第十二讲 多元回归分析
Last updated: Sep 18, 2025
导论:从简单回归到多元回归
辅助知识点: 在上一讲中,我们学习了简单线性回归,即用一个自变量来解释和预测因变量。然而,现实世界中的社会现象远比这复杂,一个结果往往是多个因素共同作用的结果。例如,个人收入不仅与教育水平有关,还可能受到年龄(经验)、性别、行业等多种因素的影响。
多元回归分析 (Multiple Regression Analysis) 正是处理这种多因素影响的强大工具。它允许我们在一个模型中同时放入多个自变量,从而实现两个核心目标:
- 更准确的预测:通过综合考虑多个相关因素,模型对因变量的预测能力通常会比简单回归更强。
- 更纯粹的解释:多元回归能够估算出每个自变量在 “控制”了其他自变量影响之后,对因变量的 “净效应” (net effect)。这是社会科学研究中探寻因果关系、排除混淆变量的关键一步。
0. 预处理
- 设置工作目录
CD "/Users/ginglam/Public/data".
- 导入2016年中国劳动力动态调查数据
GET FILE "clds2016_i.sav".
DATASET NAME clds.
DATASET ACTIVATE clds.
1. 多元回归分析的基本操作
- 点选操作:分析 → 回归 → 线性 → 将因变量放入“因变量”框 → 将两个或多个自变量放入“自变量”框 → 点击“统计”,勾选“估算值”和“置信区间”等所需选项 → 继续 → 确定。
- 语法操作:
REGRESSION命令的结构与简单回归基本相同,只需在/METHOD子命令后列出所有自变量即可。具体参见第十一讲。
案例(1-1):探索2015年总收入的影响因素
- 第一步:数据准备
- 筛选有效个案,并创建分析所需的变量:总收入(对数)、年龄、教育年限。
SELECT IF (I3a_6 > 0).
COMPUTE log_income = LN(I3a_6).
SELECT IF (birthyear > 0).
COMPUTE age = 2015 - birthyear.
SELECT IF (I2_1 > 0).
RECODE I2_1 (1=0) (2=6) (3=9) (4 THRU 7=12)
(8=15) (9=16) (10=19) (11=22) (ELSE=SYSMIS)
INTO edu_year.
EXECUTE.
- 第二步:构建并运行多元回归模型
- 我们将同时考察年龄(
age)和教育年限(edu_year)对对数收入(log_income)的影响。
- 我们将同时考察年龄(
REGRESSION
/STATISTICS COEFF CI(95) R ANOVA
/DEPENDENT log_income
/METHOD = ENTER age edu_year.
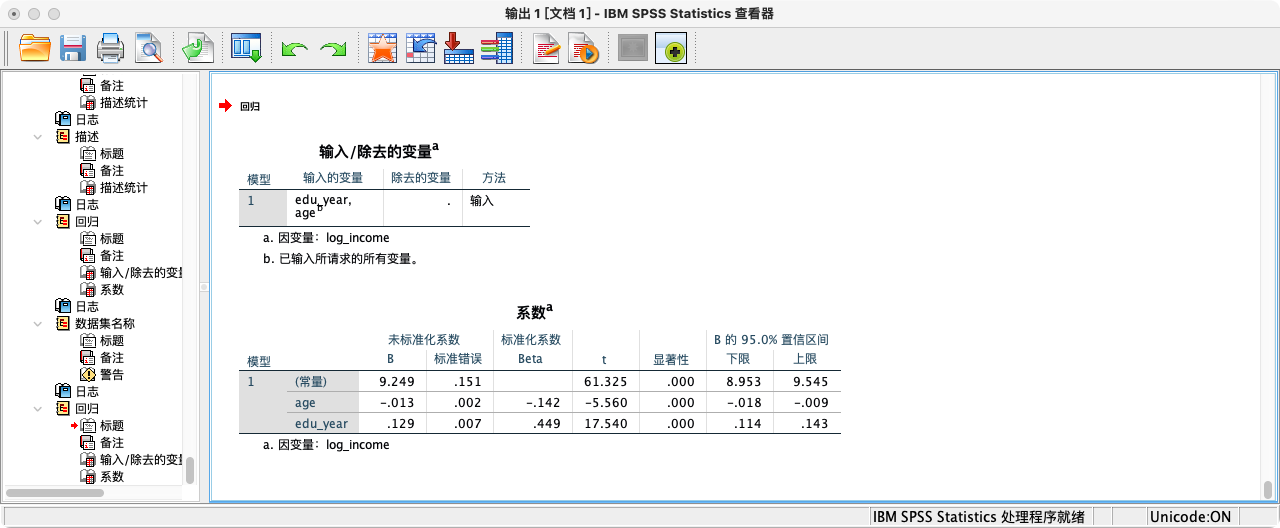
- 结果解读:
- 在“系数”表中,
age的系数为-0.013,edu_year的系数为0.129,且两者的Sig.值均为.000。这表明在相互控制后,年龄对收入有显著的负向影响,教育年限对收入有显著的正向影响。
- 在“系数”表中,
- 系数解释:
- 在控制了教育年限不变的情况下,年龄每增加1岁,对数收入平均减少0.013,即收入平均减少约1.3%。
- 在控制了年龄不变的情况下,教育年限每增加1年,对数收入平均增加0.129。
随堂练习:探索生活幸福感 (I7_6_1) 的影响因素
- 提示:构建一个多元回归模型,将年龄、教育年限和收入水平作为自变量,来解释生活幸福感。
2.回归分析的前提假设
辅助知识点:为何要考察前提假设?
普通最小二乘法(OLS)回归要想得到准确、可靠且有效的估计结果(即所谓的“最佳线性无偏估计”,BLUE),其背后的数据需要满足一系列统计假设。如果这些假设被严重违背,那么我们得到的回归系数和显著性检验结果就可能是误导性的。因此,在报告最终模型之前,进行必要的诊断检验是严谨研究的必备环节。
2.1 检验残差的独立性:Durbin-Watson检验
- 假设:残差项之间应该相互独立,不存在自相关(特别是对于时间序列数据)。
- 检验方法:Durbin-Watson (DW) 统计量。
- 规则:DW值的取值范围在0-4之间。值越接近2,越表明残差是独立的。通常认为,1.5到2.5之间的值都是可以接受的。
- 点选操作:分析 → 回归 → 线性 → 从变量列表选中“因变量”及两个或多个“自变量”并移入对应框 → 点击“统计” → 在“残差”项勾选“德宾-沃森” → 继续 → 确定
- 语法操作:
REGRESSION
/DEPENDENT log_income
/METHOD = ENTER age edu_year
/RESIDUALS DURBIN.
