第十讲 方差分析专题
Last updated: Sep 18, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1.单因素方差分析 (One-Way ANOVA)
(1)核心问题与适用场景
- 在上一讲中,我们学习了使用独立样本T检验来比较两个独立总体的均值是否存在差异。但如果我们要比较的组别大于等于三个,例如,比较春、夏、秋、冬四个季节出生的人,其平均收入是否相同,T检验就无能为力了。
- 单因素方差分析 (One-Way ANOVA) 正是解决这个问题的标准方法。它通过分析数据的“方差”,来检验一个分类型自变量(包含三个或以上组别,也称“因子Factor”),是否对一个连续型因变量的均值产生显著影响。
辅助知识点:为何不两两做T检验? 一个常见的误区是,当面临多组比较时,反复进行两两之间的T检验。例如,比较四个季节,就做 C(4,2)=6次T检验。这种做法是错误的,因为它会急剧增加犯“第一类错误”(即错误地拒绝了本应成立的虚无假设)的概率。如果每次检验的显著性水平α设为0.05,那么6次检验后,至少犯一次错误的累积概率会远大于0.05。方差分析则通过一次性的整体检验,很好地控制了这个问题。
(2)方差分析的三大前提假设
- 为了确保ANOVA结果的有效性,我们的数据需要满足三个基本假设
- 独立性 (Independence):各组样本之间是相互独立的,一个样本的观测值不会影响到另一个样本。通过随机抽样可以保证这一点。
- 正态性 (Normality):在每一个组别(总体)中,因变量都服从正态分布。
- 方差齐性 (Homoscedasticity):各组总体的方差是相等的。
案例(1-1):出生季节与收入的关系
-
研究问题:不同季节出生的劳动者,其2015年的平均总收入是否存在显著差异?
-
虚无假设 H₀:春、夏、秋、冬四个季节出生的劳动者,其总体平均收入完全相同 (μ_春 = μ_夏 = μ_秋 = μ_冬)。
-
研究假设 H₁:至少有一个季节出生的劳动者,其总体平均收入与其他季节不完全相同。
-
第一步:数据准备与初步描述
* 筛选有效数据:收入大于0,出生月份有效.
SELECT IF (I3a_6 > 0 AND birthmonth > 0).
COMPUTE income = I3a_6.
* 将出生月份重新编码为季节.
RECODE birthmonth (3 THRU 5=1) (6 THRU 8=2) (9 THRU 11=3) (12, 1, 2=4) INTO season.
VALUE LABELS season 1 "春季" 2 "夏季" 3 "秋季" 4 "冬季".
VARIABLE LEVEL season (NOMINAL).
EXECUTE.
* 使用MEANS命令查看收入和出生季节基本信息.
MEANS income birthmonth
/CELLS = min max.
* 使用MEANS命令初步查看各组的均值、人数和标准差.
MEANS income BY season
/CELLS = MEAN COUNT STDDEV.
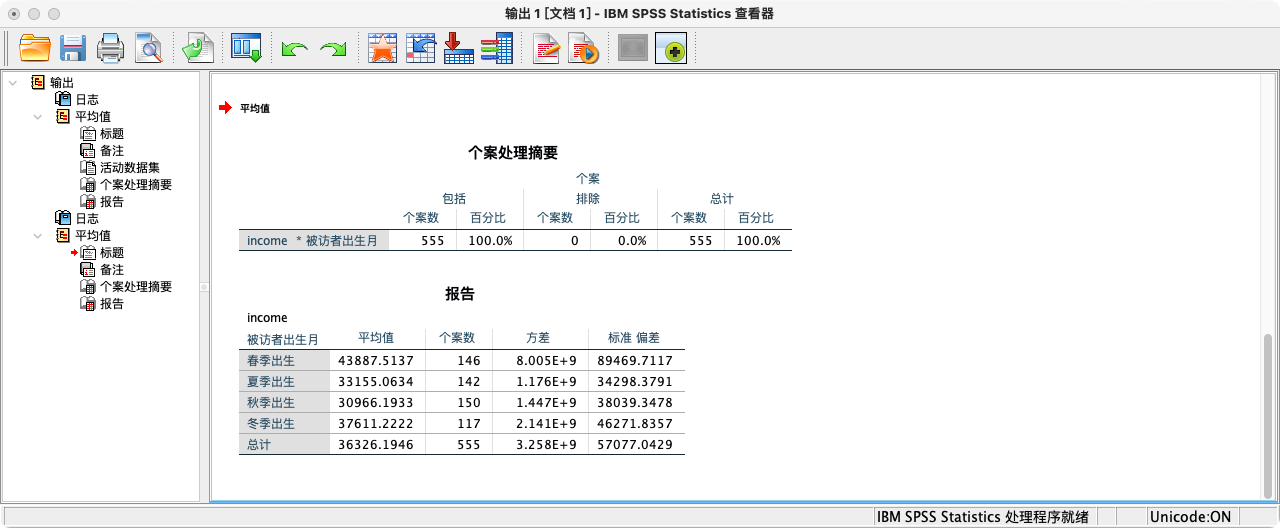
- 从描述统计表中,我们看到各组均值略有差异。但这种差异究竟是真实的总体差异,还是仅仅由抽样误差导致?这正是ANOVA需要回答的问题。
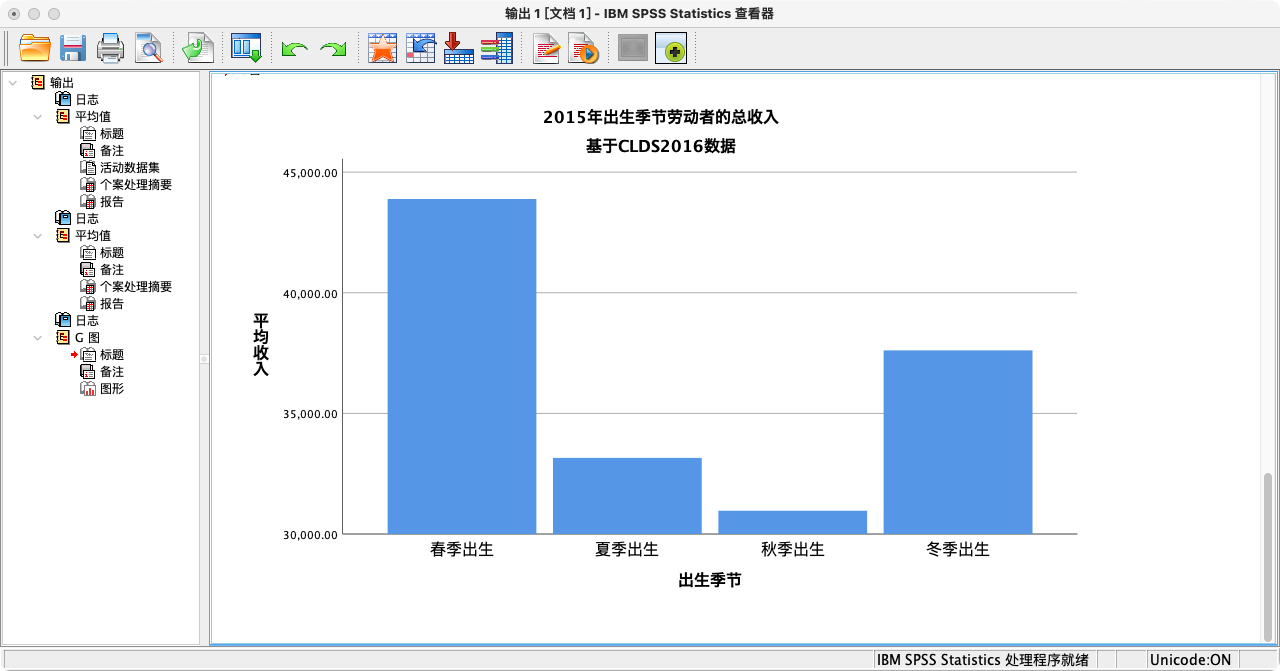
* 绘制不同季节出生的劳动者的收入条形图.
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES= birthmonth MEAN(income)[NAME = "mean_income"]
/GRAPHSPEC SOURCE = INLINE.
BEGIN GPL
SOURCE: clds=userSource(id("clds"))
DATA: birthmonth=col(source(clds), name("birthmonth"), unit.category())
DATA: mean_income=col(source(clds), name("mean_income"))
GUIDE: axis(dim(1), label("出生季节"))
GUIDE: axis(dim(2), label("平均收入"))
GUIDE: text.title(label("2015年出生季节劳动者的总收入"))
GUIDE: text.subtitle(label("基于CLDS2016数据"))
ELEMENT: interval(position(birthmonth*mean_income))
END GPL.
