第十一讲 相关分析与简单线性回归
Publish date: Aug 1, 2021
Last updated: Sep 18, 2025
Last updated: Sep 18, 2025
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据 (CLDS)
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
- 数据准备:在本讲中,我们将探究“教育年限”与“个人总收入”之间的关系。
- 为满足后续分析的要求(特别是回归分析的正态性假设),我们将对收入变量进行对数转换。
- 我们将学历变量转换为连续的教育年限变量。
* 筛选有效个案.
SELECT IF (I3a_6 > 0 AND I2_1 > 0).
* 对收入进行自然对数转换以缓解偏度.
COMPUTE log_income = LN(I3a_6).
VARIABLE LABELS log_income "总收入 (自然对数)".
* 将学历转换为教育年限.
RECODE I2_1 (1=0) (2=6) (3=9) (4 THRU 7=12) (8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS) INTO edu_year.
VARIABLE LABELS edu_year "最高教育年限".
EXECUTE.
1. 相关关系的可视化:散点图
- 在进行任何数值计算之前,我们应该先通过散点图来直观地观察两个连续变量之间的关系。散点图可以告诉我们三件事:
- 关系形态:是线性关系还是曲线关系?
- 关系方向:是正相关(一个变量增大,另一个也随之增大)还是负相关?
- 关系强度:数据点是紧密围绕一条直线,还是松散地分布?
案例(1-1):描绘教育年限与总收入(对数)的散点图
- 点选操作:图形 → 图表构建器 → 从“图库”中选择“散点图/点图”并拖入画布 → 将“教育年限”拖入X轴 → 将“总收入(对数)”拖入Y轴 → 确定。
- 语法操作:
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES = edu_year log_income
/GRAPHSPEC SOURCE = INLINE
/FITLINE TOTAL = YES. /* 添加线性拟合线 */
BEGIN GPL
SOURCE: clds = userSource(id("clds"))
DATA: edu_year=col(source(clds), name("edu_year"))
DATA: log_income=col(source(clds), name("log_income"))
GUIDE: axis(dim(1), label("教育年限"))
GUIDE: axis(dim(2), label("总收入(对数)"))
GUIDE: text.title(label("2015年最高教育年限与总收入关系"))
ELEMENT: point(position(edu_year*log_income))
END GPL.
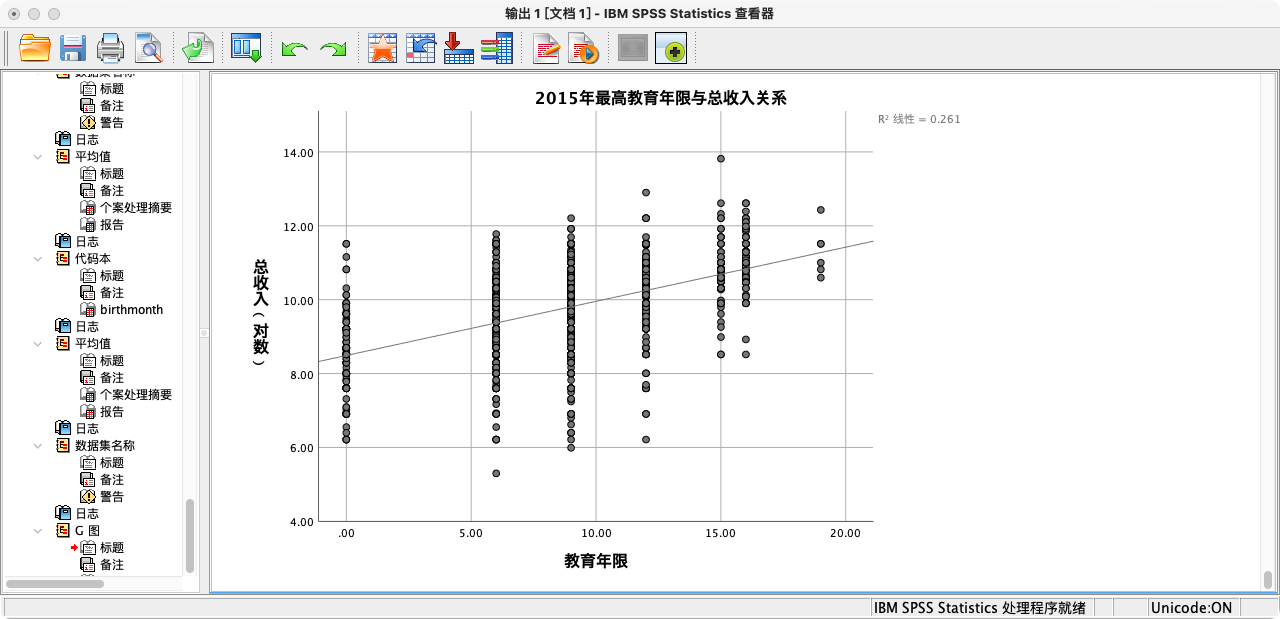
- 解读:从散点图中我们可以初步看到,数据点大致呈现出从左下到右上的趋势,表明教育年限与对数收入之间可能存在一个正向的线性关系。
2. 相关关系的量化(一):协方差 (Covariance)
- 协方差是衡量两个变量协同变化方向的指标。
- 正协方差:表示两个变量倾向于向相同方向变化。
- 负协方差:表示两个变量倾向于向相反方向变化。
辅助知识点:协方差的局限性
协方差有一个致命的弱点,它的数值大小会受到变量原始单位的影响。例如,用“元”计算的收入和用“万元”计算的收入,得到的协方差数值会相差一万倍,但这并不代表它们与教育的关系强度有任何不同。因此,协方差只告诉我们“方向”,却很难用来比较关系的“强度”。为了解决这个问题,我们引入了“相关系数”。
一共有四种方法可以计算协方差:可靠性分析STATISTICS模块、可靠性分析SUMMARY模块、双变量相关、线性回归
(1)可靠性分析STATISTICS模块
- 点选操作:分析 → 标度 → 可靠性分析 → 从变量列表选中“因变量”和“自变量”并移入“项” → 点击“统计” → 勾选“项之间”的“协方差” → 继续 → 确定
- 语法操作:
可靠性分析的整体语法结构
RELIABILITY
/VARIABLES var1 var2 var3 ...
/SCALE('SCALE_NAME') = var1 var2 ...
/STATISTICS [描述统计选项]
/SUMMARY [摘要统计选项].
语法说明
/VARIABLES varlist- 这是命令的主体,用于列出所有需要纳入本次分析的变量(或称为“条目”)。
/SCALE('SCALE_NAME') = varlist- 这是进行可靠性分析的核心子命令。
'SCALE_NAME': 为你定义的这个量表(或变量集合)指定一个名称,这个名称会显示在输出结果中。varlist: 再次列出构成这个量表的变量。通常,这里列出的变量与/VARIABLES中的一致。- 默认情况下,SPSS会计算这个量表的克朗巴赫Alpha系数 (Cronbach’s Alpha)。
/STATISTICS [选项]用于请求输出单个变量层面以及变量之间关系的描述统计。DESCRIPTIVES: 输出每个变量的均值、标准差和样本量。COV: 输出变量之间的协方差矩阵。CORR: 输出变量之间的相关系数矩阵。TUKEY: 提供了可加性的杜奇检验。HOTELLING: 霍特林T方检验。
/SUMMARY [选项]用于请求输出关于条目汇总信息的统计量。MEANS: 显示所有条目(变量)的均值、最小/最大值、极差、方差和样本量等汇总信息。VARIANCE: 显示条目方差的汇总信息。COVARIANCES: 显示条目协方差的汇总信息。CORRELATIONS: 显示条目相关系数的汇总信息。TOTAL: 显示量表中每一项与其余各项的总分之间的关系。
此处我们仅调用STATISTICS模块
RELIABILITY
/VARIABLES var1 var2 var3 ...
/STATISTICS COV.
(2)可靠性分析SUMMARY模块
- 点选操作:分析 → 标度 → 可靠性分析 → 从变量列表选中“因变量”和“自变量”并移入“项” → 点击“统计” → 勾选“摘要”的“协方差” → 继续 → 确定
- 语法操作:
此处我们仅调用
SUMMARY模块
RELIABILITY
/VARIABLES var1 var2 var3 ...
/SUMMARY COVARIANCES.
(3)双变量相关
- 点选操作:分析 → 相关 → 双变量 → 从变量列表选中“因变量”和“自变量”并移入“变量” → 点击“选项” → 勾选“统计”的“叉积偏差和协方差” → 继续 → 确定
- 语法操作:
CORRELATIONS
/VARIABLES var1 var2 var3 ...
/PRINT = [TWOTAIL | ONETAIL] [NOSIG]
/STATISTICS [DESCRIPTIVES] [XPROD] [ALL]
/MISSING = [PAIRWISE | LISTWISE].