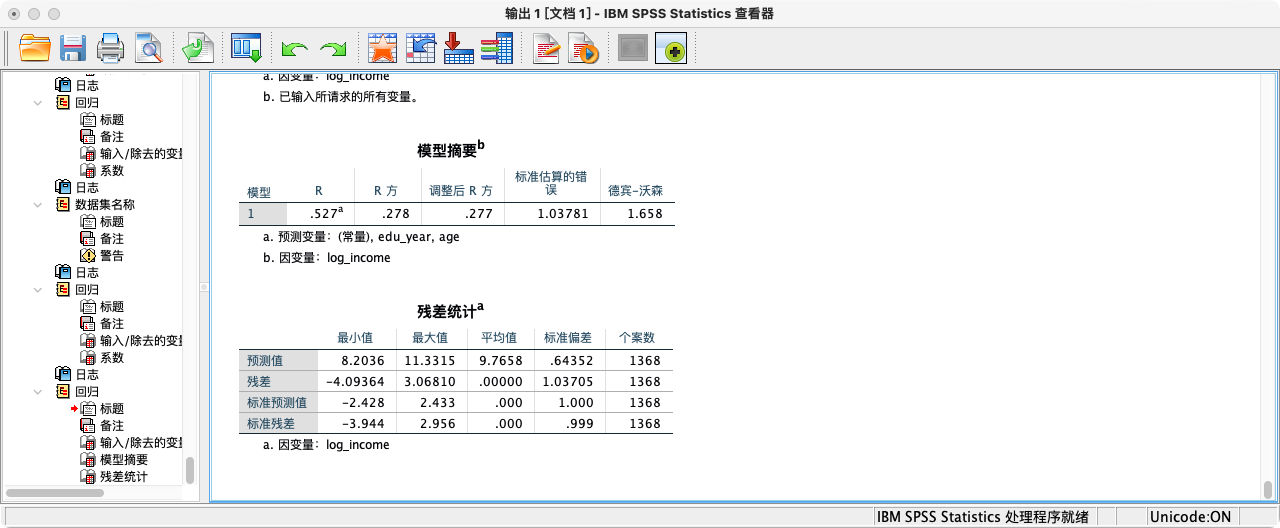
- 解读:模型摘要表中的Durbin-Watson值为1.658,在可接受的范围内,我们可以认为残差独立性假设基本满足。
2.2 检验方差齐性 (Homoscedasticity)
- 假设:残差的方差应该是一个常数,不应随着预测值的变化而系统性地变化。如果方差不齐(异方差性),则高估了模型的精度。
- 检验方法:绘制“标准化残差”对“标准化预测值”的散点图。
- 规则:如果满足方差齐性,散点图中的点应该像一团形状规则、随机分布的“云”,没有明显的模式(如喇叭形、曲线形)。
- 点选操作:分析 → 回归 → 线性 → 从变量列表选中“因变量”及两个或多个“自变量”并移入对应框 → 点击“图” → 将
*ZRESID(标准化残差)放入“Y”框,将*ZPRED(标准化预测值)放入“X”框 → 继续 → 确定。 - 语法操作:
REGRESSION
/DEPENDENT log_income
/METHOD = ENTER age edu_year
/SCATTERPLOT=(*ZRESID, *ZPRED).
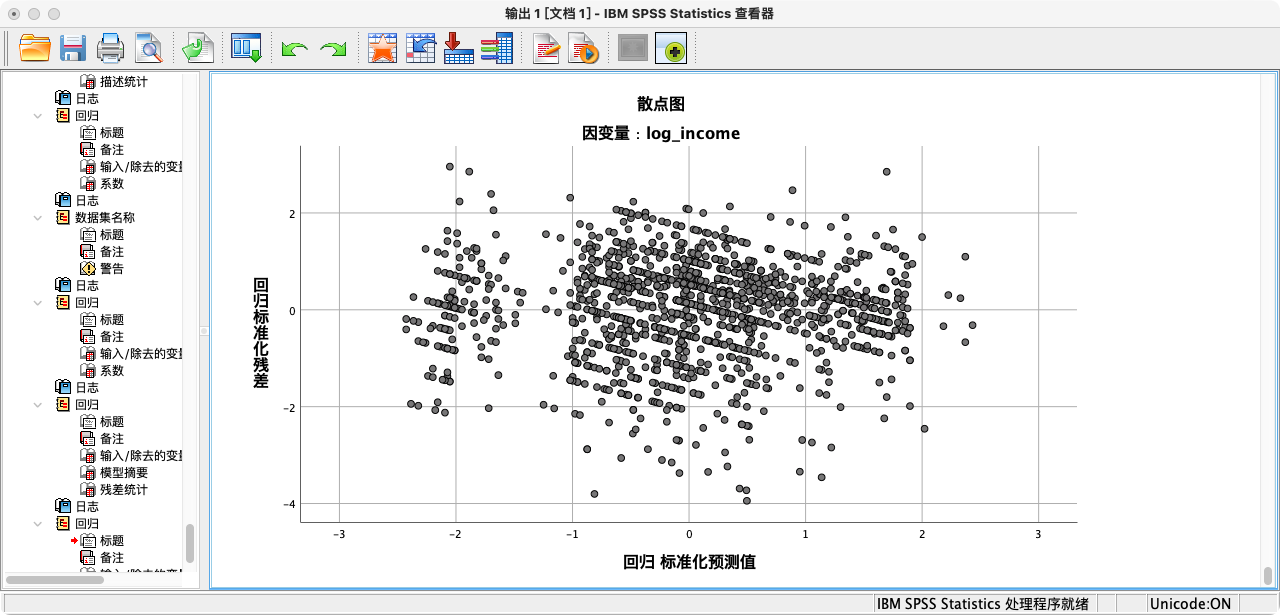
- 解读:从残差散点图来看,数据点大致均匀地分布在0线两侧,没有呈现出明显的喇叭口或曲线模式。因此,可以认为该回归模型满足同方差性假设。
3. 理解控制变量(control variable)的本质
辅助知识点:什么是“控制”? 在多元回归中,“控制”一个变量(如年龄),其统计学本质是 “剔除”或“剥离”掉其他变量(如教育和收入)中与这个控制变量相关的部分,然后再考察剩余的“纯净”部分之间的关系。
例如,我们知道年龄和教育通常是相关的(年长者平均受教育年限可能较低)。当我们想知道教育对收入的纯粹影响时,我们就需要先从教育和收入这两个变量中,各自“抽掉”能被年龄解释的部分,然后用“纯净的教育”去解释“纯净的收入”。这正是多元回归在后台为我们做的事情。
案例(3-1):通过分步回归理解控制变量的作用
- 第一步:基础模型 (Baseline Model)
- 只包含核心自变量(
edu_year),不加任何控制变量。
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD = ENTER edu_year.