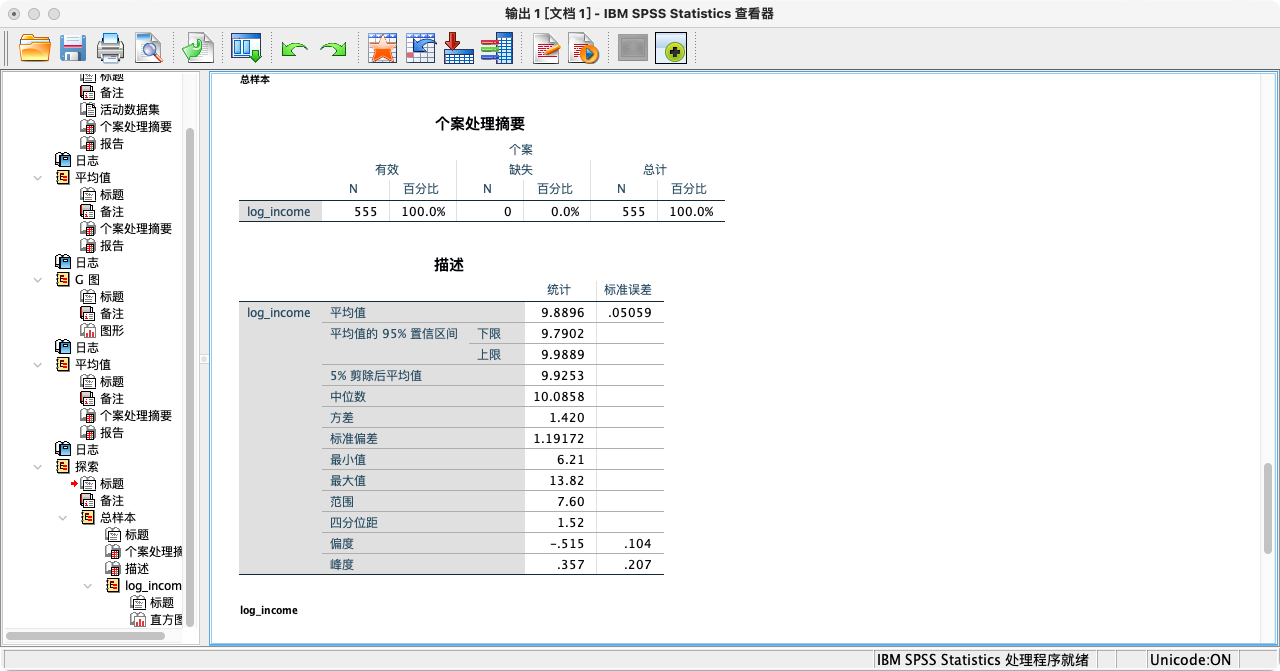
- 第二步:检验前提假设 - 正态性 (Normality)
- 收入这类变量通常呈严重的右偏态(少数高收入者将均值拉高),直接分析可能违反正态性假设。一个常用的处理方法是对数转换,它可以有效缓解偏度。
IF (income > 0) log_income = LN(I3a_6).
SELECT IF (log_income >= 0).
VARIABLE LABELS log_income "收入的自然对数".
MEANS log_income
/CELLS = MEAN COUNT VAR STDDEV MIN MAX.
EXAMINE VARIABLES = log_income
/PLOT HISTOGRAM.
EXECUTE.
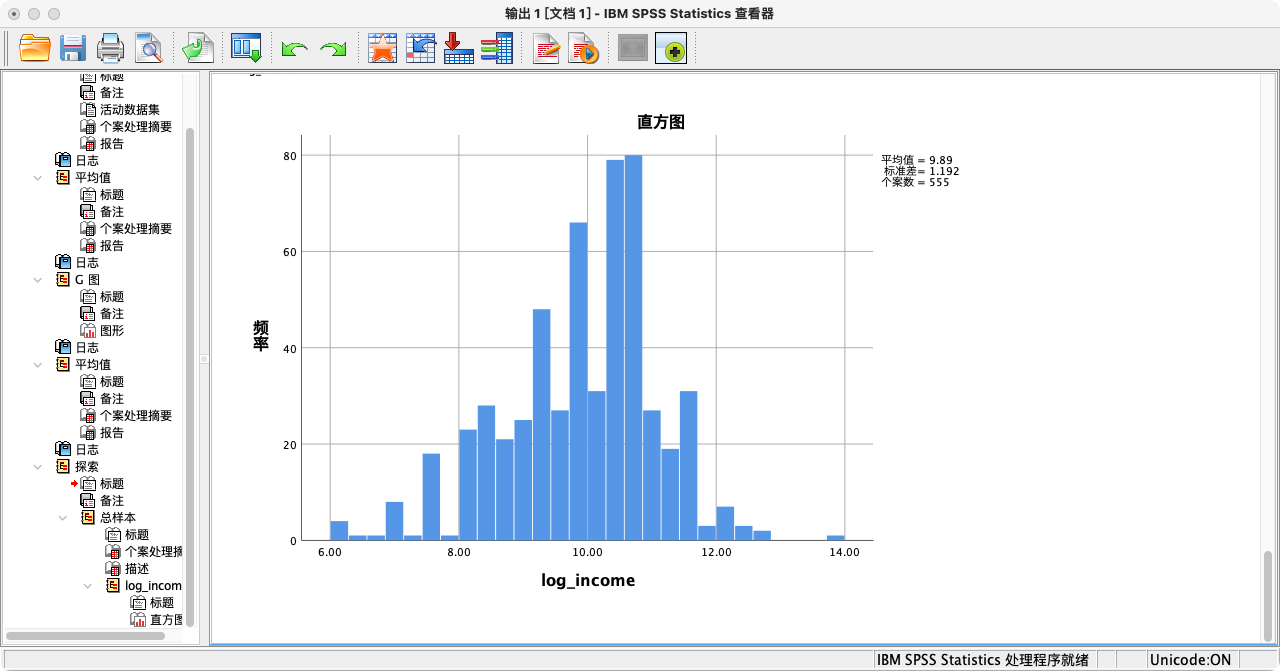
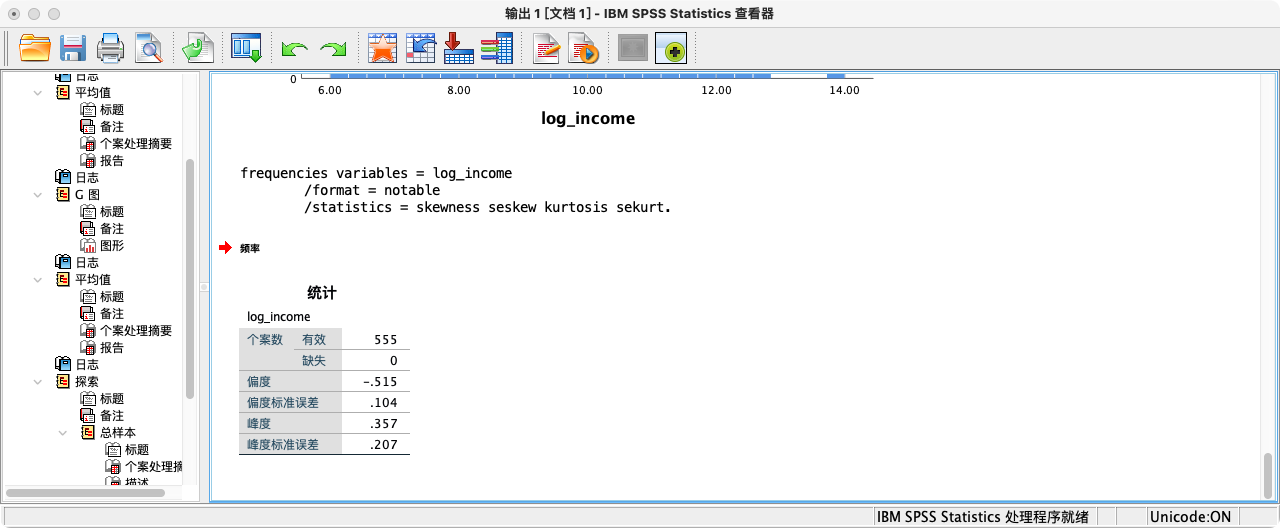
- 检验正态性的三种方法
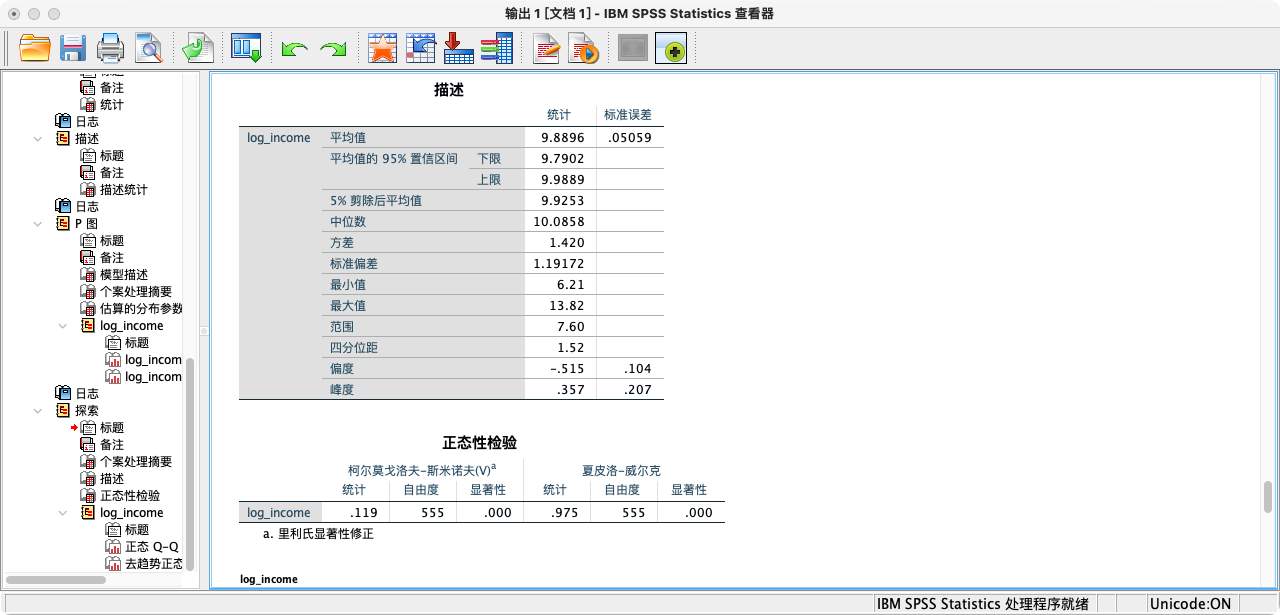
- 第一种方法:根据偏度(Skewness)和峰度(Kurtosis)来判断
- 如果一个分布是完美的正态分布,其偏度和峰度都应为0。通常,如果这两个值的绝对值小于1,我们可以认为数据近似正态。
- 使用
FREQUENCIES功能- 点选操作:分析 → 描述统计 → 频率 → 选择变量 → 取消勾选“显示频率表” → 点击“统计” → 勾选“偏度”和“峰度” → 继续 → 确定。
- 语法操作:
FREQUENCIES VARIABLES = log_income
/FORMAT = NOTABLE
/STATISTICS = SKEWNESS SESKEW KURTOSIS SEKURT.