语法说明
/VARIABLES varlist- 这是命令的主体,用于指定你想要计算其相互关系的一个或多个变量。SPSS会生成一个相关矩阵,展示所有指定变量两两之间的相关系数。
/PRINT- 用于控制显著性检验的类型。
TWOTAIL: 执行双尾显著性检验 (默认)。这是最常用的选项,用于检验关系是否存在,而不预设其方向。ONETAIL: 执行单尾显著性检验。仅在你已有非常强的理论预期,认为关系只可能朝某一个特定方向(正或负)时才使用。NOSIG: 在相关矩阵中不显示显著性水平(p值),只显示相关系数和样本量,使表格更简洁。
/STATISTICS- 用于请求输出额外的描述性统计量。
DESCRIPTIVES: 输出一个包含每个变量的均值、标准差和个案数的描述统计表。XPROD: 输出一个包含每个变量对之间的叉积离差和协方差的表格。ALL: 请求输出以上两种统计量。
/MISSING- 指定处理缺失值的方式,这是一个非常重要的选项。
PAIRWISE: 成对删除 (默认)。对于每一对变量的相关系数,只要一个个案在这两个变量上都有值,就会被纳入计算。这意味着不同相关系数的计算可能基于不同数量的个案。LISTWISE: 列表删除。只有在/VARIABLES中指定的所有变量上都没有缺失值的个案,才会被纳入整个分析。这确保了所有相关系数都基于完全相同的样本,但可能会损失较多的个案。
辅助知识点:
PAIRWISEvs.LISTWISE如何选择?
- 当你只是想探索性地了解变量两两之间的关系,且缺失值是随机分布的,
PAIRWISE可以最大化地利用你的数据。- 当你计划将这个相关矩阵用于后续的多元分析(如回归分析、因子分析)时,强烈建议使用
LISTWISE。因为这些多元分析方法本身就是基于列表删除的,使用LISTWISE可以确保你的相关性分析和后续模型分析所用的样本是完全一致的。
(4)线性回归的DESCRIPTIVES模块(只能通过语法调用)
- 语法操作:
REGRESSION
/MISSING LISTWISE
/STATISTICS [统计量选项]
/CRITERIA = PIN(0.05) POUT(0.10)
/NOORIGIN
/DEPENDENT dependent_var
/METHOD = [进入方式] varlist
/DESCRIPTIVES [描述统计选项].
语法说明
/DEPENDENT dependent_var- 必需项。用于指定模型中的因变量 (Dependent Variable)。因变量必须是连续的。
/METHOD = [进入方式] varlist- 必需项。这是
REGRESSION命令的引擎,用于指定自变量 (Independent Variables) 以及它们如何进入模型。 varlist: 在进入方式关键字后,列出你希望纳入模型的一个或多个自变量。- 常用进入方式:
ENTER: 强行进入/输入法 (默认)。将varlist中指定的所有自变量一次性全部放入模型,不论其是否显著。这是理论驱动研究中最常用的方法。STEPWISE: 逐步法。通过一系列的向前引入(Forward)和向后剔除(Backward)检验,自动筛选并构建出一个“最优”的变量组合模型。FORWARD: 向前法。从空模型开始,每次引入一个对模型改善最显著的变量,直到没有变量能显著改善模型为止。BACKWARD: 向后法。从包含所有变量的全模型开始,每次剔除一个对模型贡献最小的变量,直到剩下的变量都对模型有显著贡献为止。REMOVE: 移去法。与ENTER配合使用,用于在模型块中移除指定的变量。
- 注意:可以设置多个
/METHOD子命令块,以构建层次回归模型 (Hierarchical Regression)。
- 必需项。这是
/STATISTICS [统计量选项]- 用于请求输出关于回归模型本身的统计量。
DEFAULTS: 默认选项,输出R,ANOVA,COEFF。COEFF: 输出系数表 (Coefficients),包含B, Beta, 标准误, t值, p值。这是最核心的输出。R: 输出模型摘要 (Model Summary),包含R, R方, 调整后R方, D-W统计量等。ANOVA: 输出回归模型的方差分析表,用于检验模型的整体显著性。CI(level): 在系数表中增加回归系数的置信区间。level是置信水平,默认为95。例如:CI(99)。ALL: 请求所有可用的统计量。
/DESCRIPTIVES [选项]- 用于请求输出模型中所有变量的描述性统计量。
DEFAULTS: 默认选项,输出MEAN,STDDEV,CORR。MEAN: 均值。STDDEV: 标准差。VARIANCE: 方差。CORR: 相关系数矩阵。COV: 协方差矩阵。XPROD: 叉积离差和。SIG: 相关系数矩阵的p值。N: 有效个案数。ALL: 请求所有可用的描述统计量。
- 其他常用子命令
/MISSING LISTWISE: 这是默认的缺失值处理方式,确保所有分析都基于一个完整的样本。/NOORIGIN: 默认选项,表示模型中包含一个截距项(常数项)。/SAVE: 用于将模型的预测值、残差等保存为数据集中的新变量,对于模型诊断非常重要。/SCATTERPLOT: 快速绘制残差散点图。
此处我们仅调用DESCRIPTIVES模块
REGRESSION
/STATISTICS [统计量选项]
/DEPENDENT dependent_var
/METHOD = [进入方式] varlist
/DESCRIPTIVES COV.
案例(2-1):求教育年限与对数收入的协方差
- 第一种方法:根据统计公式手动计算
* 公式: Cov(X,Y) = Σ[(xᵢ - x̄)(yᵢ - ȳ)] / (n-1).
* 第一步:计算2015年总收入(对数)的均值.
AGGREGATE
/log_income_mean = MEAN(log_income)
/edu_year_mean = MEAN(edu_year).
* 第二步:计算2015年总收入(对数)实际值与均值离差.
COMPUTE log_income_diff = log_income - log_income_mean.
* 第三步:计算2015年最高教育年限的均值.
COMPUTE edu_year_diff = edu_year - edu_year_mean.
* 第四步:计算2015年最高教育年限实际值与均值的离差.
COMPUTE income_edu = log_income_diff*edu_year_diff.
* 第五步:创建新变量,使之等于总收入(对数)与最高教育年限的离差乘积.
AGGREGATE
/income_edu_sum = SUM(income_edu)
/N=N.
* 第六步:对总收入(对数)与最高教育年限的离差乘积求总和.
COMPUTE income_edu_cov = income_edu_sum / (N - 1).
* 第七步:用离差乘积之和除以自由度,得到两者的协方差.
FORMATS income_edu_cov (F20.16).
SUMMARIZE
/TABLES = income_edu_cov
/FORMAT = VALIDLIST LIMIT=1.
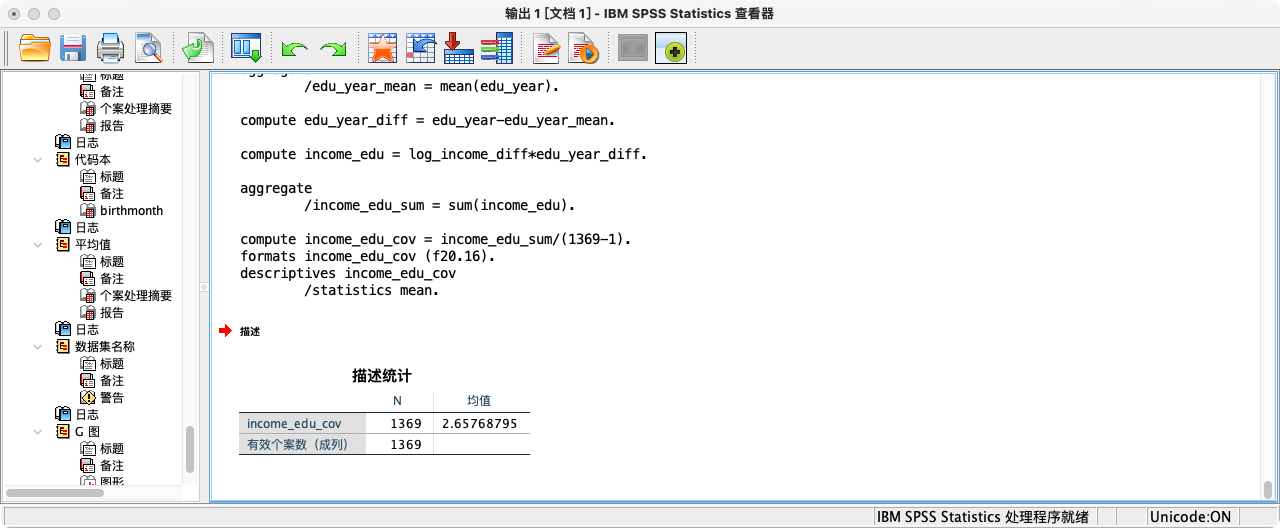
- 第二种方法:采用“可靠性分析”功能的
STATISTICS模块
RELIABILITY
/VARIABLES log_income edu_year
/STATISTICS COV.
