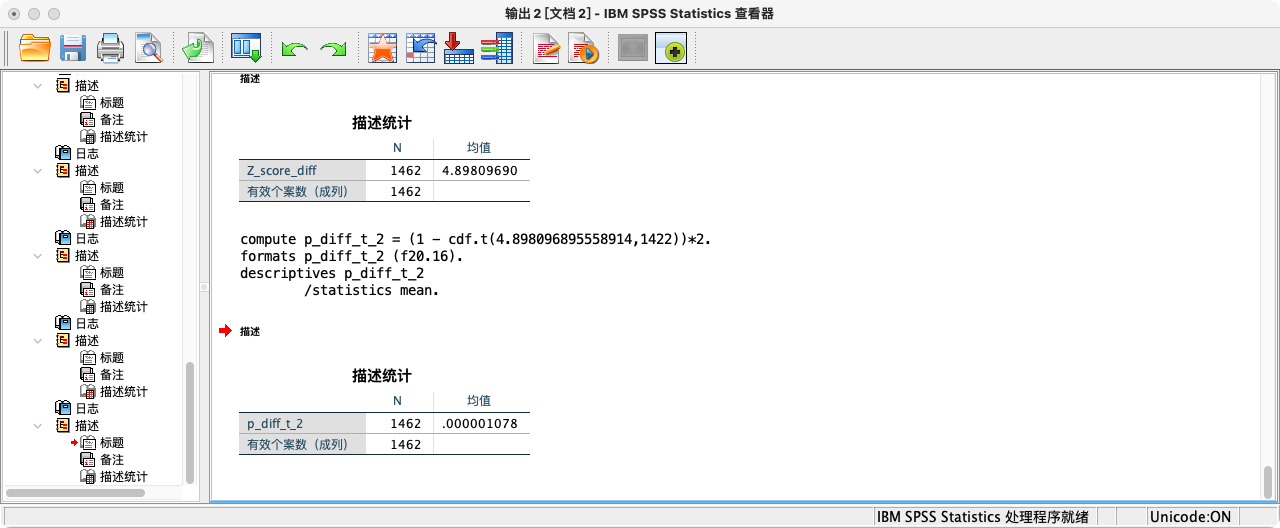
COMPUTE p_diff_t_2 = (1 - cdf.t(4.898096895558914,1422))*2.
FORMATS p_diff_t_2 (F20.16).
SUMMARIZE
/TABLES = p_diff_t_2
/FORMAT = VALIDLIST LIMIT=1.
-
可知p值(=0.000001078383088)小于0.01,拒绝虚无假设,接受研究假设
-
方法二:使用
T-TEST命令 (标准流程)
T-TEST GROUPS = gender(1 2)
/VARIABLES = income
/CRITERIA = ci(0.99).
- 方法三:采用拔靴法(从已有样本不断重复抽取1400个样本,包含男性和女性)修正抽样分布标准误后,再进行假设检验
- 注意: 独立样本总体均值检验的拔靴法需要增加
INPUT,即分组变量
- 注意: 独立样本总体均值检验的拔靴法需要增加
BOOTSTRAP
/VARIABLES TARGET = income INPUT = gender
/CRITERIA CILEVEL = 99 NSAMPLES = 1400.
T-TEST GROUPS = gender(1 2)
/VARIABLES = income
/CRITERIA = ci(0.99).
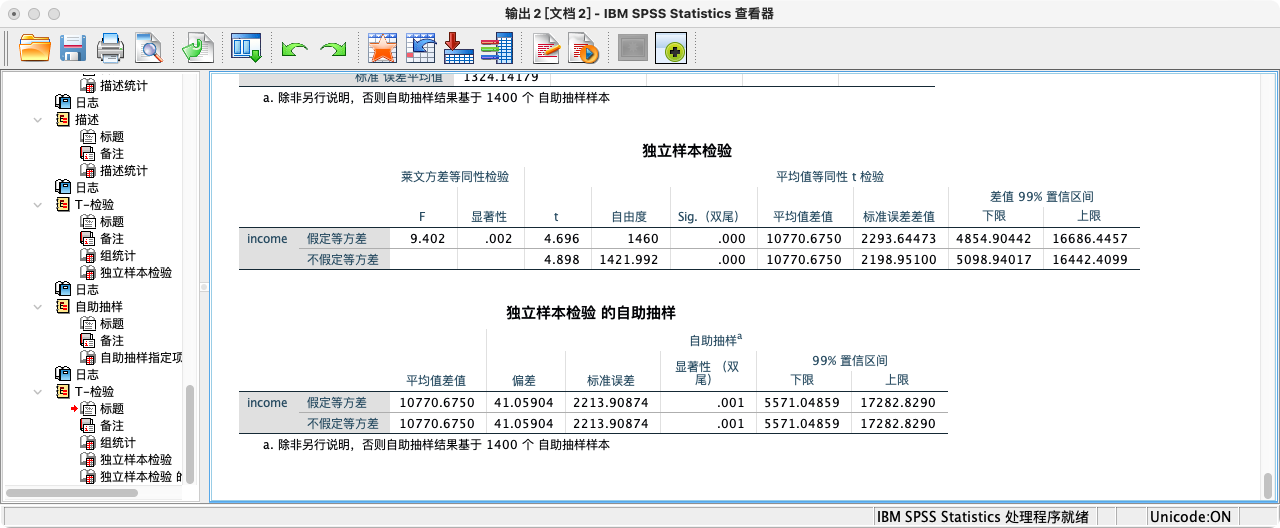
- 可知p值(=0.000714)小于0.01,拒绝虚无假设,接受研究假设.