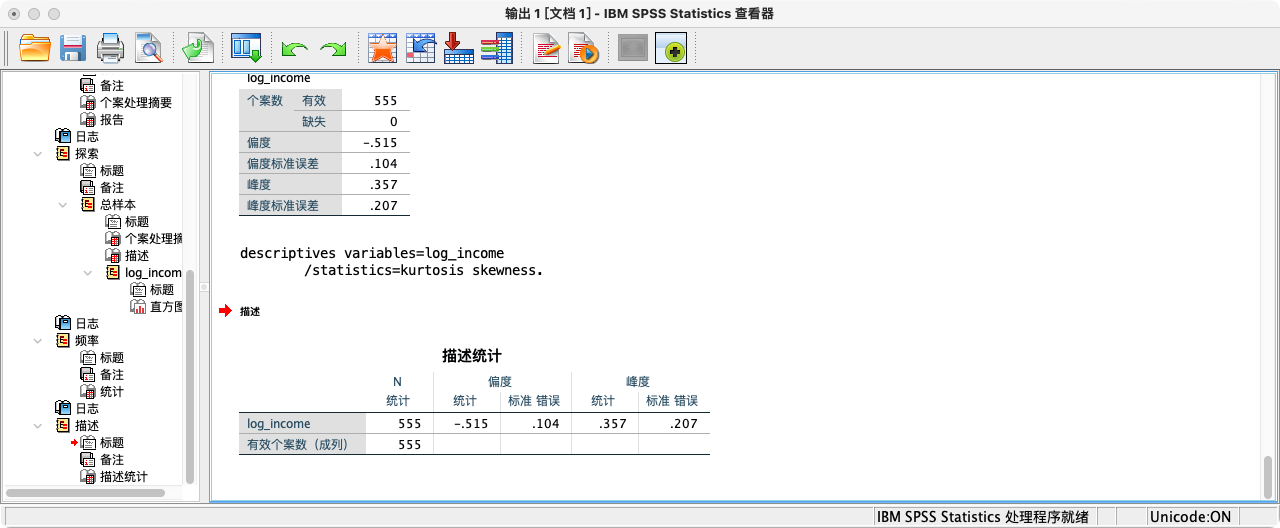
- 使用使用
DESCRIPTIVES功能- 点选操作:分析 → 描述统计 → 描述 → 选择变量 → 点击“选项” → 勾选“偏度”和“峰度” → 继续 → 确定。
- 语法操作:
DESCRIPTIVES VARIABLES=log_income
/STATISTICS=KURTOSIS SKEWNESS.
-
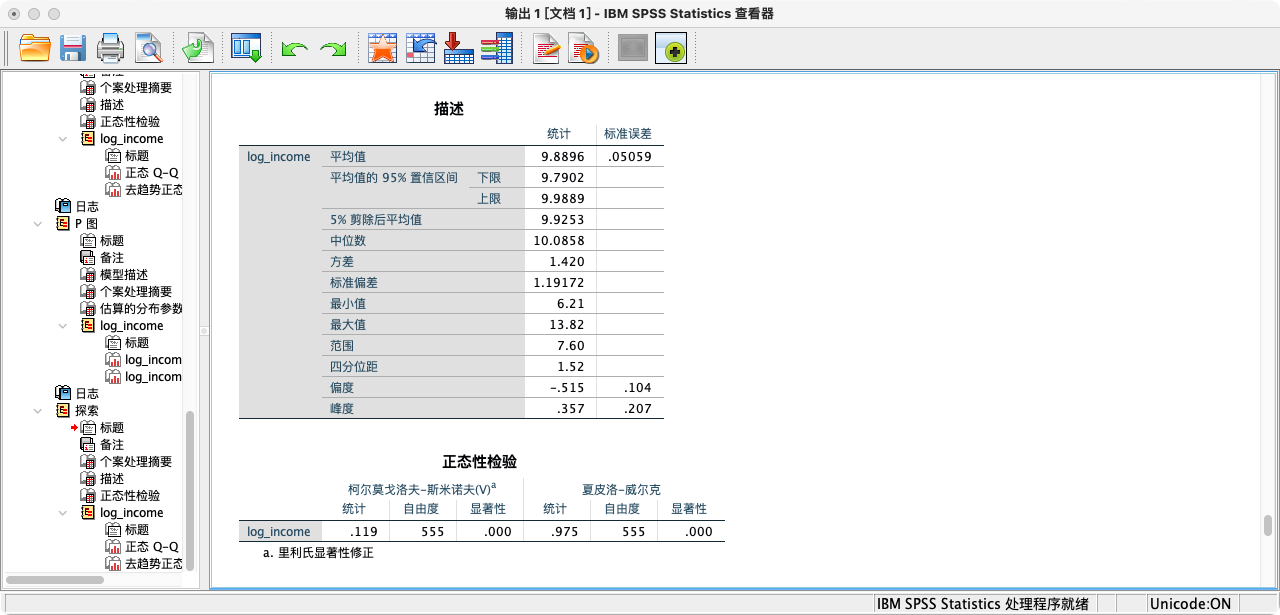
解读:从结果可知,对数收入的偏度(-0.515)和峰度(0.357)的绝对值都远小于1,说明其分布接近对称的钟形,近似满足正态性假设。
-
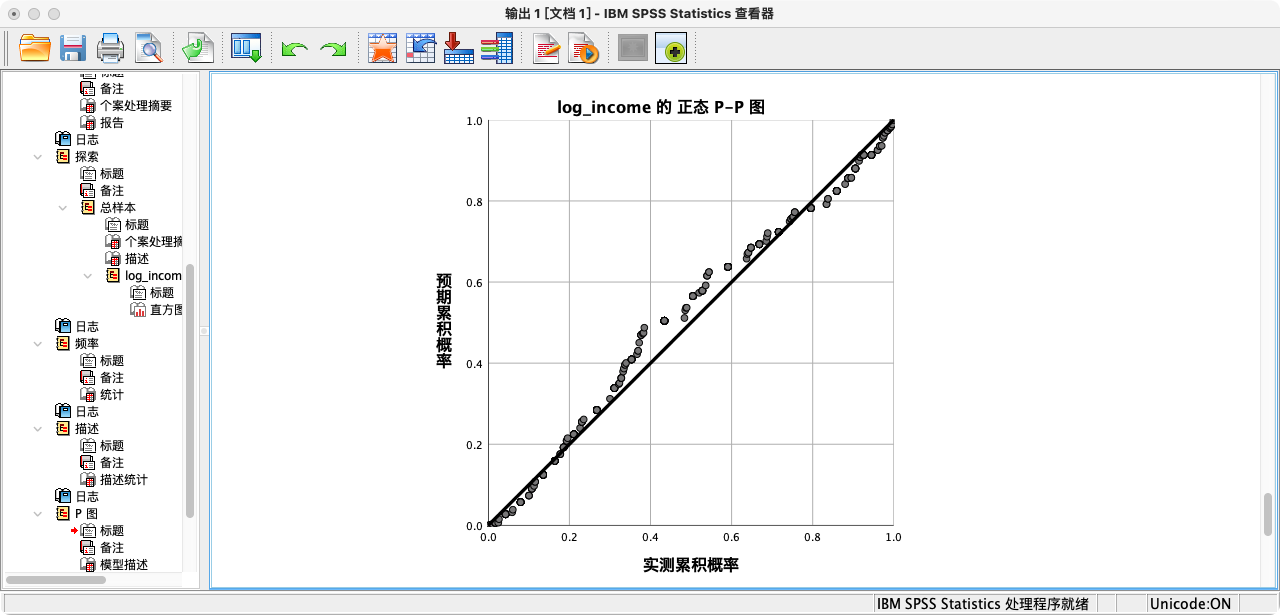