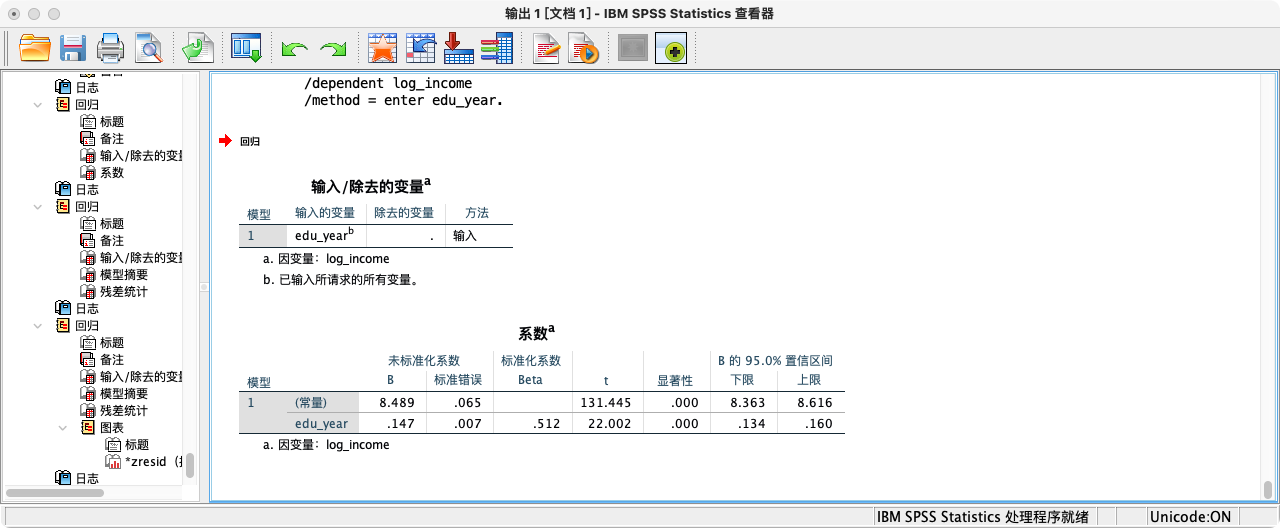
- 第二步:拓展模型 (Full Model)
- 在基础模型中加入控制变量(
age)。
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD = ENTER edu_year age.
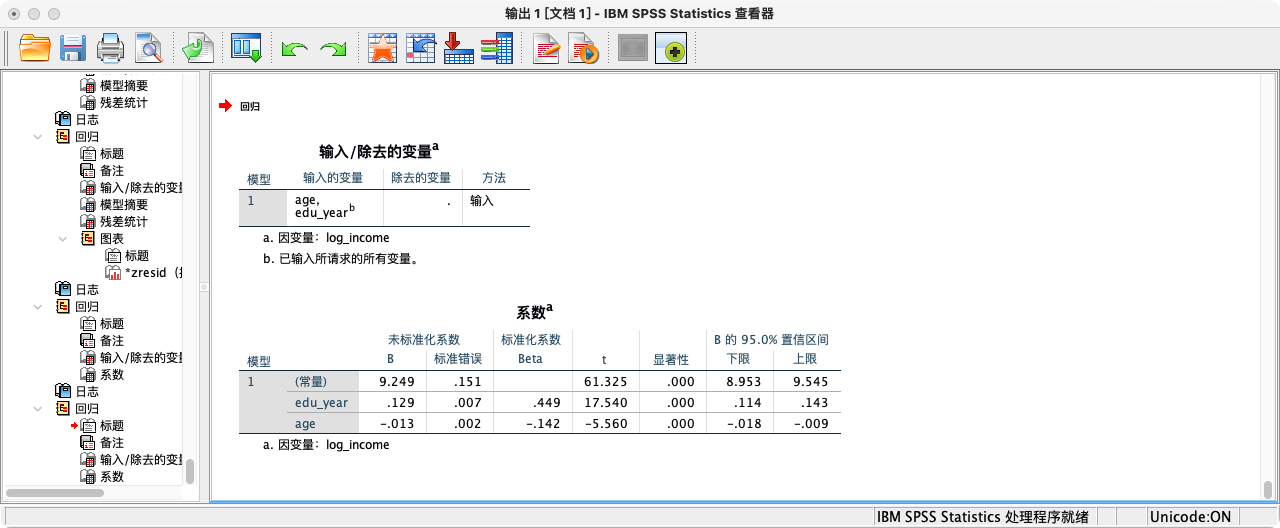
-
比较与解读:
- 在基础模型中,
edu_year的系数是0.147。 - 在加入了
age作为控制变量的拓展模型中,edu_year的系数变为0.129。 - 系数的变化说明,原先
edu_year对log_income的影响中,有一小部分(0.147 - 0.129 = 0.018)是和age重叠的。控制了年龄后,我们得到了一个更“纯净”的教育回报率。
- 在基础模型中,
-
同时呈现嵌套模型 (层次回归)
REGRESSION
/STATISTICS COEFF CI(95) R ANOVA
/DEPENDENT log_income
/METHOD = ENTER edu_year /* 模型1 */
/METHOD = ENTER edu_year age /* 模型2 (在模型1基础上加入age) */.
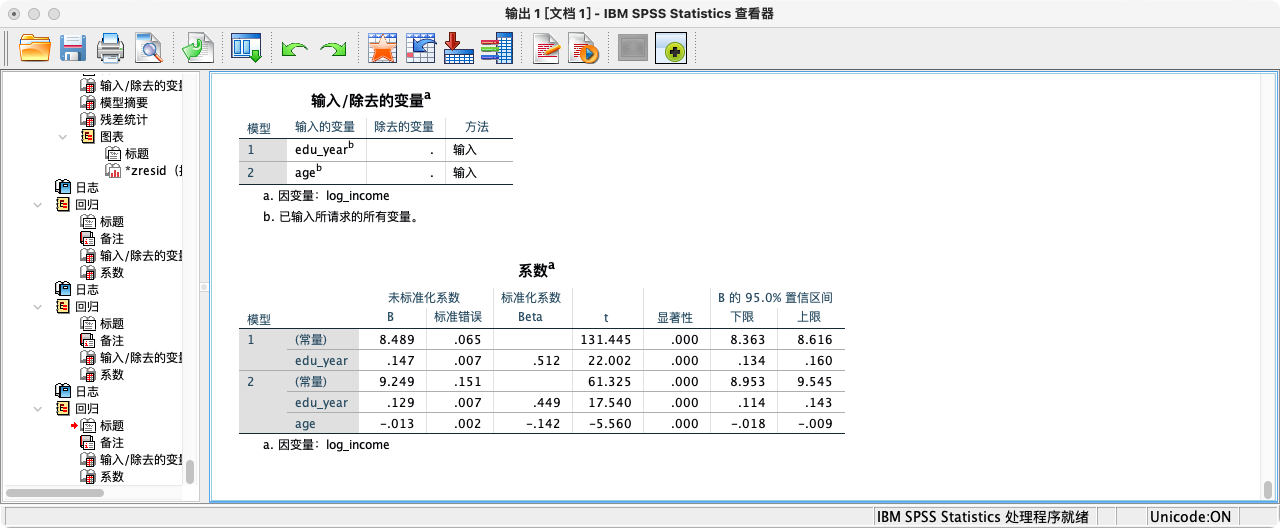
- 重点:手动验证“控制”的过程
- 第一种方式:控制共同因素
- 用年龄回归教育,得到教育中能被年龄解释的部分
edu_year_pred。 - 这样做的理由,是用年龄预测教育年限,其预测结果本质上是包含两者“线性相依性”的变量。
REGRESSION
/DEPENDENT edu_year
/METHOD = ENTER age.