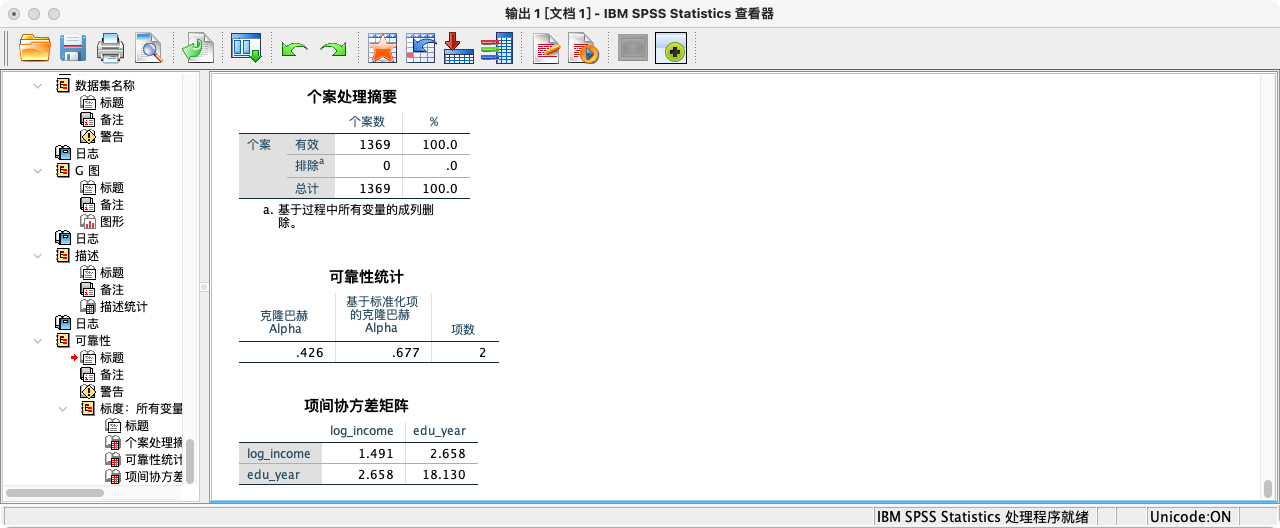
- 第三种方法:采用“可靠性分析”功能的
SUMMARY模块
RELIABILITY
/VARIABLES log_income edu_year
/SUMMARY COV.
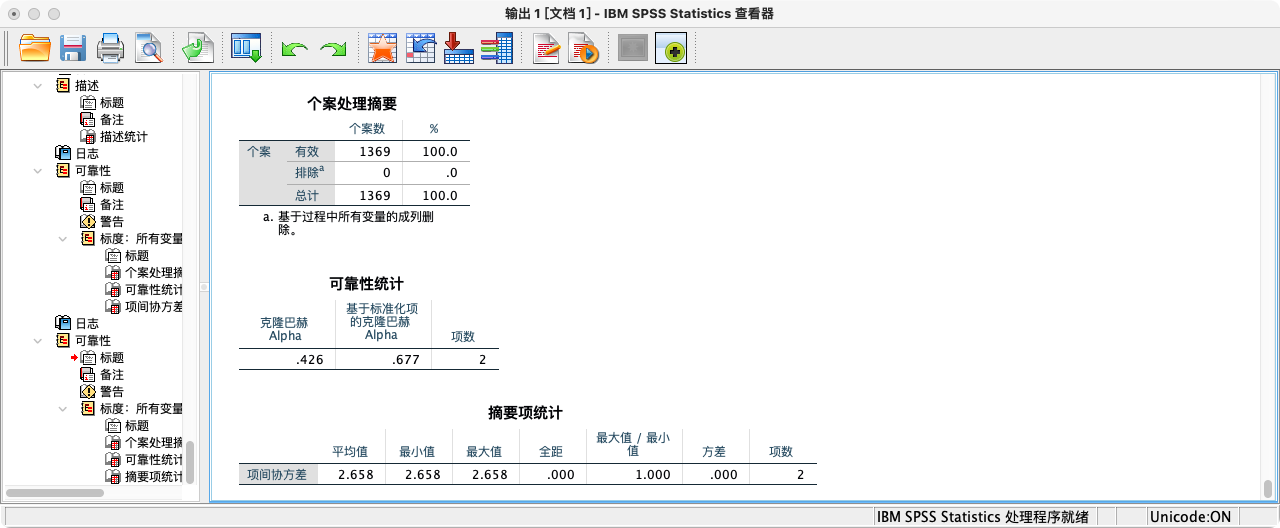
- 第四种方法:采用“双变量相关”功能的
DESCRIPTIVES模块
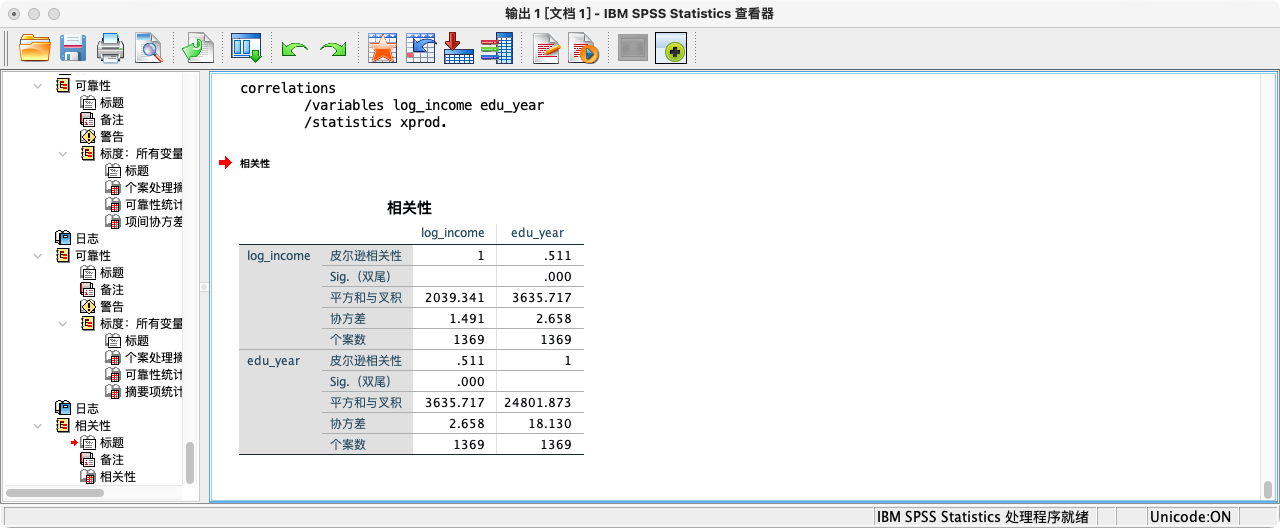
CORRELATIONS
/VARIABLES log_income edu_year
/STATISTICS XPROD.
- 第五种方法:采用“线性回归”功能的
DESCRIPTIVES模块
REGRESSION
/DESCRIPTIVES COV
/DEPENDENT log_income
/METHOD = ENTER edu_year.
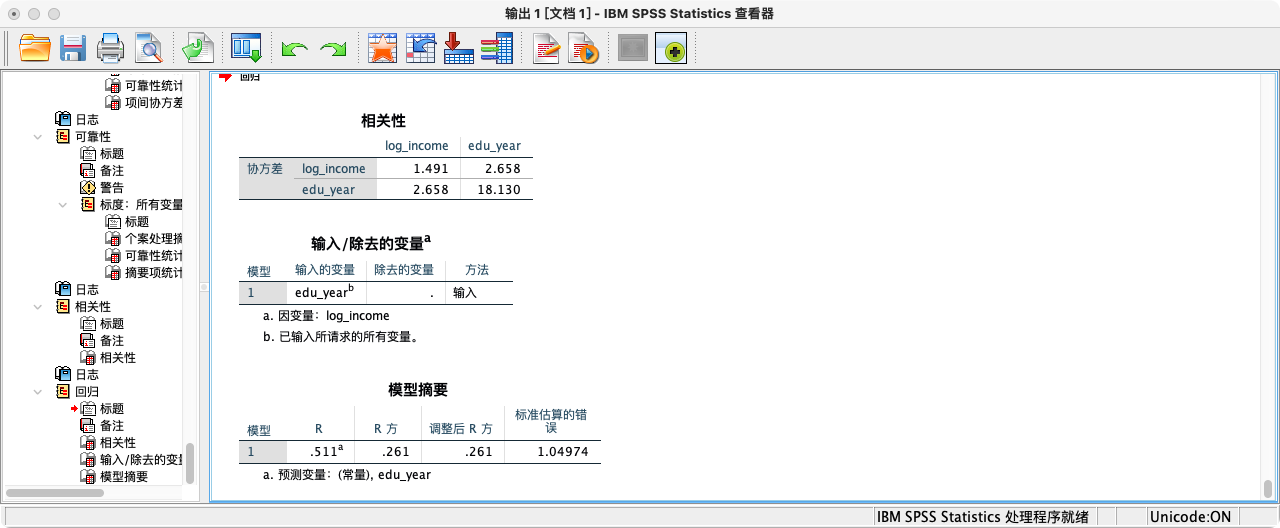
- 由以上多种方法可知,2015年总收入(对数)与最高教育年限的协方差约为 2.658,是一个正值,印证了我们在散点图中观察到的正向关系。
3. 关系的量化(二):相关系数 (Correlation Coefficient)
- 皮尔逊相关系数 (r) 是对协方差进行标准化后的结果,它解决了协方差受单位影响的问题。
r的取值范围在 -1 到 +1 之间。r = +1: 完全正相关。r = -1: 完全负相关。r = 0: 没有线性关系。|r|的绝对值大小表示了线性关系的强度。
同样地,也有四种方法可以计算相关系数:可靠性分析STATISTICS模块、可靠性分析SUMMARY模块、双变量相关、线性回归
- 点选操作
- 可靠性分析的
STATISTICS模块:分析 → 标度 → 可靠性分析 → 从变量列表选中“因变量”和“自变量”并移入“项” → 点击“统计” → 勾选“项之间”的“相关性” → 继续 → 确定 - 可靠性分析的
SUMMARY模块:分析 → 标度 → 可靠性分析 → 从变量列表选中“因变量”和“自变量”并移入“项” → 点击“统计” → 勾选“摘要”的“相关性” → 继续 → 确定 - 双变量相关:分析 → 相关 → 双变量 → 从变量列表选中“因变量”和“自变量”并移入“变量” → 勾选“相关系数”的“皮尔逊” → 确定
- 线性回归:分析 → 回归 → 线性 → 从变量列表选中“因变量”和“自变量”并移入对应框 → 点击“统计” → 勾选“模型拟合” → 继续 → 确定
- 可靠性分析的
案例(3-1):计算教育年限与对数收入的相关系数
- 第一种方法:根据统计公式手动计算
* 第一步:计算2015年总收入(对数)的离差平方.