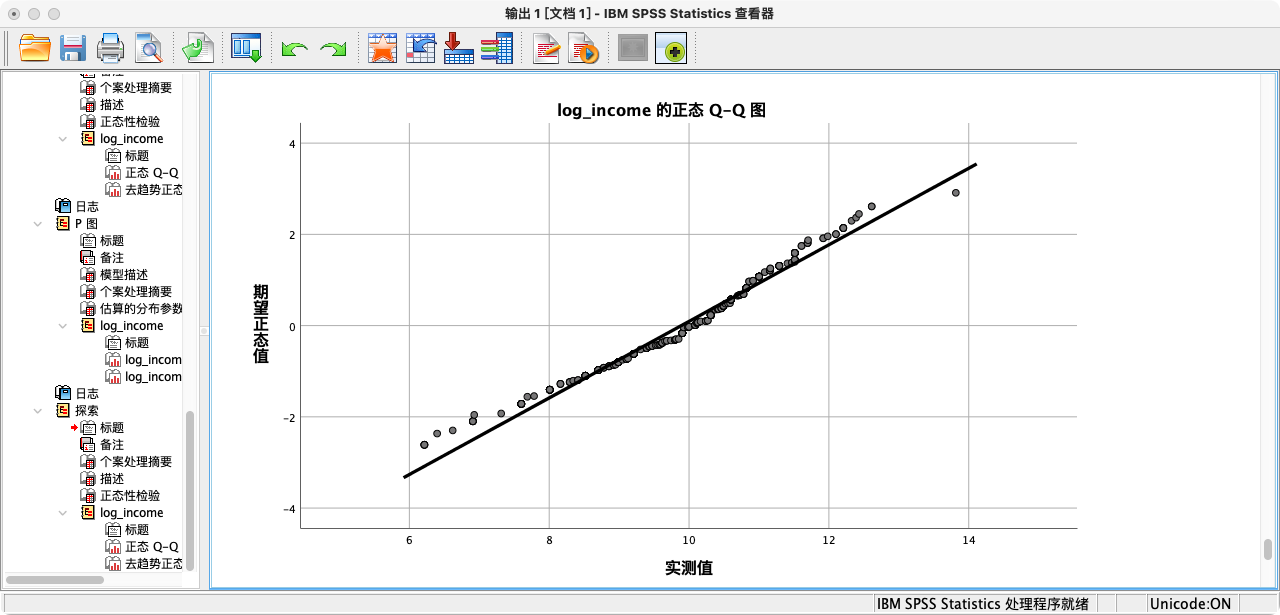
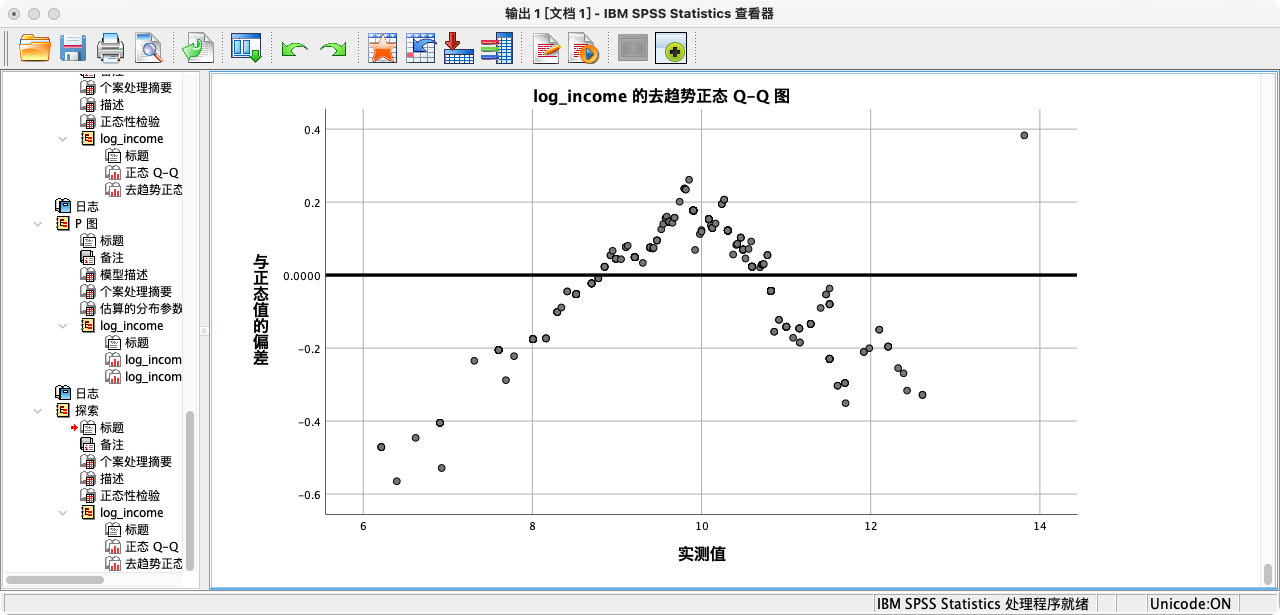
第二种方法:根据P-P图和Q-Q图来判断
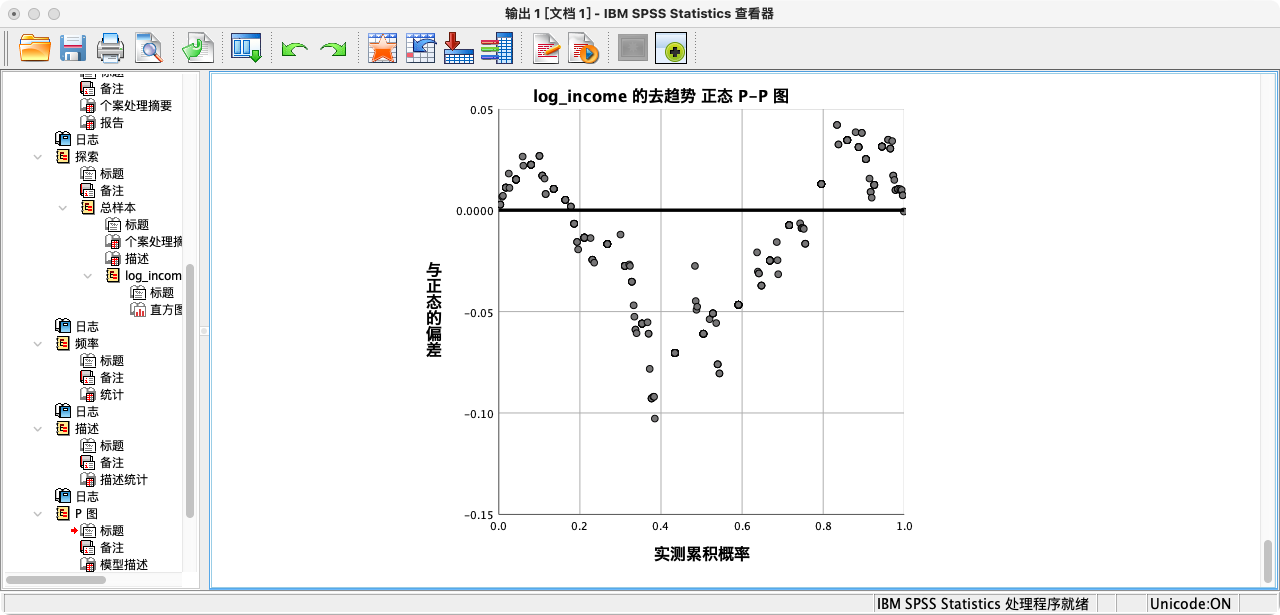
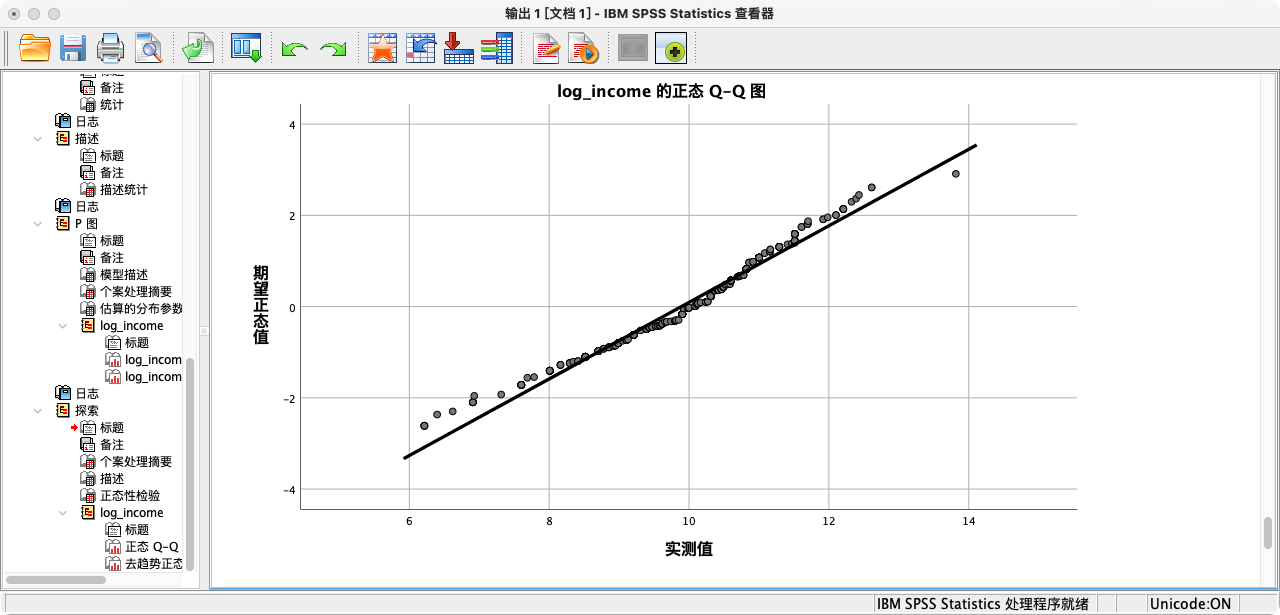
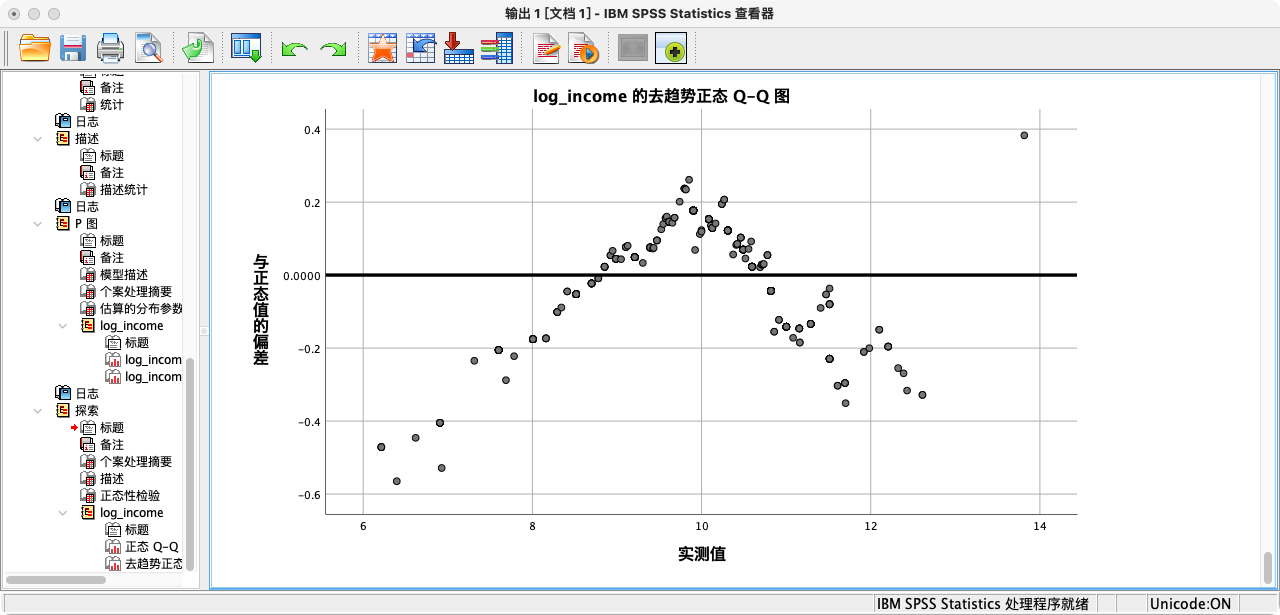
- 规则:通过比较观测数据与理论正态分布的期望值,来判断正态性。如果散点紧密地分布在对角线附近,则表明数据近似正态。Q-Q图在实践中应用更广。
-
P-P图
- 点选操作:分析 → 描述统计 → P-P图 → 选择变量 → 确定。
- 语法操作:
PPLOT
/TYPE=P-P
/VARIABLES = log_income.