/* 从回归结果中得到截距15.209, 年龄系数-0.144 */
COMPUTE edu_year_pred = (-0.144291*age)+15.209316.
EXECUTE.
- 用教育和
edu_year_pred同时回归收入,此时edu_year的系数就代表了剔除年龄共同影响后的效果。
REGRESSION
/DEPENDENT log_income
/METHOD = ENTER edu_year edu_year_pred.
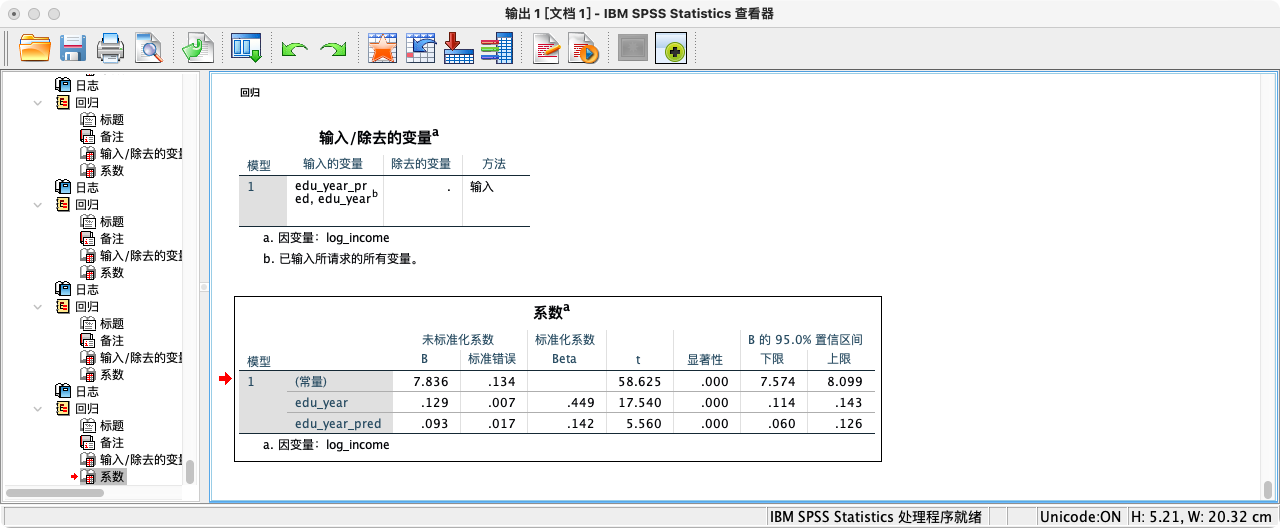
- 第二种方式:使用残差进行回归 (Frisch-Waugh-Lovell 定理)
- 分别用年龄回归收入和教育,得到各自的残差(即不能被年龄解释的部分)。
- 这样做的理由,是用年龄预测收入,并将实际收入与预测收入之差,作为排除年龄作用的结果。
* 1. 计算收入中不能被年龄解释的部分.
REGRESSION
/DEPENDENT log_income
/METHOD = ENTER age.
/* 从回归结果中得到截距11.206, 年龄系数-0.032*/
/* 实际收入与预测收入之差,为收入的残差项*/
COMPUTE log_income_resid = log_income - (11.206 - 0.032*age).
* 2. 计算教育中不能被年龄解释的部分.
/* edu_year_pred 已在上一步计算 */
COMPUTE edu_year_resid = edu_year - edu_year_pred.
EXECUTE.
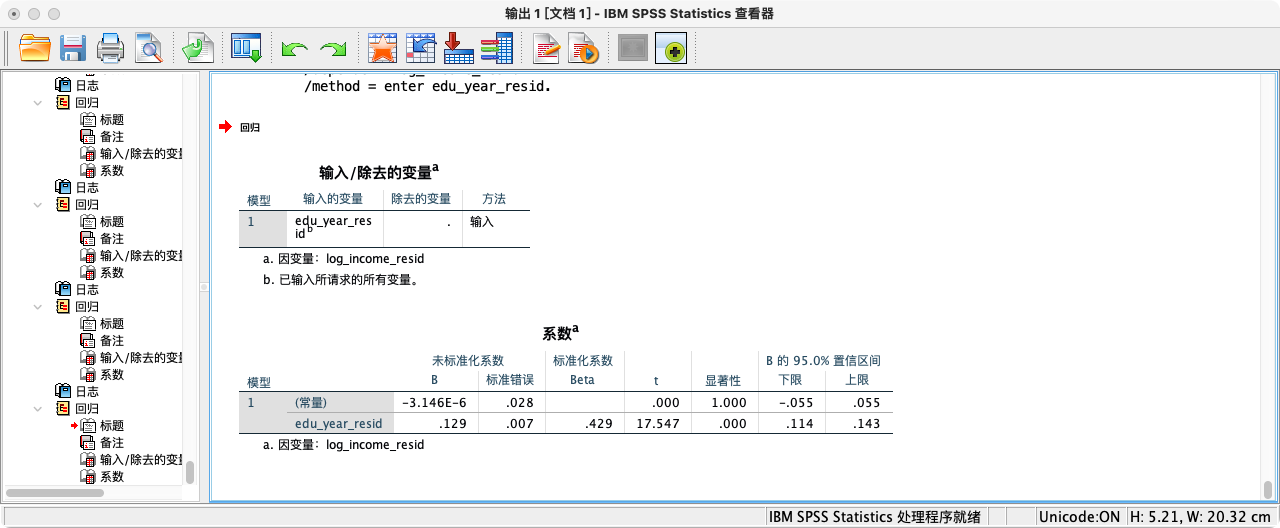
* 3.用“纯净的教育”(`edu_year_resid`)回归“纯净的收入”(`log_income_resid`),得到的系数与多元回归中`edu_year`的系数完全一致.
REGRESSION
/DEPENDENT log_income_resid
/METHOD = ENTER edu_year_resid.