随堂练习:试检验2015年中国男性和女性的总体平均最高教育程度是否相等,置信区间为95%.
7. 使用摘要信息进行T检验
- 使用场景:当我们没有原始数据,但从文献或报告中得知了两组的均值、标准差和样本量时,依然可以进行独立样本T检验。
- 点选操作:分析 → 比较平均值 → 摘要独立样本T检验 → 分别填入样本1和样本2的个案数、均值、标准差及标签 → 确定
- 语法操作:
SPSSINC SUMMARY TTEST
N1=<组1样本量MEAN1=<组1均值SD1=<组1标准差LABEL1="<组1标签>"
N2=<组2样本量MEAN2=<组2均值SD2=<组2标准差LABEL2="<组2标签>"
/OPTIONS CI=<置信水平>.
语法说明
SPSSINC SUMMARY TTEST- 这是命令的起始标志。
N1, MEAN1, SD1, LABEL1- 用于定义第一个样本组的摘要信息。
N1: 组1的个案数 (Sample Size)。MEAN1: 组1的均值 (Mean)。SD1: 组1的标准差 (Standard Deviation)。LABEL1: (可选) 为组1指定一个标签(字符串),用于在输出结果中清晰地标识该组。
N2, MEAN2, SD2, LABEL2- 用于定义第二个样本组的摘要信息,参数含义同上。
/OPTIONS CI=<置信水平>- 用于设定检验的标准。
CI: 指定置信区间的水平。注意,这里的数值是百分比,例如95或99,而不是小数。
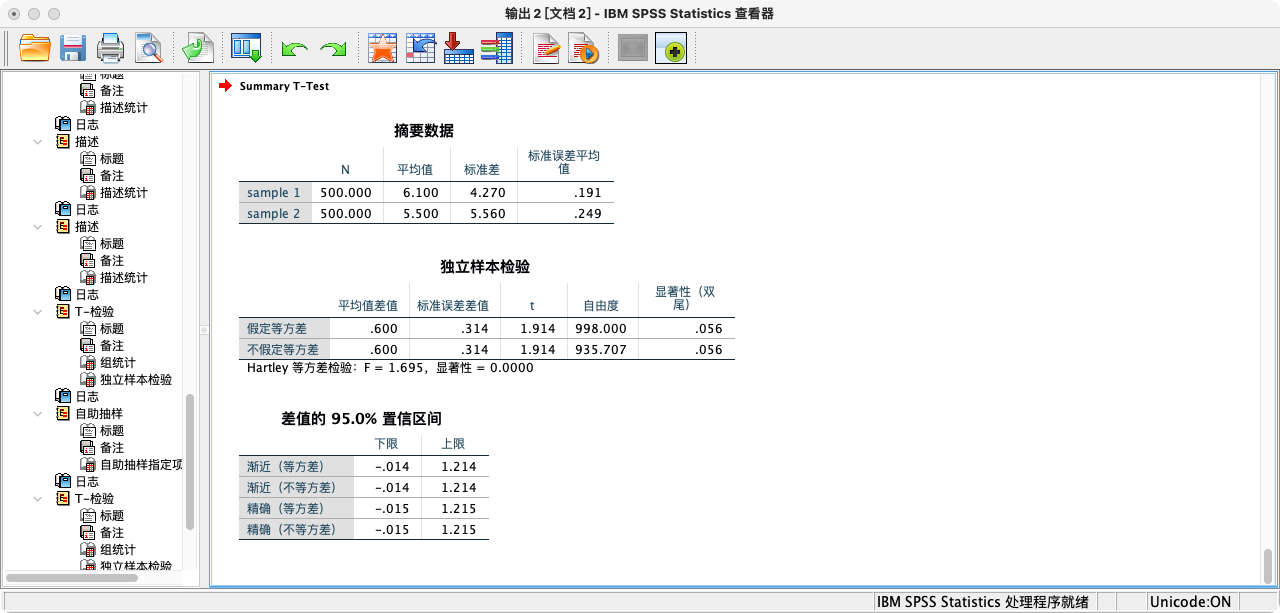
案例(7-1):若样本1个数为500,均值为6.1,标准差为4.27,样本2个案数为500,均值为5.5,标准差为5.56。
- 在95%置信度下,判断两者总体均值是否相等。请写出虚无假设、研究假设和检验过程
SPSSINC SUMMARY TTEST N1=500 MEAN1=6.1 SD1=4.27 LABEL1="样本1"
N2=500 MEAN2=5.5 SD2=5.56 LABEL2="样本2"
CI=95.
Disqus comments are disabled.