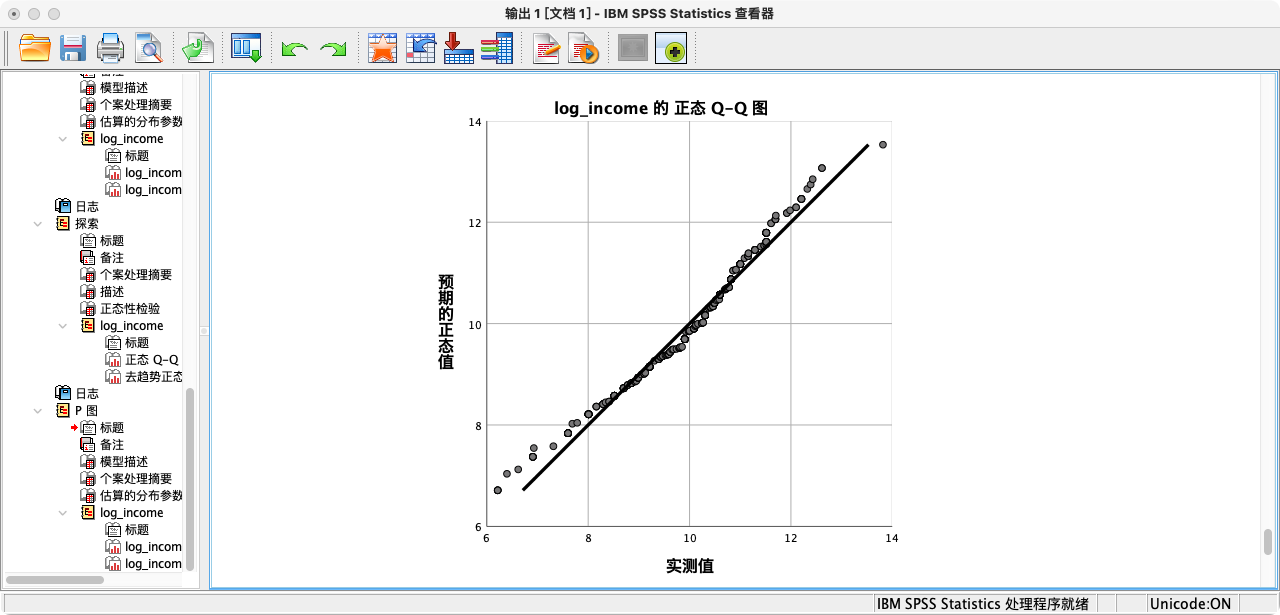
- Q-Q图
- 方式一:使用
EXAMINE功能- 点选操作:分析 → 描述统计 → 探索 → 将变量放入“因变量列表” → 点击“图” → 勾选“含检验的正态图” → 继续 → 确定。
- 语法操作:
EXAMINE VARIABLES=log_income
/PLOT NPPLOT
/NOTOTAL.
- 方式二:使用
PPLOT功能- 点选操作:分析 → 描述统计 → Q-Q图 → 选择变量 → 确定。
- 语法操作:
PPLOT
/TYPE=Q-Q
/VARIABLES = log_income.
-
解读:从P-P图和Q-Q图的结果来看,观测值散点都非常紧密地贴合在拟合线上,这为变量近似服从正态分布提供了强有力的图形证据。
-
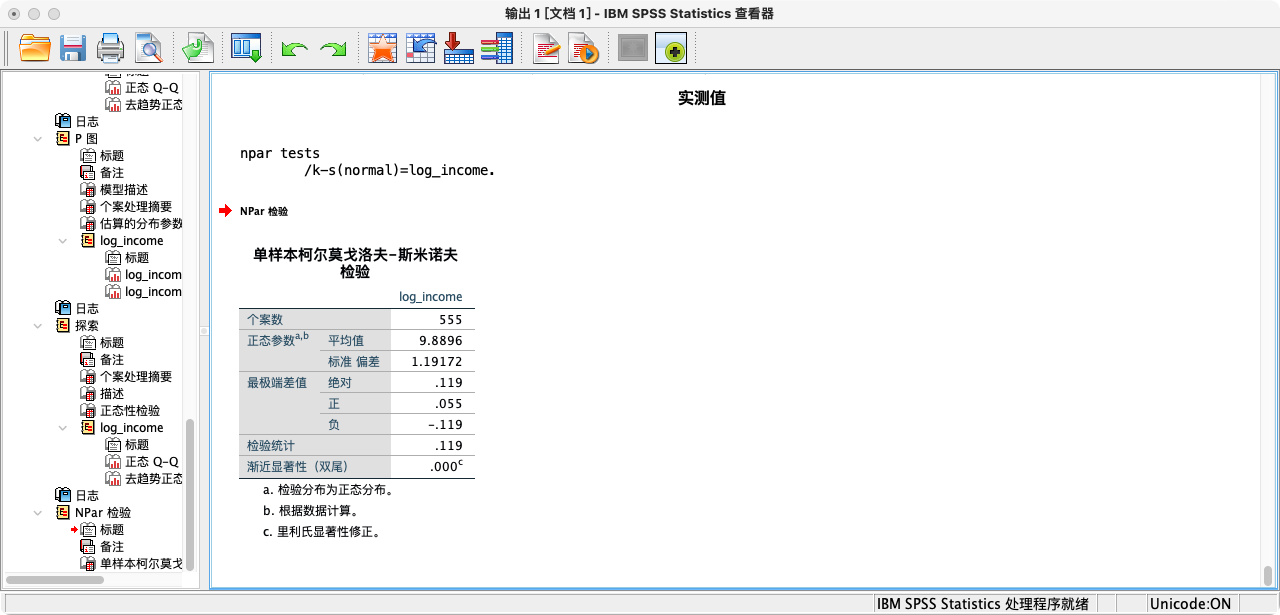
第三种方法:根据柯尔莫戈洛夫-斯米尔诺夫检验(K-S test)或夏皮罗-威尔克检验(Shapiro-Wilk test)
- 这是最严格的统计检验方法。
- 其虚无假设 H₀ 为:数据服从正态分布。
- 如果p值(Sig.)小于0.05,我们就拒绝H₀。
- 注意:在大样本情况下,这些检验非常敏感,即使数据轻微偏离正态,也可能导致显著的结果。因此,社会科学研究中通常更依赖于图形法和偏度/峰度指标进行综合判断。
- 这是最严格的统计检验方法。
-
K-S检验
-
方式一:使用
EXAMINE功能- 点选操作:与Q-Q图的“探索”功能相同。
- 语法操作:使用
EXAMINE(同时输出S-W检验)
EXAMINE VARIABLES=log_income
/PLOT NPPLOT
/NOTOTAL.
- 方式二:使用
NPAR TESTS功能- 点选操作:分析 → 非参数检验 → 旧对话框 → 单样本K-S → 将变量放入“检验变量列表” → 勾选“正态” → 确定。
- 语法操作:使用
NPAR TESTS
NPAR TESTS
/K-S(NORMAL)=log_income.
- 夏皮罗-威尔克检验
- 点选操作:与Q-Q图的“探索”功能相同。
- 语法操作:使用
EXAMINE
EXAMINE VARIABLES=log_income
/PLOT NPPLOT
/NOTOTAL.