COMPUTE log_income_diff_sq = log_income_diff**2.
* 第二步:计算2015年总收入(对数)的离差平方和.
AGGREGATE
/log_income_diff_sum = SUM(log_income_diff_sq).
* 第三步:计算2015年总收入(对数)的总体方差估计值.
COMPUTE log_income_var = log_income_diff_sum/(1369-1).
* 第四步:计算2015年总收入(对数)的总体标准差估计值.
COMPUTE log_income_sd = sqrt(log_income_var).
* 第五步:计算2015年最高教育年限的离差平方.
COMPUTE edu_year_diff_sq = edu_year_diff**2.
* 第六步:计算2015年最高教育年限的离差平方和.
AGGREGATE
/edu_year_diff_sum = SUM(edu_year_diff_sq).
* 第七步:计算2015年最高教育年限的总体方差估计值.
COMPUTE edu_year_var = edu_year_diff_sum/(1369-1).
* 第八步:计算2015年最高教育年限的总体标准差估计值.
COMPUTE edu_year_sd = SQRT(edu_year_var).
* 第九步:计算2015年总收入(对数)与最高教育年限的标准差乘积,代表两者最大变异关系.
COMPUTE income_edu_sd = log_income_sd*edu_year_sd.
* 第十步:用两者协方差占最大变异关系的比例,计算皮尔逊积矩相关系数.
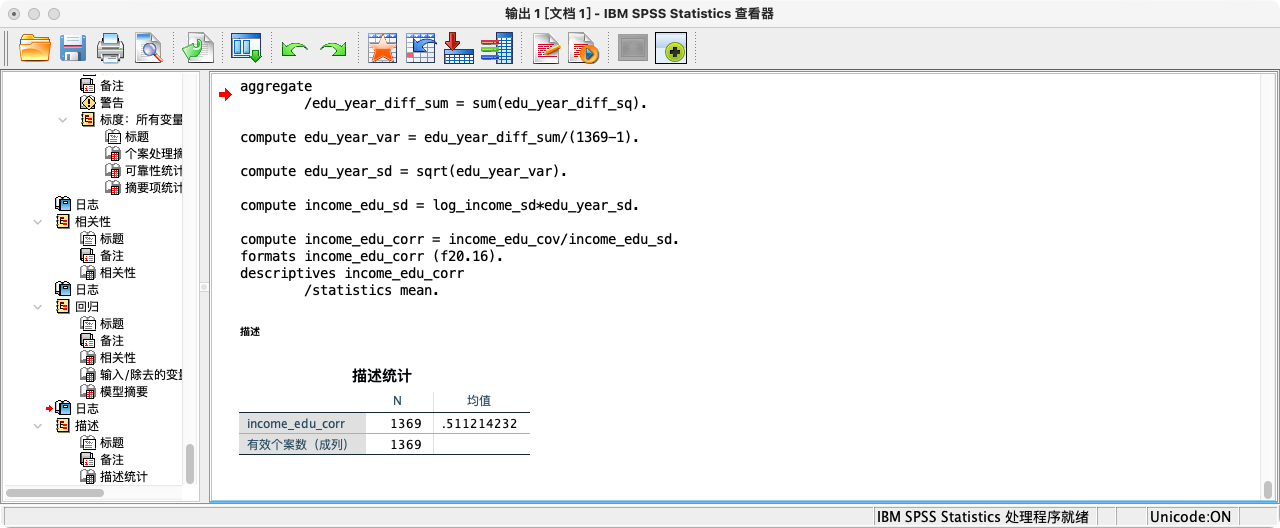
COMPUTE income_edu_corr = income_edu_cov/income_edu_sd.
FORMATS income_edu_corr (f20.16).
SUMMARIZE
/TABLES = income_edu_corr
/FORMAT = VALIDLIST LIMIT=1.
- 第二种方法:采用“可靠性分析”功能中的
STATISTICS模块
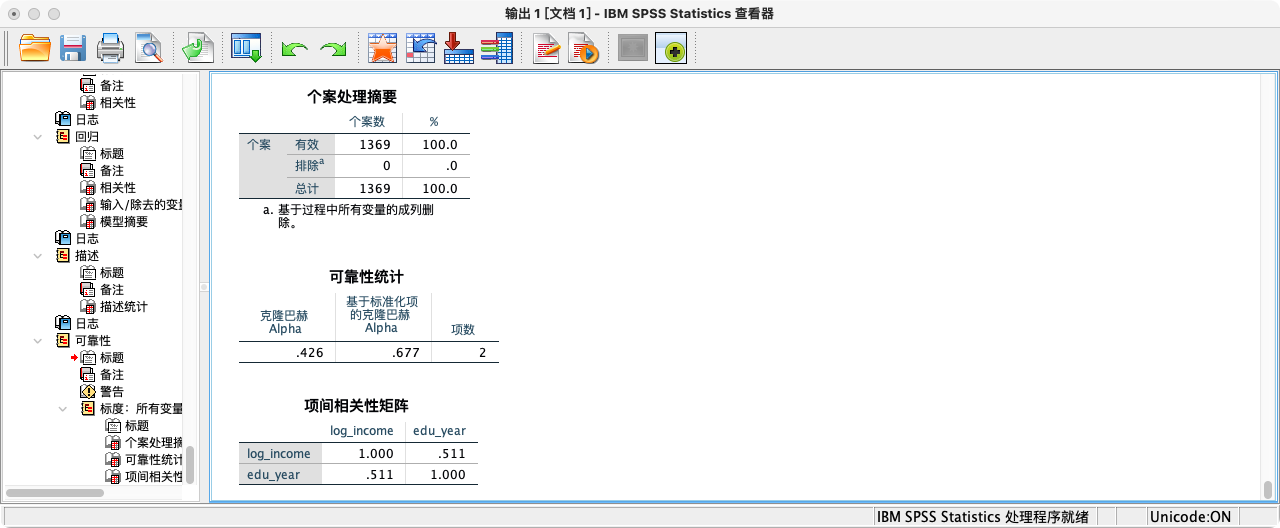
RELIABILITY
/VARIABLES log_income edu_year
/STATISTICS CORR.
- 第三种方法:采用“可靠性分析”功能中的
SUMMARY模块
RELIABILITY
/VARIABLES log_income edu_year
/SUMMARY CORR.