4. 处理自变量与因变量的非线性关系
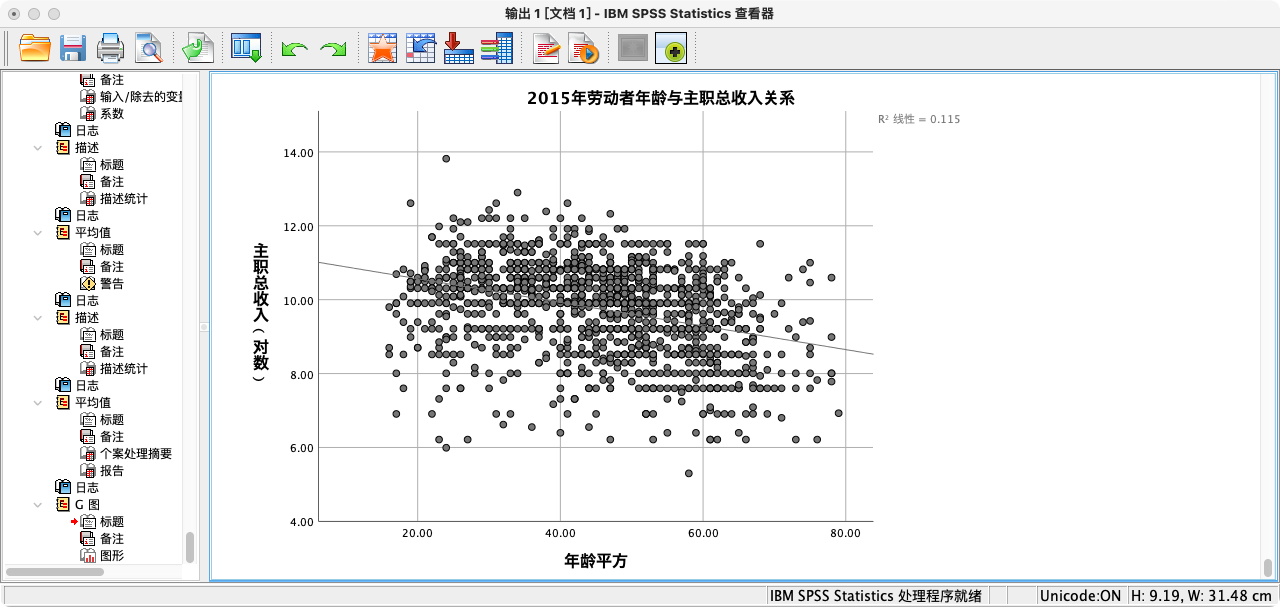
- 核心思想:现实中,自变量与因变量的关系未必是简单的直线。例如,收入随年龄的增长可能呈现“先快速上升,达到顶峰后缓慢下降”的倒U形曲线。
- 处理方法:在回归模型中加入自变量的二次项(平方项)。
案例(4-1):探索总收入与年龄的非线性关系
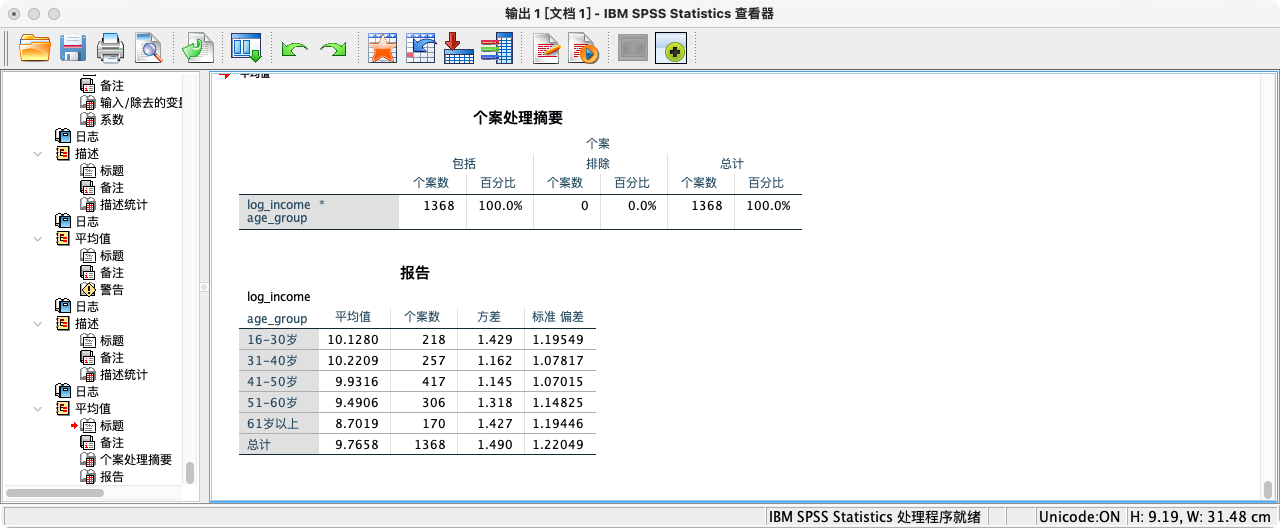
- (1)分组描述统计。按年龄分组查看平均收入,可以初步发现倒U形趋势。
RECODE age (16 THRU 30=1)(31 THRU 40=2)(41 THRU 50=3)(51 THRU 60=4)(61 THRU HI=5) INTO age_group.
VALUE LABELS age_group 1 "16-30岁" 2 "31-40岁" 3 "41-50岁" 4 "51-60岁" 5 "61岁以上".
MEANS log_income BY age_group
/CELLS = MEAN COUNT VAR STDDEV.
- (2)绘制散点图和拟合线。利用图表构建器绘制散点图和拟合线。
GGRAPH
/GRAPHDATASET NAME = "clds" VARIABLES = age log_income
/GRAPHSPEC SOURCE = INLINE
/FITLINE TOTAL = YES.
BEGIN GPL
SOURCE: clds = userSource(id("clds"))
DATA: age=col(source(clds), name("age"))
DATA: log_income=col(source(clds), name("log_income"))
GUIDE: axis(dim(1), label("年龄平方"))
GUIDE: axis(dim(2), label("总收入(对数)"))
GUIDE: text.title(label("2015年劳动者年龄与总收入关系"))
ELEMENT: point(position(age*log_income))
END GPL.