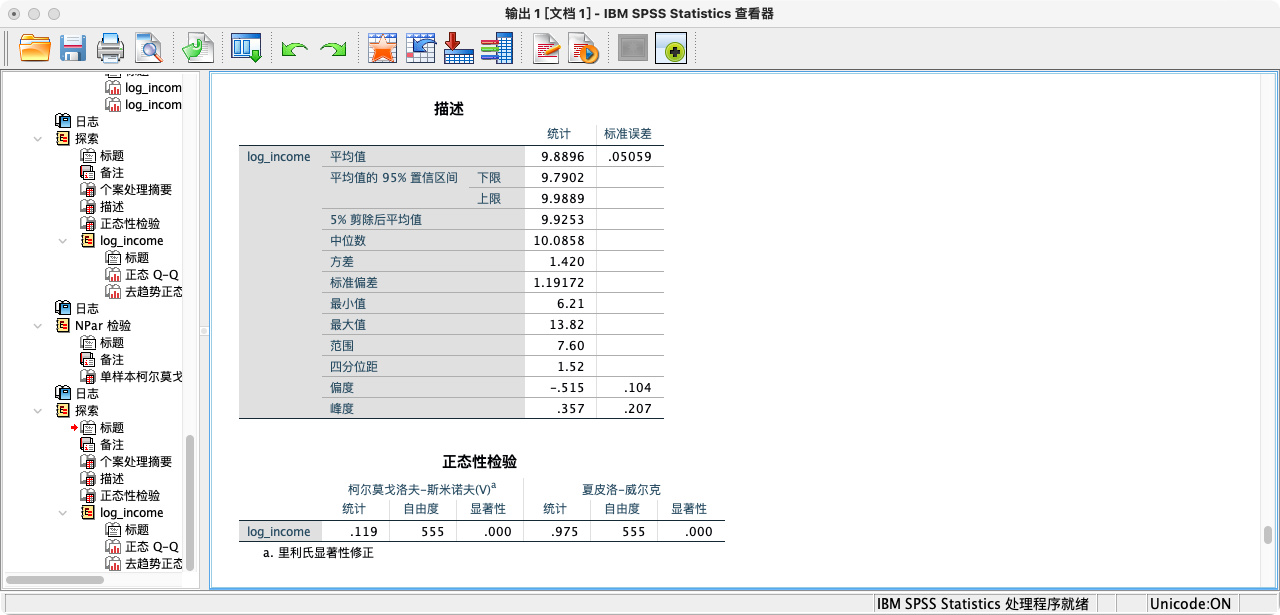
- 综合判断:两项统计检验的p值均小于0.05,拒绝了正态分布的虚无假设。然而,考虑到我们的样本量较大,检验结果可能过于敏感。结合前述偏度、峰度和Q-Q图的理想表现,我们仍然可以认为
log_income变量近似满足正态性假设,可以继续进行ANOVA分析。
随堂练习:采用以上三种方法,试检验教育年限(I2_1)及其对数形式是否具有正态性
- 第三步:检验前提假设 - 方差齐性 (Homogeneity of Variances)
- 我们使用莱文检验(levene test) 来判断各组的方差是否相等。
- 其虚无假设 H₀ 为:各组方差相等。
- 如果p值(Sig.)大于0.05,我们就不能拒绝H₀,即认为方差是齐的。
- 点选操作:分析 → 比较平均值 → 单因素ANOVA → 将
log_income放入“因变量列表”,season放入“因子” → 点击“选项” → 勾选“方差同质性检验” → 继续 → 确定。 - 语法操作:
- 我们使用莱文检验(levene test) 来判断各组的方差是否相等。
ONEWAY log_income BY season
/STATISTICS HOMOGENEITY.
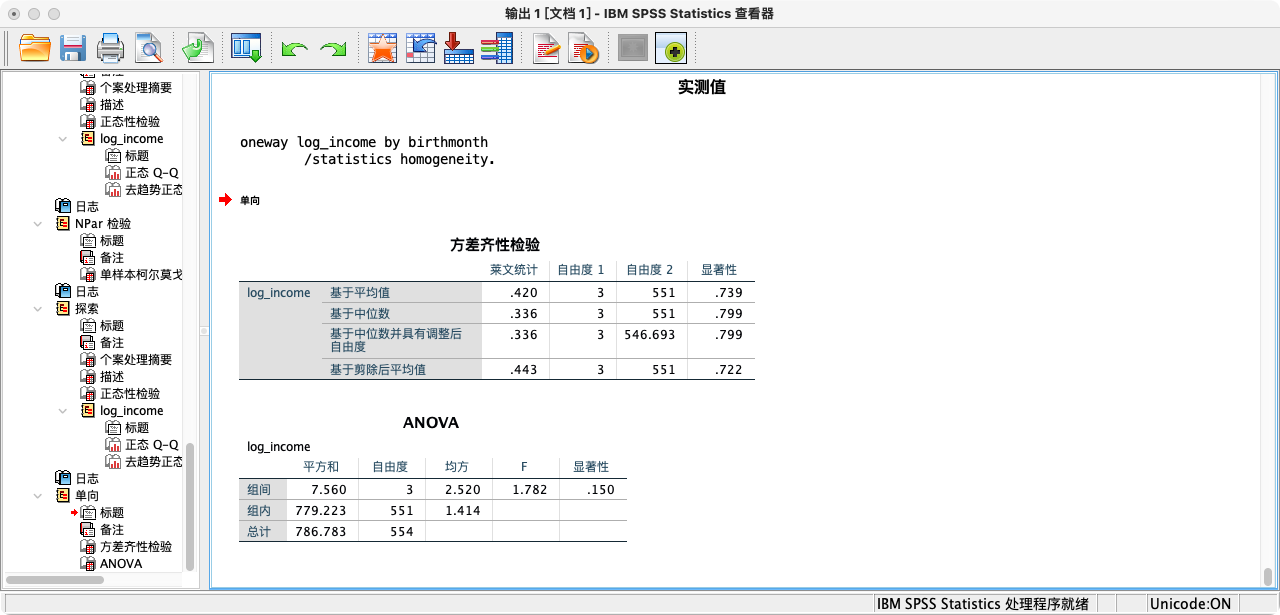
- 解读:Levene检验的p值为0.457,远大于0.05,表明我们没有理由认为各季节组的收入方差存在差异。方差齐性假设得到满足。
随堂练习:试检验从事不同产业(I3a_8)劳动者的教育年限(I2_1)及其对数形式是否具有方差齐性.
- 提示:对I3a_8而言,“1,2” 为第一产业,“3 thru 7”为第二产业,“8 thru 16”为第三产业.
- 第四步:进行方差分析 (ANOVA)
- 第一种方法:通过统计公式手动计算 (理解原理)
- ANOVA的核心思想是将总变异(SST)分解为组间变异(SSB)和组内变异(SSW)。
案例(1-2):试用方差分析,检验不同季节出生劳动者,其总收入是否存在差异
* 计算所有劳动者的总收入(取对数)均值.
AGGREGATE
/log_income_mean = mean(log_income).
* 计算所有劳动者的总收入(取对数)的总平方和(SST).
COMPUTE diff_sq = (log_income - log_income_mean)**2.
AGGREGATE
/SST = sum(diff_sq).
COMPUTE df_t = 555-1.
* 计算所有劳动者的总收入(取对数)的组间平方和(SSB).
* 计算不同出生组的平均收入.
MEANS log_income BY birthmonth
/CELLS = MEAN COUNT.
COMPUTE log_income_spring = 10.017473.
COMPUTE log_income_summer = 9.882176.
COMPUTE log_income_fall = 9.715442.
COMPUTE log_income_winter = 9.962090.
* 计算组间平方和.
COMPUTE SSB = 146*((log_income_spring-log_income_mean)**2) + 142*((log_income_summer-log_income_mean)**2) + 150*((log_income_fall-log_income_mean)**2) + 117*((log_income_winter-log_income_mean)**2).
COMPUTE df_b = 4-1.
* 计算所有劳动者的总收入(取对数)的组内平方和(SSW)或残差平方和(SSE).
IF (birthmonth = 1) log_income_spring_diffsq=(log_income-log_income_spring)**2.
IF (birthmonth = 2) log_income_summer_diffsq=(log_income-log_income_summer)**2.
IF (birthmonth = 3) log_income_fall_diffsq=(log_income-log_income_fall)**2.
IF (birthmonth = 4) log_income_winter_diffsq=(log_income-log_income_winter)**2.
AGGREGATE
/log_income_spring_sum = sum(log_income_spring_diffsq).
AGGREGATE
/log_income_summer_sum = sum(log_income_summer_diffsq).
AGGREGATE
/log_income_fall_sum = sum(log_income_fall_diffsq).
AGGREGATE
/log_income_winter_sum = sum(log_income_winter_diffsq).
COMPUTE SSW = log_income_spring_sum + log_income_summer_sum + log_income_fall_sum + log_income_winter_sum.
COMPUTE df_w = 555-4.
* 呈现方差分析结果.
FORMATS SST df_t SSB df_b SSW df_w (F20.16).
SUMMARIZE
/TABLES = SST df_t SSB df_b SSW df_w
/FORMAT = VALIDLIST LIMIT=1.