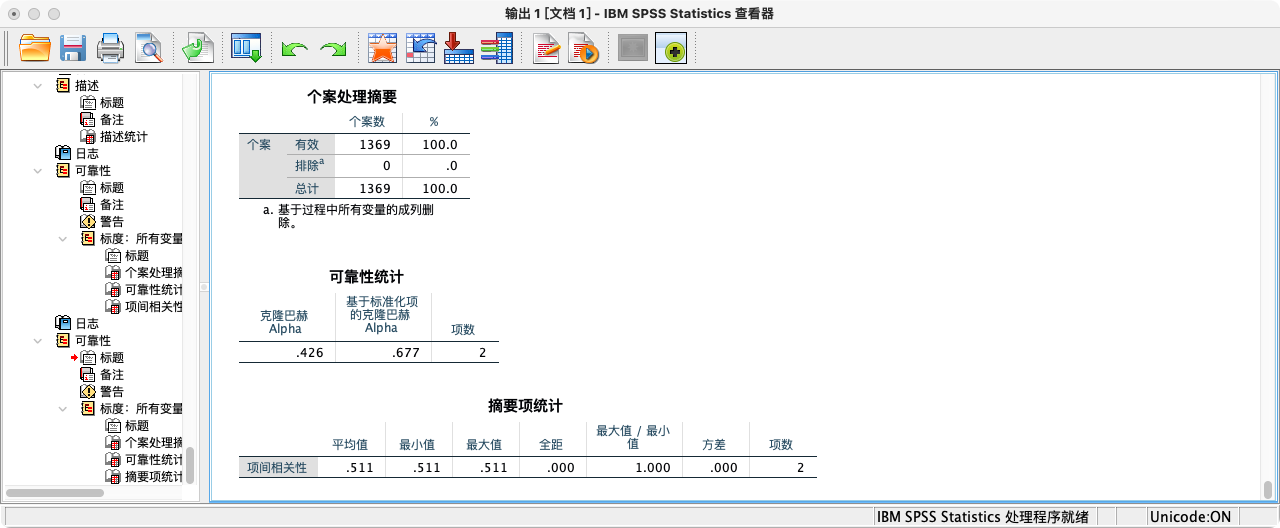
- 第四种方法:采用“双变量相关”功能 (推荐)
CORRELATIONS
/VARIABLES log_income edu_year.
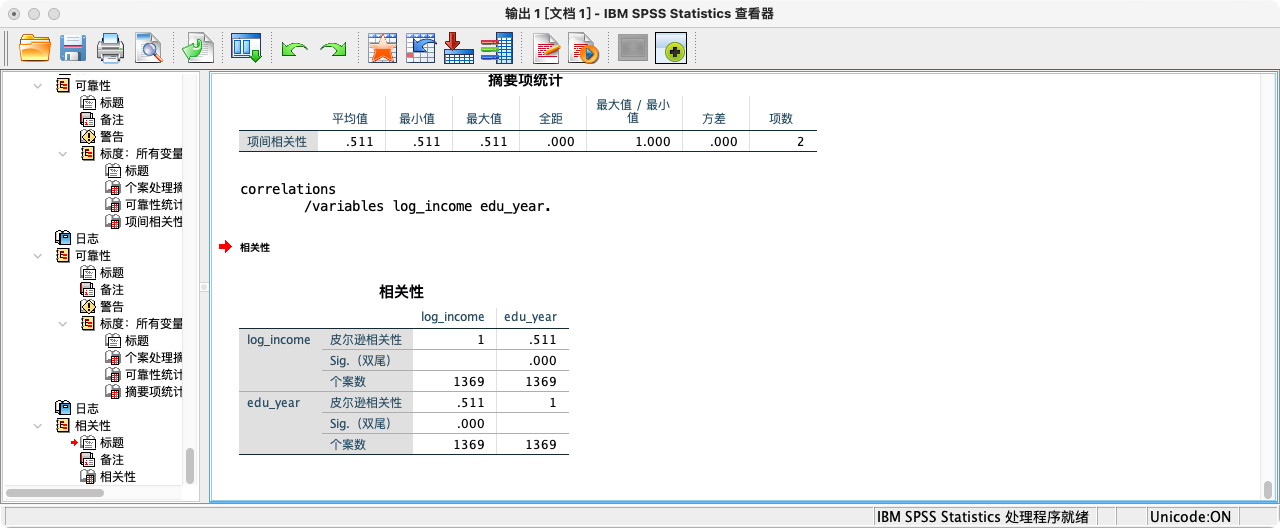
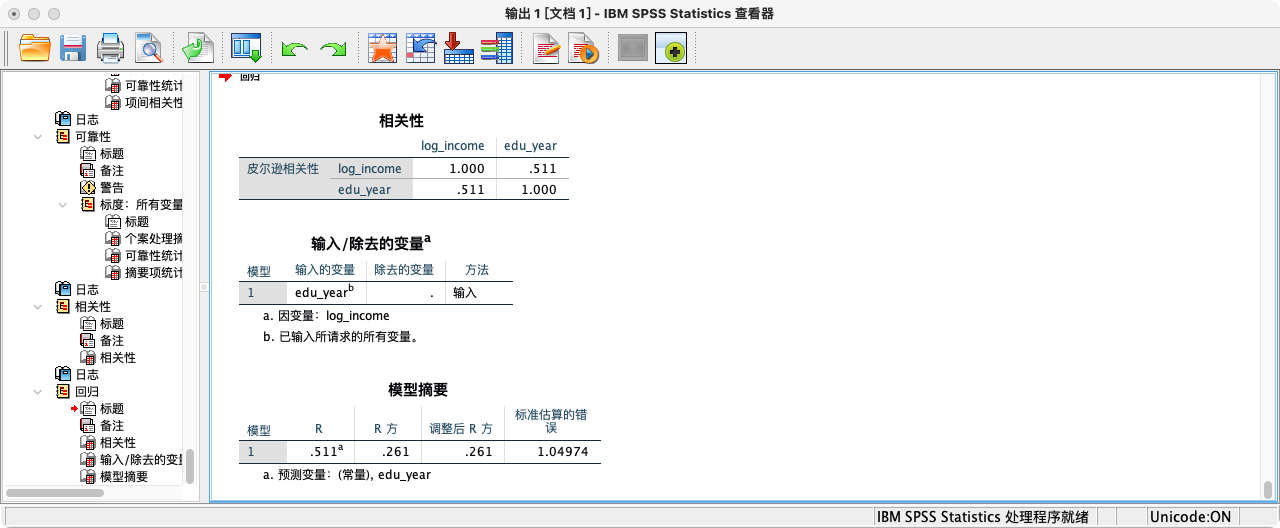
- 第五种方法:采用“线性回归”功能的
DESCRIPTIVES模块
REGRESSION
/STATISTICS R
/DEPENDENT log_income
/METHOD = ENTER edu_year.
- 结果解读:
- 皮尔逊相关系数 (r):
r = 0.449。这是一个中等强度的正相关。 - 显著性 (Sig. 2-tailed):p值为
.000,远小于0.05。这表明我们观察到的这种相关性是统计上显著的。
- 皮尔逊相关系数 (r):
辅助知识点:相关不等于因果,更不等于“解释力” 一个常见的重大误区是直接将相关系数
r理解为“解释力”。r = 0.449不等于 “教育年限解释了44.9%的收入”。正确的解释力指标是决定系数 R² (R-Squared),即相关系数的平方。
在本例中,
R² = (0.449)² ≈ 0.202。这意味着,教育年限的变异,可以解释对数收入变异的约20.2%。剩下的近80%则是由其他未被模型包含的因素(如行业、经验、性别等)所解释。R²是我们评价回归模型拟合优度的核心指标。
4.简单线性回归分析
- 回归分析比相关分析更进一步。它不再仅仅描述关系,而是试图建立一个预测模型,并量化自变量对因变量的影响程度。
- 简单线性回归模型: $$ \hat{Y} = b_0 + b_1 X $$
Ŷ: 因变量的预测值 (Predicted value),这里是log_income。X: 自变量 (Independent variable),这里是edu_year。b₀: 截距 (Intercept/Constant),当X=0时,Y的预测值。b₁: 斜率 (Slope),X每增加一个单位,Y的预测值平均会发生多大的变化。这是我们最关心的系数。
(4)回归系数的点估计
- 点选操作:分析 → 回归 → 线性 → 从变量列表选中“因变量”和“自变量”并移入对应框 → 点击“统计” → 勾选“回归系数”的“估算值” → 继续 → 确定
- 点选操作:参见本讲第2节
案例(4-1):用教育年限回归对数收入
- 第一种方法:根据最小二乘法的统计公式计算
/* b1 = Cov(X,Y) / Var(X) */
/* b0 = Mean(Y) - b1 * Mean(X) */
COMPUTE beta_1 = income_edu_cov / (edu_year_sd**2).
COMPUTE beta_0 = log_income_mean - beta_1 * edu_year_mean.
FORMATS beta_0 beta_1 (f20.16).
SUMMARIZE
/TABLES = beta_0 beta_1
/FORMAT = VALIDLIST LIMIT=1.