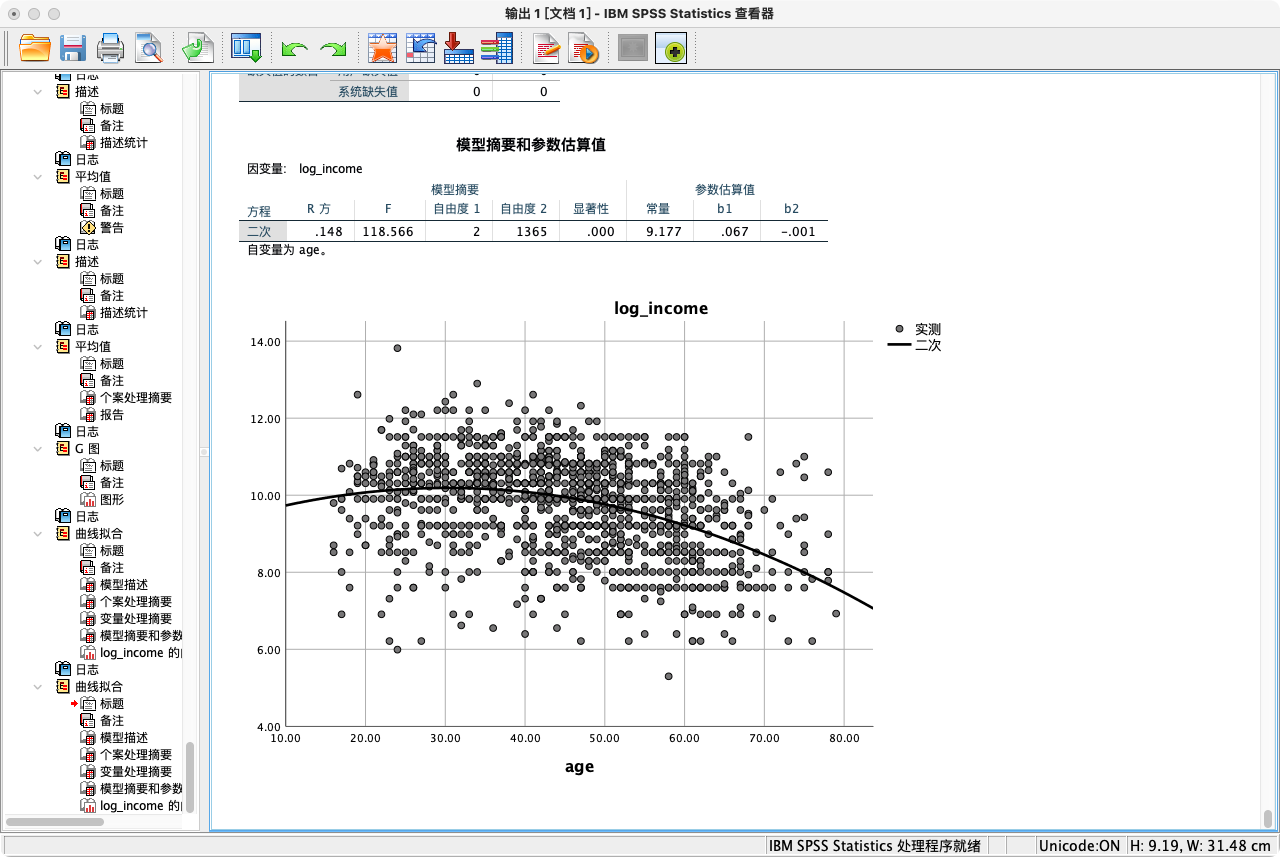
- (3)通过曲线估算功能。直观地比较线性和二次曲线的拟合效果。
- 点选操作:分析 → 回归 → 曲线估算 → 从变量列表选中“因变量”并移入“因变量”框 → 从变量列表选中“自变量”并移入“独立变量”框 → 在模型中勾选“线性”或“二次”等 → 确定。
- 语法操作:
CURVEFIT
/VARIABLES = log_income WITH age
/CONSTANT
/MODEL = LINEAR QUADRATIC
/PLOT FIT.
-
解读:比较模型摘要表,二次模型的R²更高,说明曲线拟合得更好。
-
在回归模型中实现
-
第一步:构建包含年龄一次项和二次项的模型
COMPUTE age_sq = age**2.
REGRESSION
/STATISTICS COEFF
/DEPENDENT log_income
/METHOD = ENTER age age_sq.
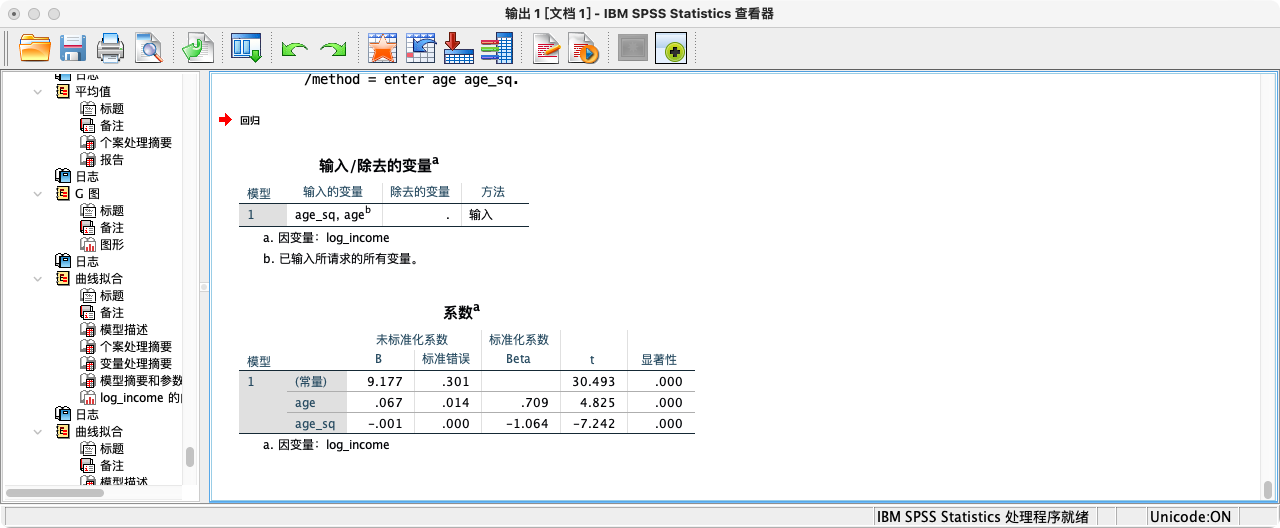
- 解读:模型中,
age的系数为正,age_sq的系数为负,这正是倒U形曲线的数学特征。 - 第二步:计算收入达到峰值的年龄拐点
- 拐点公式:
-b₁ / (2 * b₂),其中b₁是一次项系数,b₂是二次项系数。
COMPUTE turn_point = -(0.066585 / (2 * -0.001099)).
FORMATS turn_point (F20.16).
SUMMARIZE
/TABLES = turn_point
/FORMAT = VALIDLIST LIMIT=1.