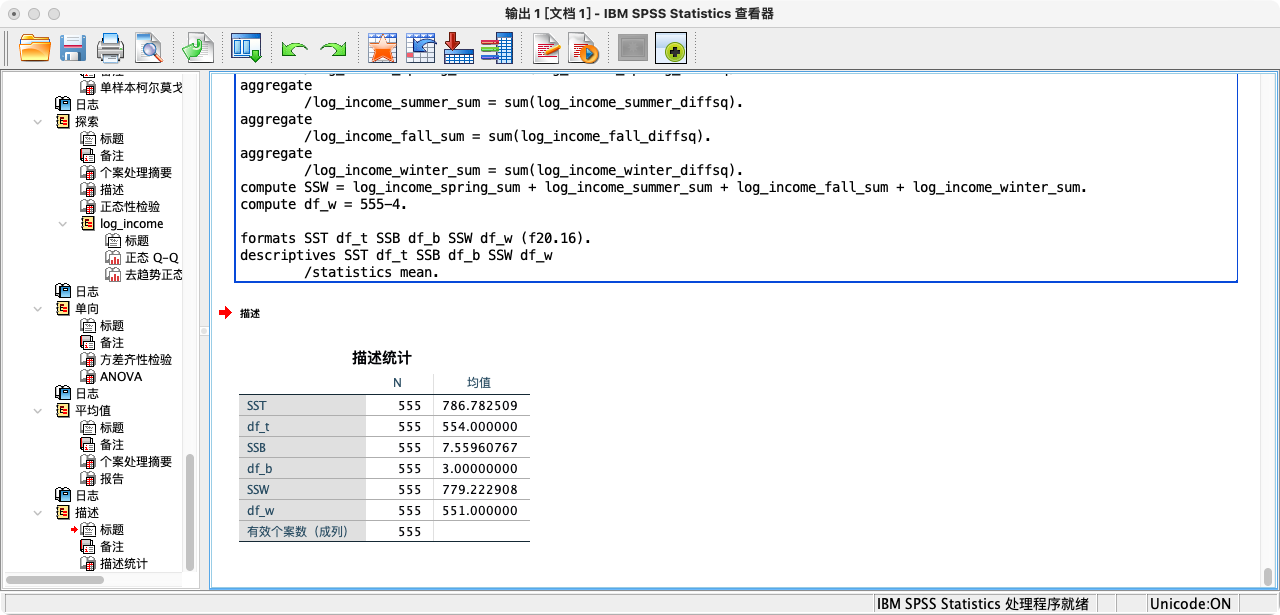
* 根据统计公式计算检验统计量.
COMPUTE F_value = (SSB/df_b)/(SSW/df_w).
FORMATS F_value (F20.16).
SUMMARIZE
/TABLES = F_value
/FORMAT = VALIDLIST LIMIT=1.
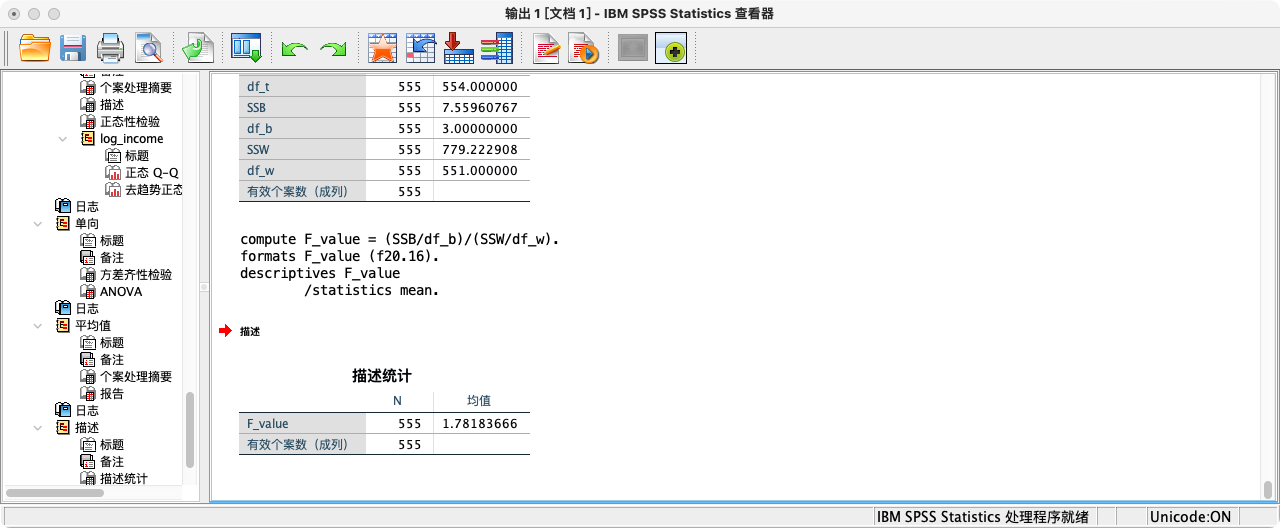
* 根据F检验结果,F值等于1.781837.
* 在F分布下,P值等于整个F分布的累积密度(面积=1)与样本均值处的累积密度(面积 = cdf.f(实际F值,自由度1,自由度2))之差.
COMPUTE p_value_f = (1 - cdf.f(1.781837,3,551)).
FORMATS p_value_f (F20.16).
SUMMARIZE
/TABLES = p_value_f
/FORMAT = VALIDLIST LIMIT=1.
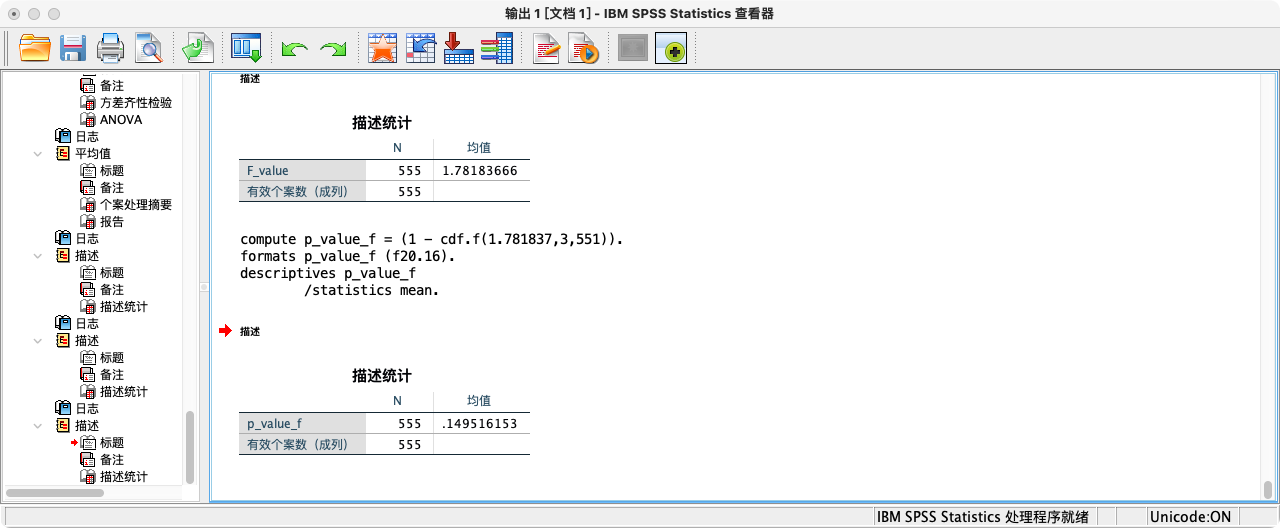
-
根据F检验结果,P值等于0.149516153378015且大于0.05的显著性水平,不能拒绝虚无假设,即认为不同季节出生的劳动者在2015年可能拥有相同的总收入,也可能拥有不同的总收入
-
第二种方法:采用“单因素ANOVA检验”功能
- 点选操作:分析 → 比较平均值 → 单因素ANOVA → 将
log_income放入“因变量列表”,season放入“因子” → (可选)点击“选项”勾选“描述”和“均值图” → 确定。 - 语法操作:
- 点选操作:分析 → 比较平均值 → 单因素ANOVA → 将
ONEWAY log_income BY season
/STATISTICS DESCRIPTIVES
/PLOT MEANS.
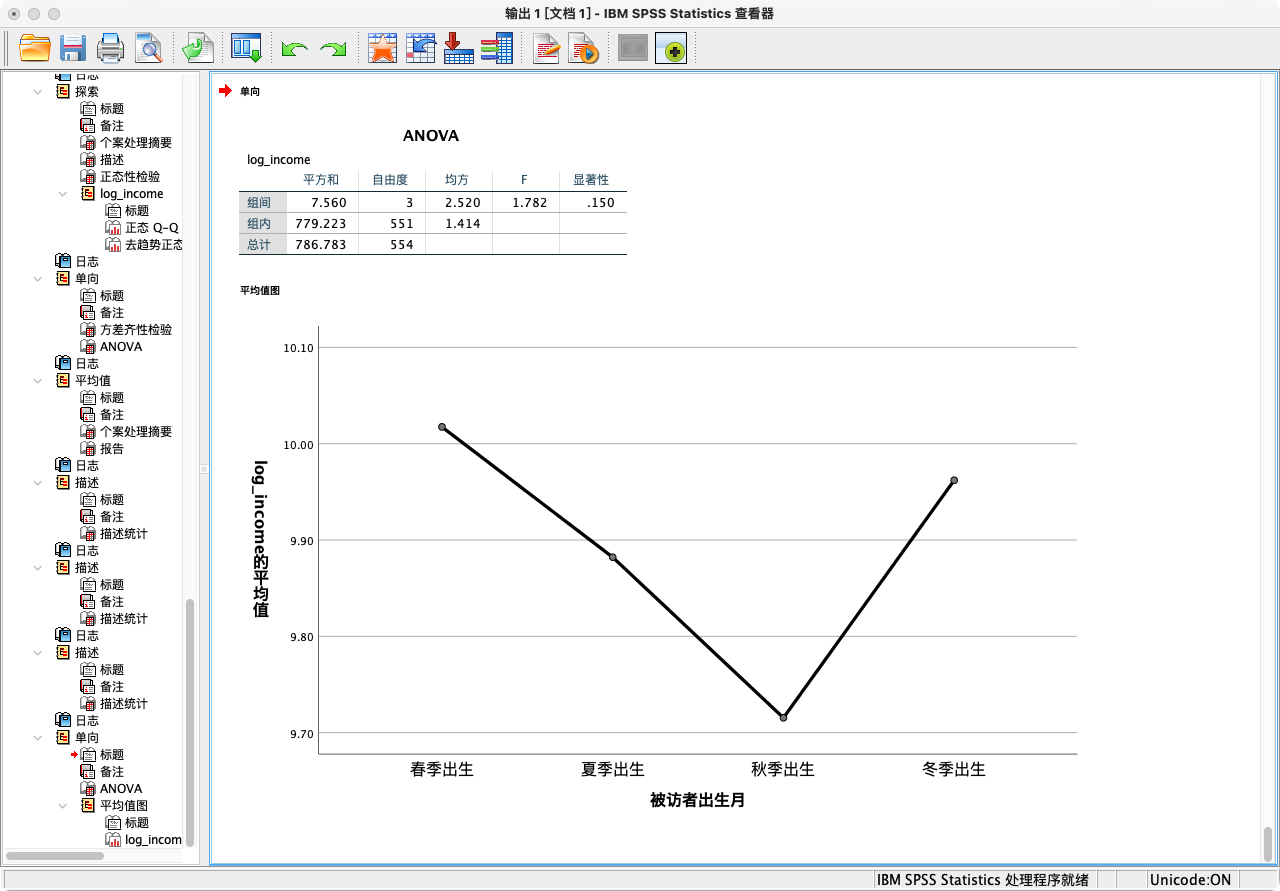
- 结果解读:
- 在“ANOVA”表中,我们主要关注F值和 “Sig.” (p值)。
- 这里的p值为0.149517,大于0.05。
- 结论:我们不能拒绝虚无假设H₀。这意味着,尽管我们在样本中观察到不同季节出生者的平均收入略有不同,但这种差异在统计上并不显著,很可能仅仅是抽样误差造成的。我们没有足够的证据表明出生季节对个人收入有显著影响。
随堂练习:以2015年社会地位得分(I7_10_1)为例,试检验不同地区(东中西)劳动者的平均社会地位得分是否相等.