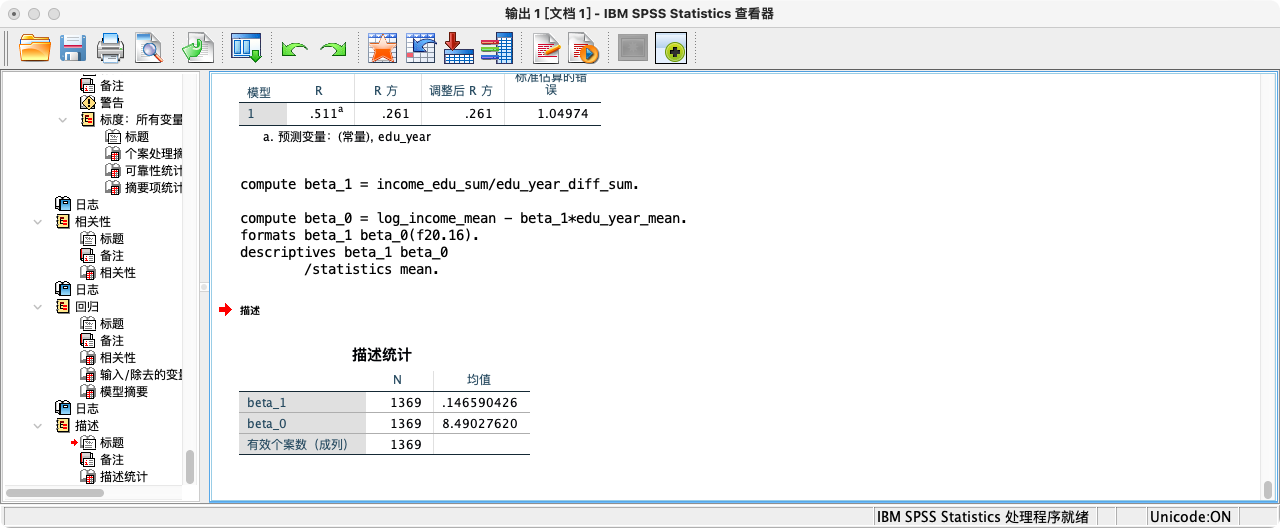
- 第二种方法:采用“线性回归”功能
REGRESSION
/STATISTICS COEFF
/DEPENDENT log_income
/METHOD = ENTER edu_year.
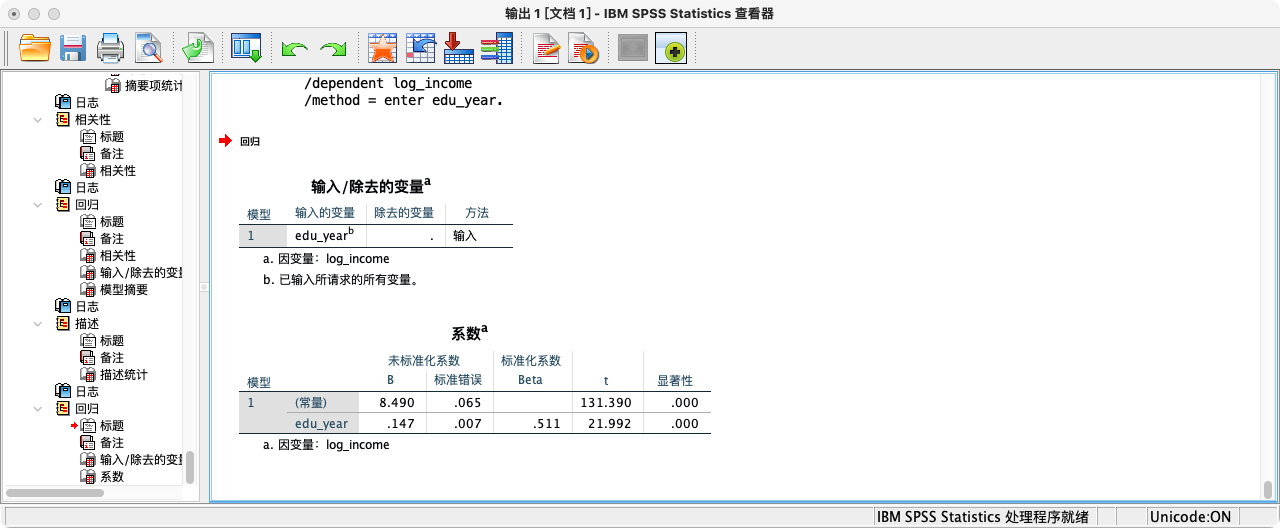
- 回归方程:
预测的log_income = 8.653 + 0.126 * edu_year。 - 系数解释:在其他条件不变的情况下,教育年限每增加一年,我们预测其对数收入平均会增加0.126。
(2)回归系数的区间估计
- 点选操作:分析 → 回归 → 线性 → 从变量列表选中“因变量”和“自变量”并移入对应框 → 点击“统计” → 勾选“回归系数”的“置信区间” → 填入“置信区间” → 继续 → 确定
案例(4-2):计算回归系数的95%置信区间
- 第一种方法:根据统计公式手动计算
- 回归系数b1的95%置信区间
/* 这是一个复杂的过程,涉及计算残差平方和(SSE)和标准误(SE) */
COMPUTE log_income_hat = beta_0 + beta_1*edu_year.
COMPUTE residual = log_income - log_income_hat.
COMPUTE residual_sq = residual**2.
AGGREGATE
/SSE = SUM(residual_sq).
* 计算模型方差和b1的标准误.
COMPUTE model_var = SSE / (1369 - 2).
COMPUTE edu_year_diff_sq = (edu_year-edu_year_mean)**2.
AGGREGATE
/edu_year_diff_sum=SUM(edu_year_diff_sq).
COMPUTE beta_1_se = SQRT(model_var/edu_year_diff_sum).
* 计算b1的置信区间.
COMPUTE beta_1_lower = beta_1 - 1.96 * beta_1_se. /* 1.96为95%CI的Z值 */
COMPUTE beta_1_upper = beta_1 + 1.96 * beta_1_se.
FORMATS beta_1 beta_1_se beta_1_lower beta_1_upper (f20.16).
SUMMARIZE
/TABLES = beta_1 beta_1_se beta_1_lower beta_1_upper
/FORMAT = VALIDLIST LIMIT=1.
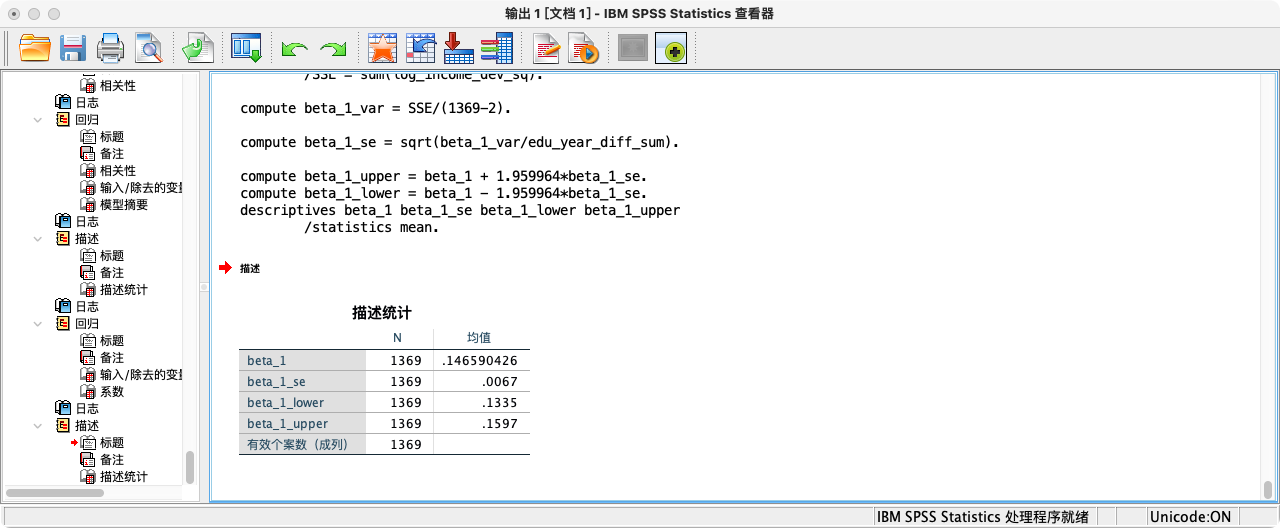
- 回归系数b0的95%置信区间
COMPUTE edu_year_sq = edu_year**2.
AGGREGATE
/edu_year_sq_sum = SUM(edu_year_sq).
COMPUTE beta_0_se = SQRT((edu_year_sq_sum*model_var)/(1369*edu_year_diff_sum)).
* 95%的置信区间下,β_0的区间估计值.
COMPUTE beta_0_upper = beta_0 + 1.959964*beta_0_se.
COMPUTE beta_0_lower = beta_0 - 1.959964*beta_0_se.
FORMATS beta_1 beta_1_se beta_1_lower beta_1_upper beta_0 beta_0_se beta_0_lower beta_0_upper (F20.16).
SUMMARIZE
/TABLES = beta_0 beta_0_se beta_0_lower beta_0_upper
/FORMAT = VALIDLIST LIMIT=1.