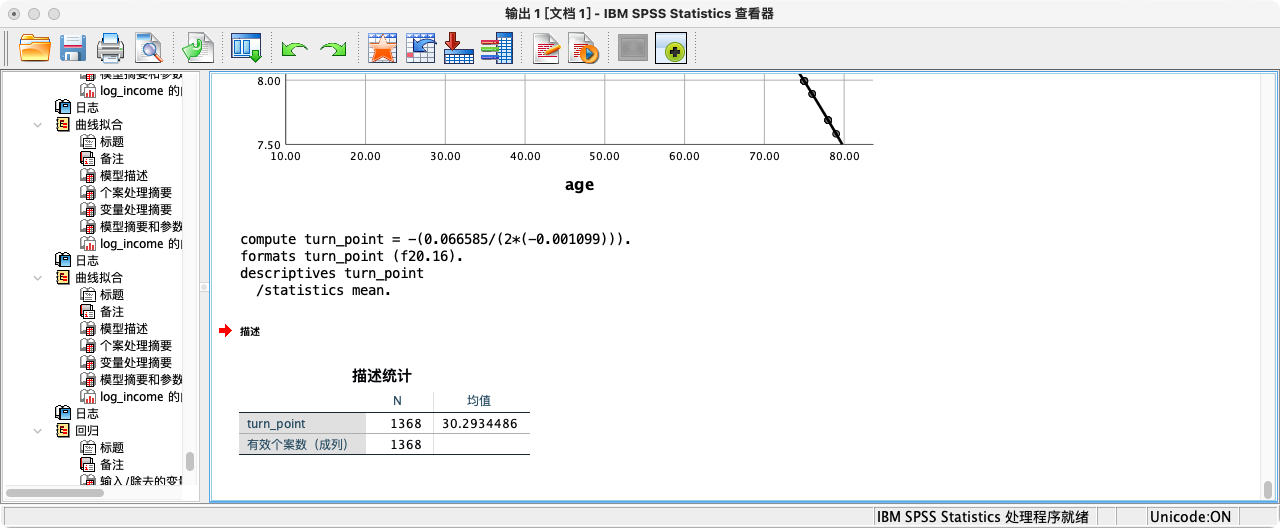
- 结论:根据模型,劳动者的收入大约在30.3岁时达到峰值。
5. 处理定类和定序自变量
-
核心思想:回归模型要求自变量是数值型的,但社会科学中充满了分类变量(如性别、学历、地区)。我们需要将它们转换为虚拟变量 (Dummy Variables) 才能放入模型。
-
虚拟变量:一个只有0和1两种取值的变量。通常,1代表“具有某种属性”,0代表“不具有”。
-
当自变量是二分定类变量时
案例(5-1):探索大学学历对收入的影响
* 第一步:构造一个“是否上过大学”的虚拟变量.
RECODE I2_1 (1 THRU 7=0) (8 THRU HI=1) INTO be_college.
VALUE LABELS be_college 0 "非大学学历" 1 "大学及以上学历".
* 第二步:将虚拟变量放入回归模型.
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD = ENTER be_college age.
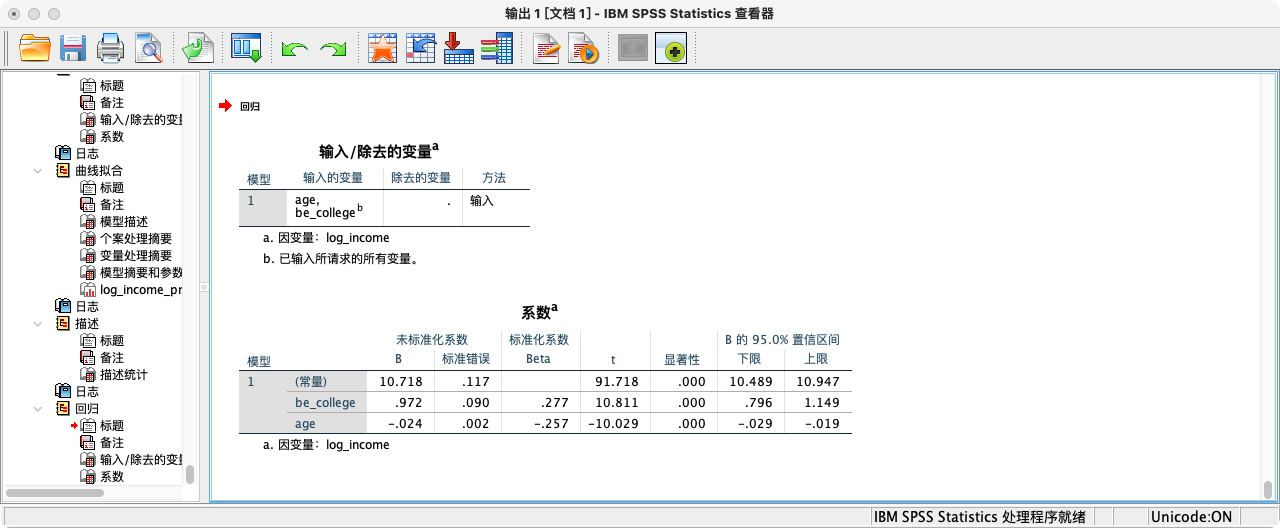
-
解读:
be_college的系数(0.706)表示,在控制了年龄后,拥有大学及以上学历的人,其对数收入平均比非大学学历的人高0.706。 -
当自变量是多分类定序/定类变量时
案例(5-2):探索不同学历阶段对收入的影响
- 规则:如果一个分类变量有k个类别,我们需要创建k-1个虚拟变量。被省略的那个类别将成为参照组 (Reference Group),所有其他组的系数都是与这个参照组相比较的结果。
- 第一步:构造多分类学历变量
RECODE I2_1 (1 THRU 2=1) (3=2) (4 THRU 7=3) (8 THRU HI=4) INTO qualification.
VALUE LABELS qualification 1 "小学及以下" 2 "初中" 3 "高中" 4 "大学及以上".
- 第二步:自动创建虚拟变量 (需要安装Python扩展包中的
CREATE DUMMIES命令)
SPSSINC CREATE DUMMIES VARIABLE = qualification ROOTNAME1=qual.
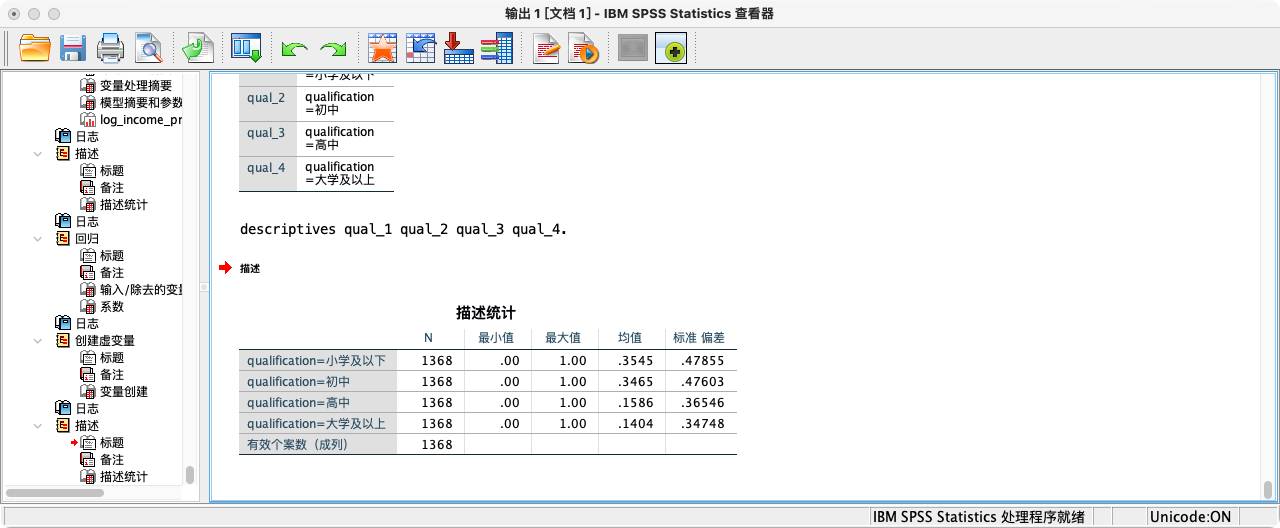
- 该命令会自动生成
qual_1,qual_2,qual_3,qual_4四个虚拟变量。 - 第三步:选择参照组并进行回归
- 我们选择“小学及以下”(
qual_1)作为参照组,因此在模型中放入其余三个虚拟变量。
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD = ENTER qual_2 qual_3 qual_4 age.