- 提示:首先要将省份编码(PROV2016)转为地区编码
- 第一步:省份编码参考2014年中华人民共和国行政区划代码
- http://www.mca.gov.cn/article/sj/xzqh/1980/201507/20150715854923.shtml
- 11 = 北京 12 = 天津 13 = 河北 14 = 山西 15 = 内蒙古
- 21 = 辽宁 22 = 吉林 23 = 黑龙江 31 = 上海 32 = 江苏
- 33 = 浙江 34 = 安徽 35 = 福建 36 = 江西 37 = 山东
- 41 = 河南 42 = 湖北 43 = 湖南 44 = 广东 45 = 广西
- 50 = 重庆 51 = 四川 52 = 贵州 53 = 云南 61 = 陕西
- 62 = 甘肃 63 = 青海 64 = 宁夏 65 = 新疆
- 第二步:不同地区的划分参考国家统计局“东西中部和东北地区划分方法”
- https://www.stats.gov.cn/zt_18555/zthd/sjtjr/dejtjkfr/tjkp/202302/t20230216_1909741.htm
- 东北地区样本量过少,可以与西部地区样本合并
- 试判断变量的正态性和方差齐性,再进行方差分析
2.双因素方差分析 (Two-Way ANOVA)
- 当研究者想同时考察两个分类型自变量(因子)对一个连续型因变量的影响时,就需要使用双因素方差分析。它不仅能分别检验每个自变量的主效应 (Main Effect),还能检验两个自变量之间是否存在交互效应 (Interaction Effect)。
- 点选操作:分析 → 一般线性模型 → 单变量 → 选择“因变量”填入“因变量”框 → 选择“两个自变量”填入“固定因子”框 → 点击“模型” → 选择“构建项” → 选择“类型”为“主效应” → 将“因子与协变量”移入“模型” → 选择“平方和”为“III类” → 勾选“在模型中包括截距” → 继续 → 确定
- 语法操作:
UNIANOVA dependent_var BY factor1 factor2 ... [WITH covariate1 covariate2 ...]
/METHOD = SSTYPE(3)
/INTERCEPT = INCLUDE
/CRITERIA = ALPHA(<显著性水平>)
/DESIGN = factor1 factor2 factor1*factor2 ... .
语法说明
UNIANOVA dependent_var BY factor_list [WITH cov_list]- 这是命令的主体,用于定义模型中的变量角色。
dependent_var: 指定唯一的因变量,必须是连续变量。BY factor_list: 在BY之后列出所有分类自变量(也称为因子)。WITH cov_list: (可选) 在WITH之后列出所有连续自变量(也称为协变量),用于执行协方差分析(ANCOVA)。
/METHOD = SSTYPE(3)- 指定计算平方和 (Sum of Squares) 的类型。
SSTYPE(3): 即第三类平方和。这是默认且最推荐的选项,尤其是在数据不平衡(即各组样本量不同)或模型包含交互项时。它评估的是每个效应在控制了模型中所有其他效应之后独特的贡献。
/INTERCEPT = INCLUDE- 指定是否在模型中包含截距项。
INCLUDE是默认选项,通常我们都需要包含截距。
- 指定是否在模型中包含截距项。
/CRITERIA = ALPHA(<显著性水平>)- 设定检验的显著性水平α。默认值为
0.05。这个设置会影响置信区间的计算。
- 设定检验的显著性水平α。默认值为
/DESIGN = [效应列表]- 非常重要的子命令,用于明确指定你想要检验的模型结构。
- 只写变量名,如
factor1 factor2,表示只检验每个变量的主效应。 - 使用星号
*连接变量,如factor1*factor2,表示检验这两个变量的交互效应。 - 一个包含了两个主效应和一个交互效应的完整模型通常写为:
/DESIGN = factor1 factor2 factor1*factor2.。 - 如果省略
/DESIGN子命令,SPSS会默认构建一个包含所有因子、所有协变量以及所有因子间交互作用的完整模型。
辅助知识点:
UNIANOVA与ONEWAY的区别
ONEWAY: 只能处理一个分类自变量(单因素)。UNIANOVA: 可以同时处理一个或多个分类自变量(因子, Factor),以及一个或多个连续自变量(协变量, Covariate)。这使得它能够分析更复杂的模型,包括主效应和交互效应。
案例(2-1):检验出生季节与性别的双重影响
- 研究问题:出生季节和性别是否共同影响个人收入?
- 虚无假设 H₀-1: 不同季节出生者的总体平均收入相同。
- 虚无假设 H₀-2: 不同性别者的总体平均收入相同。
- 研究假设 H₁-1: 不同季节出生者的总体平均收入不完全相同。
- 研究假设 H₁-2: 不同性别者的总体平均收入不相同。
SELECT IF (gender > 0).
UNIANOVA log_income BY season gender
/METHOD = SSTYPE(3)
/INTERCEPT = INCLUDE
/CRITERIA = ALPHA(0.05)
/DESIGN = season gender /* /DESIGN 子命令明确指定只考虑主效应 */.
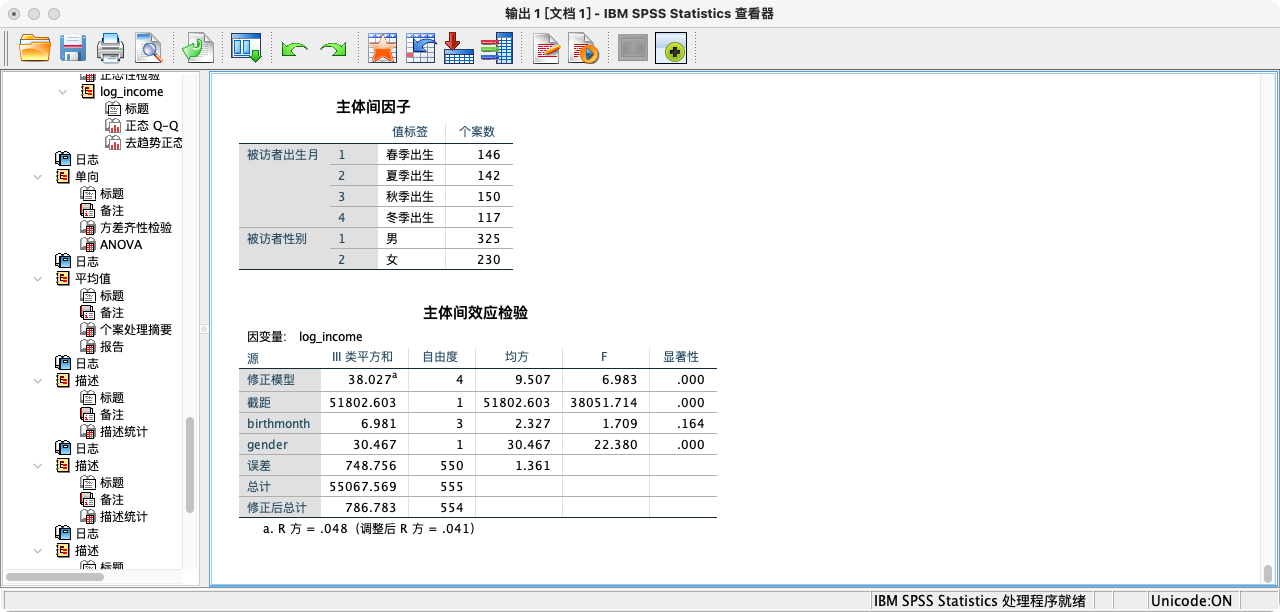
- 结果解读
- 在“Tests of Between-Subjects Effects”表中,我们分别看
season和gender两行。 - 出生季节 (season):F1值等于1.709387,对应p值为0.163985且大于0.05,主效应不显著。
- 性别 (gender):F2值等于22.379861,对应p值为0.000003且小于0.05,主效应非常显著。
- 结论:在同时控制了两个变量后,我们发现出生季节对收入依然没有显著影响,但性别的独立影响是显著的。
- 在“Tests of Between-Subjects Effects”表中,我们分别看
随堂练习:以2015年总收入为例,试检验不同行业的劳动者的平均收入是否相等
Disqus comments are disabled.