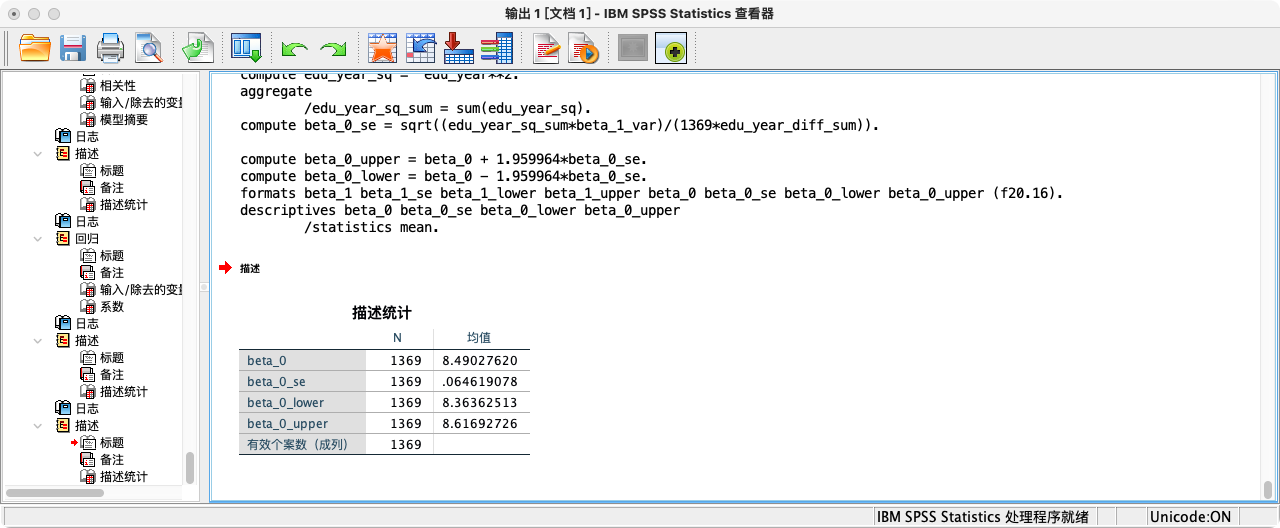
- 第二种方法:采用“线性回归”功能 (推荐)
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD = ENTER edu_year.
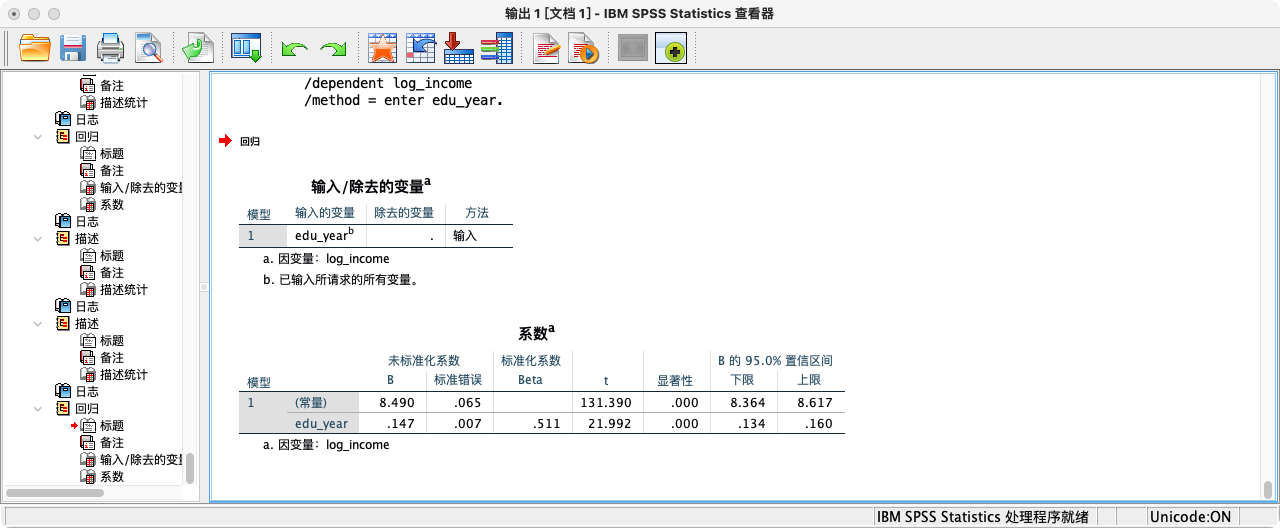
- 解释:
edu_year系数的95%置信区间为 [0.115, 0.137]。我们有95%的信心认为,真实的总体斜率β₁落在这个区间内。由于这个区间完全不包含0,这为我们“教育年限对收入有显著影响”的结论提供了更强的支持。
(3)拟合优度 (R²)
- 点选操作:分析→回归→线性→…→“统计”对话框默认勾选“模型拟合”。
案例(4-3):计算回归模型的拟合优度
- 第一种方法:根据统计公式计算
/* R_squared = SSR / SST, SST = Σ(y-ȳ)², SSR = Σ(ŷ-ȳ)² */
COMPUTE SST = log_income_diff_sum.
COMPUTE log_income_hat_diff = log_income_hat - log_income_mean.
COMPUTE log_income_hat_diff_sq = log_income_hat_diff**2.
AGGREGATE
/SSR = SUM(log_income_hat_diff_sq).
COMPUTE R_2 = SSR / SST.
FORMATS SST SSE SSR R_2 (F20.16).
SUMMARIZE
/TABLES = SST SSE SSR R_2
/FORMAT = VALIDLIST LIMIT=1.
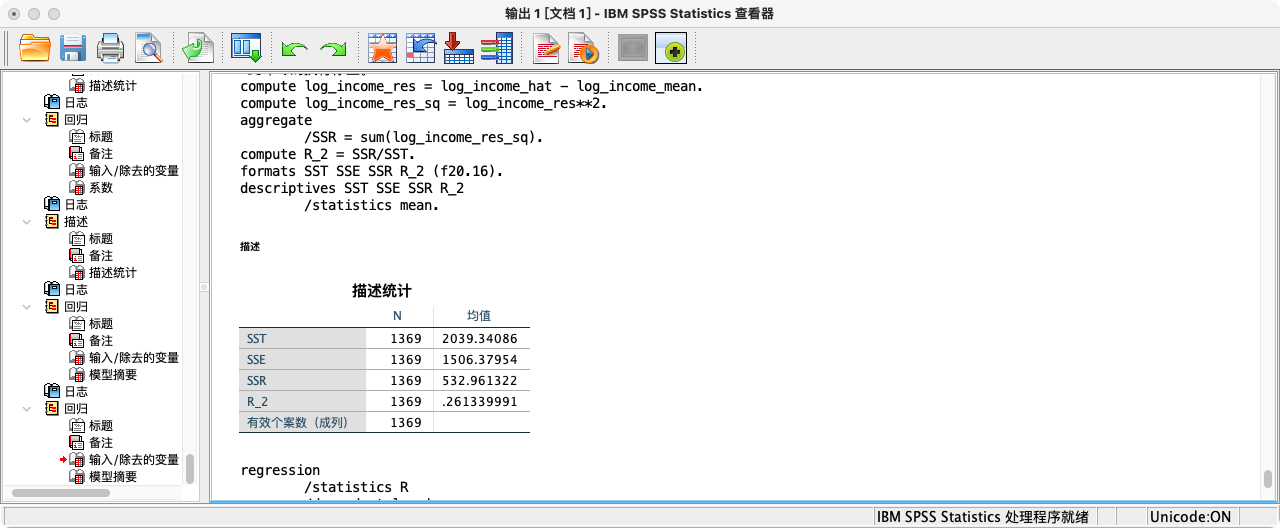
- 第二种方法:采用“线性回归”功能
REGRESSION
/STATISTICS R
/DEPENDENT log_income
/METHOD = ENTER edu_year.
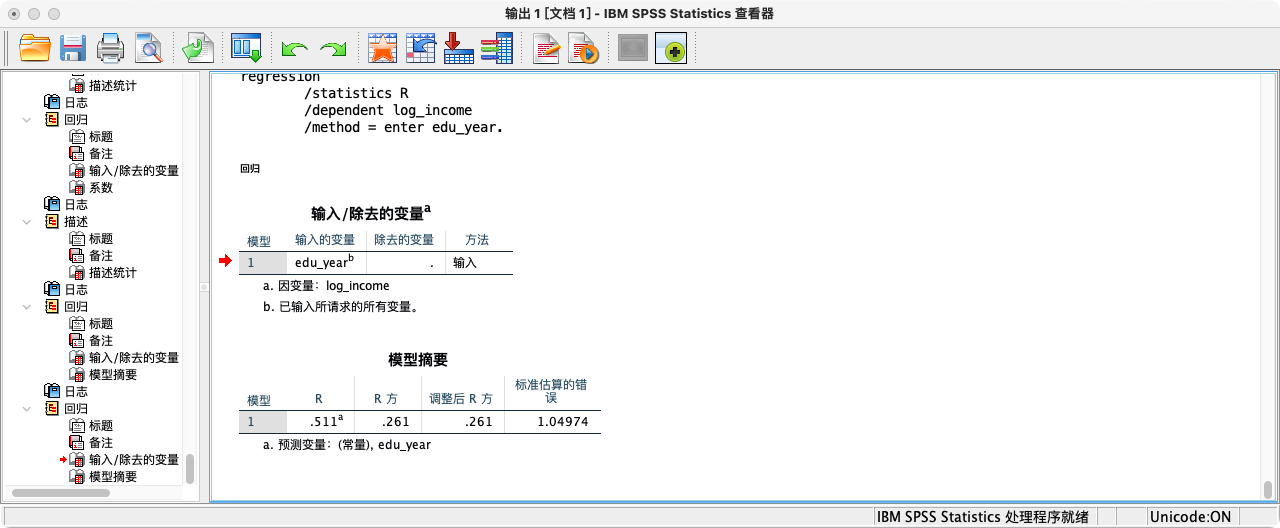
- 解读:“Model Summary”表中的**R Square (R²)**值为 0.202。
(4)回归系数的假设检验
- 点选操作:分析→回归→线性→…→默认输出中包含系数检验结果。
案例(4-4):对回归系数值进行假设检验
- 检验
b₁(edu_year的系数):- H₀ (虚无假设):
β₁ = 0(教育年限对收入没有线性影响)。 - H₀ (虚无假设):
βₒ = 0。 - H₁ (研究假设):
β₁ ≠ 0。 - H₁ (研究假设):
βₒ ≠ 0。
- H₀ (虚无假设):
- 第一种方法:根据统计公式计算
/* t = b1 / SE(b1) */
COMPUTE beta_1_t = beta_1 / beta_1_se.