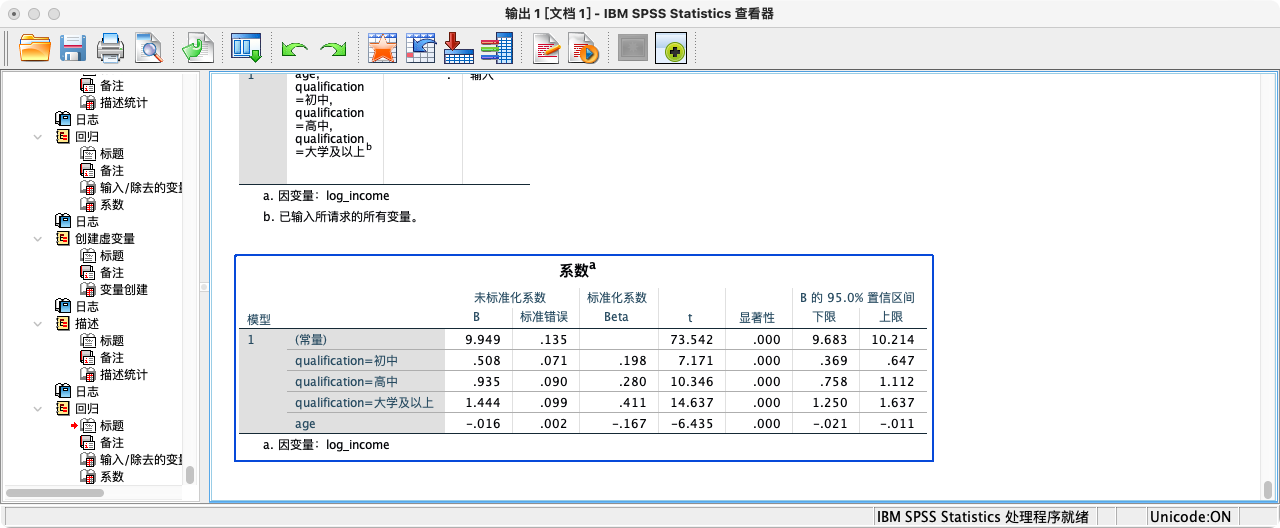
- 解读
qual_2的系数(0.245)表示,控制年龄后,初中学历者的对数收入平均比小学及以下学历者高0.245。qual_3和qual_4的系数也都是与小学及以下这个参照组相比较的结果。
随堂练习:探索生活幸福感(I7_6_1)与教育的关系
- 提示:用多阶段学历衡量教育(以大学及以上学历作为参照组)并作为核心解释变量,以性别、年龄和收入水平作为控制变量
6. 回归模型的标准化系数
辅助知识点:非标准化系数 (B) vs. 标准化系数 (Beta)
- 非标准化系数 (B):是我们之前一直解读的系数。它带有原始单位(例如,“教育每增加一年,收入对数增加0.117”)。它的优点是解释直观,具有现实意义。
- 标准化系数 (Beta, β):是SPSS对所有变量(包括因变量和自变量)进行标准化(转换为均值为0,标准差为1的Z分数)后,再进行回归得到的系数。它没有单位。
- 用途:标准化系数的绝对值大小可以用来比较同一个模型中不同自变量的相对重要性。例如,如果教育的Beta是0.4,年龄的Beta是0.2,我们可以说,在这个模型中,教育对收入的相对影响力大约是年龄的两倍。
- 注意:不能用Beta系数来比较不同模型或不同样本中变量的重要性。
案例(6-1):查看并解读标准化系数
REGRESSION命令默认就会输出标准化系数。
REGRESSION
/STATISTICS COEFF CI(95)
/DEPENDENT log_income
/METHOD=ENTER age edu_year.
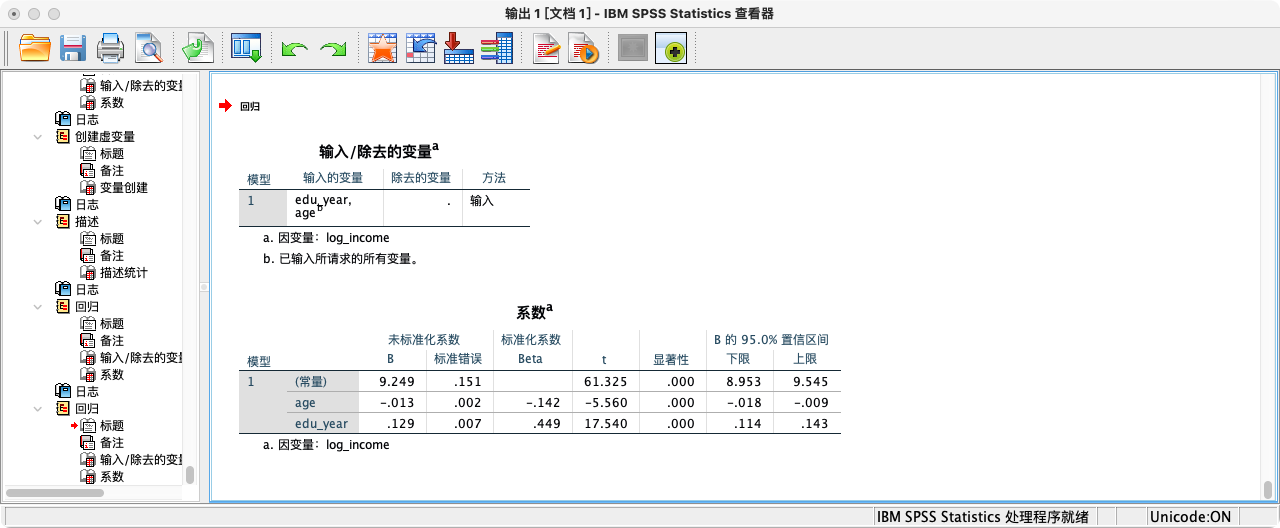
- 解读:在“系数”表中,“标准化系数 Beta”一列:
edu_year的Beta为0.449。age的Beta为-0.142。- 因为 |0.449| > |-0.142|,我们可以得出结论:在这个模型中,教育年限对收入的相对影响力大于年龄。
Disqus comments are disabled.