COMPUTE beta_0_t = beta_0 / beta_0_se.
FORMATS beta_1_t beta_0_t (F20.16).
SUMMARIZE
/TABLES = beta_1_t beta_0_t
/FORMAT = VALIDLIST LIMIT=1.
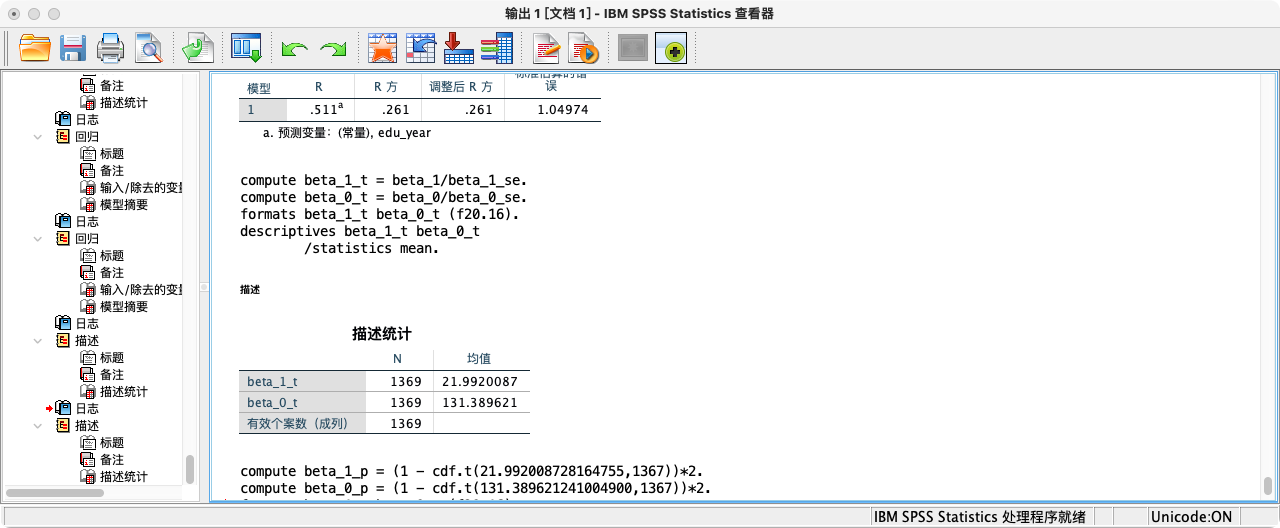
/* p-value */
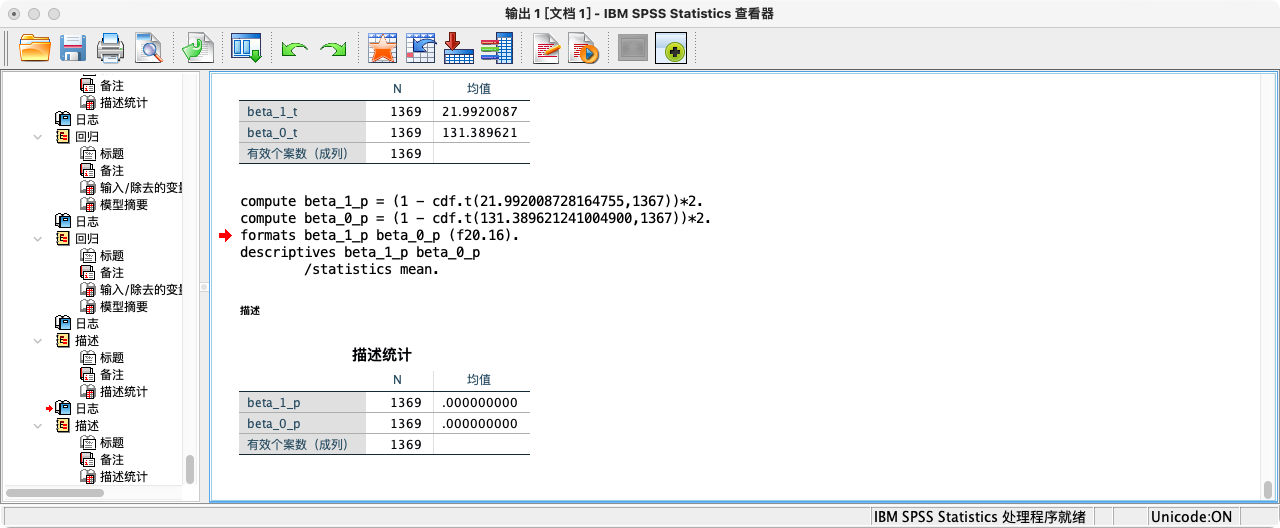
COMPUTE beta_1_p = 2 * (1 - CDF.T(ABS(beta_1_t), 1369-2)).
COMPUTE beta_0_p = 2 * (1 - CDF.T(ABS(beta_0_t), 1369-2)).
FORMATS beta_1_p beta_0_p (F20.16).
SUMMARIZE
/TABLES = beta_1_p beta_0_p
/FORMAT = VALIDLIST LIMIT=1.
- 第二种方法:采用“线性回归”功能
REGRESSION
/STATISTICS COEFF
/DEPENDENT log_income
/METHOD = ENTER edu_year.
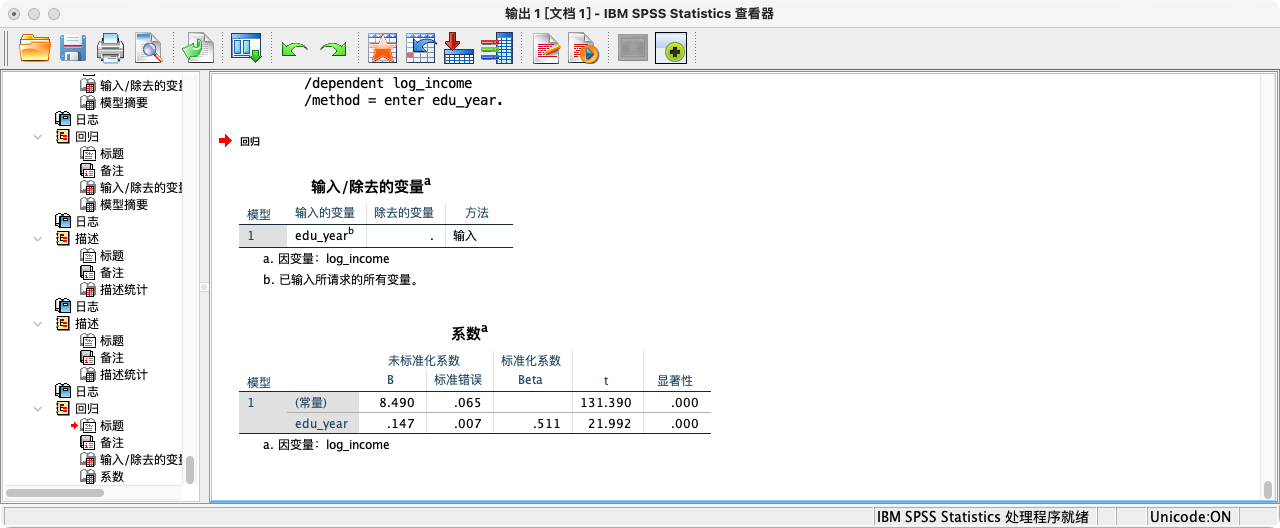
- 结果解读:关注
edu_year这一行,Sig.值为.000,远小于0.05。我们强烈拒绝虚无假设,认为教育年限对对数收入存在显著的、正向的线性影响。
Disqus comments are disabled.